基本信息
作者:
Edward Choi,MS; Andy Schuetz,PhD; Walter F. Stewart,PhD; Jimeng Sun,PhD
*Georgia Institute of Technology, Atlanta, USA
**Research Development & Dissemination, Sutter Health, Walnut Creek, USA
发表:
2017年 computer science
关键词:
Neural Networks, Representation learning, Predictive modeling, Heart Failure prediction.
摘要:
Objective:To transform heterogeneous clinical data from electronic health records into clinically meaningful constructed features using data driven method that rely, in part, on temporal relations among data.
Materials and Methods:The clinically meaningful representations of medical concepts and patients are the key for health analytic applications. Most of existing approaches directly construct features mapped to raw data (e.g., ICD or CPT codes), or utilize some ontology mapping such as SNOMED codes. However, none of the existing approaches leverage EHR data directly for learning such concept representation. We propose a new way to represent heterogeneous medical concepts (e.g., diagnoses, medications and procedures) based on co-occurrence patterns in longitudinal electronic health records. The intuition behind the method is to map medical concepts that are co-occuring closely in time to similar concept vectors so that their distance will be small. We also derive a simple method to construct patient vectors from the related medical concept vectors.
Results:For qualitative evaluation, we study similar medical concepts across diagnosis, medication and procedure. In quantitative evaluation, our proposed representation significantly improves the predictive modeling performance for onset of heart failure (HF), where classification methods (e.g. logistic regression, neural network, support vector machine and K-nearest neighbors) achieve up to 23% improvement in area under the ROC curve (AUC) using this proposed representation.
