- 原文地址: https://sebastianraschka.com/pdf/software/mlxtend-latest.pdf
- github:https://github.com/rasbt/mlxtend
- 译者:wong小尧
regressor.StackingRegressor
集成学习中,bagging和boosting可以直接调用,而stacking则需要自己设计调配一下才行,尤其是交叉验证的环节比较麻烦。
之前毕设使用了blending(stacking)融合了多个推荐系统模型,性能提升很小,后来无意中发现了mlxtend这个工具包,里面集成了stacking分类回归模型以及它们的交叉验证的版本。这里转载过来翻译一下。
一般推荐系统中的模型融合会称为blending而不是stacking,这是netfilx price比赛中的论文形成的习惯,但实际上推荐系统中blending融合和stacking没有什么分别,现在一般认为blending的融合是弱化版的stacking,是切分样本集为不相交的子样本然后用各个算法生成结果再融合,并且不适用交叉验证,这种方法不能够最大限度的利用数据,而stacking是得到各个算法训练全样本的结果再用一个元算法融合这些结果,效果会比较好一些,它可以选择使用网格搜索和交叉验证。
mlxtend.regressor 中的StackingRegressor是一种集成学习元回归器。
1 Overview
stacking回归是一种通过元回归器组合多个回归模型的集成学习技术。每个独立的基回归模型在训练时都要使用整个训练集;那么,在集成学习过程中独立的基回归模型的输出作为元特征成为元回归器的输入,元回归器通过拟合这些元特征来组合多个模型。
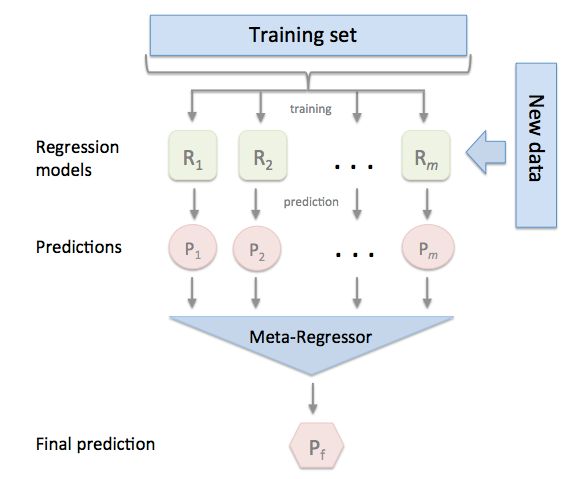
2 Example 1 - Simple Stacked Regression
##数据集使用的是波士顿房价的数据集
from mlxtend.regressor import StackingRegressor
from mlxtend.data import boston_housing_data
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
import matplotlib.pyplot as plt
import numpy as np
# 生成一个样本数据集
np.random.seed(1)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - np.random.rand(8))
# 初始化模型
lr = LinearRegression()
svr_lin = SVR(kernel='linear')
ridge = Ridge(random_state=1)
svr_rbf = SVR(kernel='rbf')
#融合四个模型
stregr = StackingRegressor(regressors=[svr_lin, lr, ridge], meta_regressor=svr_rbf)
# 训练stacking分类器
stregr.fit(X, y)
stregr.predict(X)
# 拟合结果的评估和可视化
print("Mean Squared Error: %.4f" % np.mean((stregr.predict(X) - y) ** 2))
print('Variance Score: %.4f' % stregr.score(X, y))
with plt.style.context(('seaborn-whitegrid')):
plt.scatter(X, y, c='lightgray')
plt.plot(X, stregr.predict(X), c='darkgreen', lw=2)
plt.show()
结果和模型参数
Mean Squared Error: 0.2039
Variance Score: 0.7049
stregr
StackingRegressor(meta_regressor=SVR(C=1.0, cache_size=200, coef0=0.0,
degree=3, epsilon=0.1, gamma='auto',kernel='rbf', max_iter=-1,
shrinking=True, tol=0.001, verbose=False),
regressors=[SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1,
gamma='auto',kernel='linear', max_iter=-1, shrinking=True,
tol=0.001, verbose=False),
LinearRegression(copy_X=True, fit_normalize=False, random_state=1,
solver='auto', tol=0.001)],verbose=0)

3 Example 2 - Stacked Regression and GridSearch
为了给sklearn-learn中的网格搜索设置参数网格,我们在参数网格中提供了学习器的名字,对于元回归器的情况,我们加了“meta-”前缀。
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Lasso
# 初始化模型
lr = LinearRegression()
svr_lin = SVR(kernel='linear')
ridge = Ridge(random_state=1)
lasso = Lasso(random_state=1)
svr_rbf = SVR(kernel='rbf')
regressors = [svr_lin, lr, ridge, lasso]
stregr = StackingRegressor(regressors=regressors,meta_regressor=svr_rbf)
params = {'lasso__alpha': [0.1, 1.0, 10.0],
'ridge__alpha': [0.1, 1.0, 10.0],
'svr__C': [0.1, 1.0, 10.0],
'meta-svr__C': [0.1, 1.0, 10.0, 100.0],
'meta-svr__gamma': [0.1, 1.0, 10.0]}
grid = GridSearchCV(estimator=stregr,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
for params, mean_score, scores in grid.grid_scores_:
print("%0.3f +/- %0.2f %r"
% (mean_score, scores.std() / 2.0, params))
# 拟合结果的评估和可视化
print("Mean Squared Error: %.4f"
% np.mean((grid.predict(X) - y) ** 2))
print('Variance Score: %.4f' % grid.score(X, y))
with plt.style.context(('seaborn-whitegrid')):
plt.scatter(X, y, c='lightgray')
plt.plot(X, grid.predict(X), c='darkgreen', lw=2)
plt.show()
结果
Mean Squared Error: 0.1844
Variance Score: 0.7331

如果我们打算多次使用一个回归算法,我们需要做的就是在参数网格中添加一个额外的数字后缀,如下所示:
4 API
StackingRegressor(regressors, meta_regressor, verbose=0)
A Stacking regressor for scikit-learn estimators for regression.
Parameters
• regressors基回归器 : 类数组型(array-like), shape = [n_regressors]
基回归器列表. 调用StackingRegressor的拟合方法会拟合所有被存在类属性self.regr_中的原始基学习器的复制版。
• meta_regressor元回归器 : object
用来融合基回归器的元回归器
• verbose详细信息 : int, optional (default=0)
用来控制建立模型时输出的详细信息
Controls the verbosity of the building process.
– verbose=0 (默认):无输出
– verbose=1: 输出被融合的基回归器的数量和名字
– verbose=2: 输出被融合的基学习器的参数信息
– verbose>2: 比self.verbose - 2更详细的参数细节
Attributes属性
• regr_ : list, shape=[n_regressors]
融合的基回归器 (clones of the original regressors)
• meta_regr_ : estimator
用于融合的元回归器(clone of the original meta-estimator)
• coef_ : array-like, shape = [n_features]
元学习器的模型融合回归系数
• intercept_ : float
拟合的元学习器的截距
需要查看方程时,只需要查看coef_和intercept_这两个参数。
4.1 Methods方法
fit(X, y)
拟合出每个回归器学习在训练集中的权重系数。
Parameters
• X : {array-like, sparse matrix}, shape = [n_samples, n_features]
训练的特征向量矩阵,支持稀疏矩阵,n_samples代表样本数,n_features代表特征数
• y : array-like, shape = [n_samples]
目标值。
Returns
• self : object
*fit_transform(X, y=None, **fit_params)*
拟合数据,再转换为标准形式。
将拟合转换器用于X和y,它具有可选参数fit_params,并且返回X的转换后的X。
Parameters
• X : numpy array of shape [n_samples, n_features]
训练集
• y : numpy array of shape [n_samples]
目标值
Returns
• X_new : numpy array of shape [n_samples, n_features_new]
转换过的数组
get_params(deep=True)
返回网格搜索支持的估计器参数名
predict(X)
为X预测目标值。
Parameters
• X : {array-like, sparse matrix}, shape = [n_samples, n_features]
训练的特征向量矩阵,n_samples 代表样本数, n_features代表特征数
Returns
• y_target : array-like, shape = [n_samples]
预测出的目标值
score(X, y, sample_weight=None)
返回预测系数Rˆ2,R2 score是拟合优劣的评价指标,之前的博客拟合评价指标中有详细介绍
The coefficient Rˆ2 is defined as (1 - u/v), where u is the regression sum of squares ((y_true - y_pred) ** 2).sum() and v is the residual sum of squares ((y_true - y_true.mean()) ** 2).sum().
Best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value of y, disregarding the input features, would get a Rˆ2 score of 0.0.
Parameters
• X : array-like, shape = (n_samples, n_features)
测试样本
• y : array-like, shape = (n_samples) or (n_samples, n_outputs)
X对应的真实值
• sample_weight : array-like, shape = [n_samples], optional
样本权重
Returns
• score : float
Rˆ2 of self.predict(X) wrt. y.
*set_params(**params)*
设置这个估计器的参数
该方法适用于简单的估计器以及嵌套对象(如pipelines)。 后者具有
Returns
self
4.2 Properties
coef_
None
intercept_
None
下一篇介绍交叉验证的StackingRegressor-StackingRegressorCV
References
• Breiman, Leo. “Stacked regressions.” Machine learning 24.1 (1996): 49-64.
• MLXTEND文档:mlxtend-latest.pdf