Conclusion:We proposed an effective method for patient and medical concept representation learning. The resulting representation can map relevant concepts together and also improves predictive modeling performance.
目标:使用数据驱动方法将异构临床数据从电子健康记录转换为具有临床意义的构建特征,该方法部分依赖于数据之间的时间关系。
材料和方法:医学概念和患者的临床意义表示是健康分析应用的关键。大多数现有方法直接构造映射到原始数据(例如,ICD或CPT代码)的特征,或者利用诸如SNOMED代码之类的一些本体映射。然而,现有方法都没有直接利用EHR数据来学习这种概念表示。我们提出了一种基于纵向电子健康记录中的共现模式来表示异质医学概念(例如,诊断,药物和程序)的新方法。该方法背后的直觉是将与时间紧密相关的医学概念映射到类似的概念向量,以使它们的距离变小。我们还推导出一种从相关医学概念向量构建患者向量的简单方法。
结果:对于定性评估,我们在诊断,药物和程序中研究类似的医学概念。在定量评估中,我们提出的表示显着改善了心力衰竭(HF)发作的预测建模性能,其中分类方法(例如逻辑回归,神经网络,支持向量机和K-最近邻居)在面积上实现了高达23%的改善在使用该提出的表示的ROC曲线(AUC)下。
结论:我们提出了一种有效的患者和医学概念表示学习方法。结果表示可以将相关概念映射到一起,并且还改善预测建模性能。
背景及本文的主要工作
背景:
- 1.电子健康记录(EHR)为预测患者风险,了解哪种方法最适合特定患者以及个性化临床决策提供了前所未有的机会。
- 2.直接对EHR的原始数据进行分析的效果并不好。
- 3.通过检测纵向EHR数据固有的病理生理学关系并构建直观特征,可以加速EHR数据在临床护理中的更有效使用以及预测分析性能的进步。
- 4.诸如SNOMED,RxNorm和LOINC之类的医学本体,并不能提供提取纵向患者数据固有的有意义关系的手段。
- 5.现有本体所固有的抽象概念,也并未提供将不同域中的元素连接到共同的、由数据元素在时间上的共现情况表示的基础病理生理学结构的方法。
本文的主要工作:
- 1.本文提出的数据驱动方法逻辑上将数据组织成更高阶的结构。将异质医学数据映射到能够实现类似概念的时间聚类的低维空间。然后鉴定共存蔟并形成由流行性组织的更高级病理生理学特征集。
- 2.本文基于最先进的神经网络模型在纵向EHR数据上学习这种医学概念表示。还提出了一种基于医学概念表示推导患者表示的有效方法。
- 3.文中将这些学习的表示用于心力衰竭预测任务,其中在许多分类模型中可以获得高达23%的AUC显著性能改善。
算法
概述
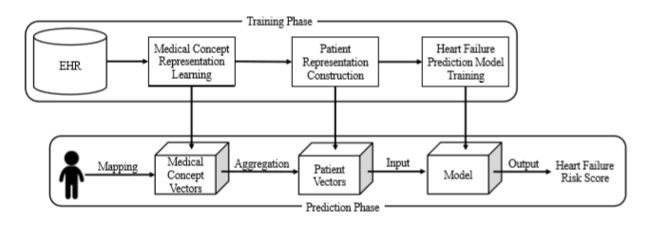
在图1中,我们高度概述了执行HF预测所采取的步骤。在训练阶段,我们首先使用Skip-gram从EHR数据集训练医学概念向量。然后,我们使用医学概念向量构建患者表示。然后使用患者表示来使用各种分类器训练心力衰竭预测模型,即逻辑回归,支持向量机(SVM),具有一个隐藏层(MLP)的多层感知器和K-最近邻分类器(KNN)。在预测阶段,我们将患者的医疗记录映射到医学概念向量,并通过聚合概念向量来生成患者向量。然后我们将患者向量插入训练模型,这反过来将产生心力衰竭的风险评分。
医学概念表示学习
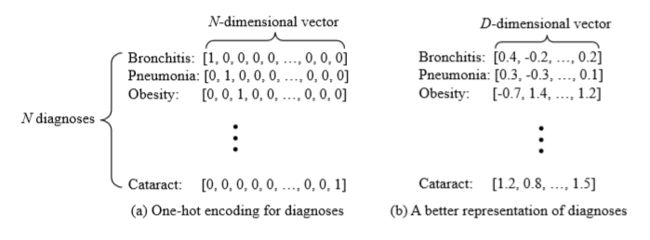
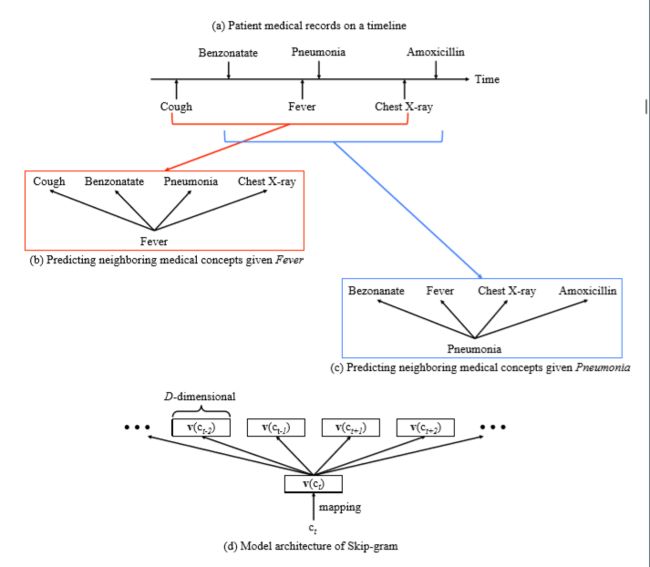
图3(a)是按时间顺序的患者病历的示例。 Skip-gram假设概念的含义由其上下文(或邻居)决定。 因此,给定一系列概念,Skip-gram选择目标概念并尝试预测其邻居,如图3(b)所示。 然后我们滑动上下文窗口,选择下一个目标并进行相同的上下文预测,如图3(c)所示。 由于Skipgram的目标是学习概念的向量表示,我们需要将医学概念转换为D维向量,其中D是用户选择的值,通常在50到1000之间。因此,实际预测是用向量进行的,如图所示 通过图3(d),其中c t是第t个时间的概念,v(c t)代表c的向量。“Skipgram的目标是最大化以下平均对数概率,
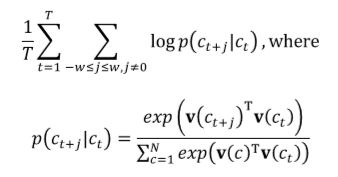
其中T是医学概念序列的长度,w是上下文窗口的大小,c t时间步长t的目标医学概念,c t+j时间步长t+j的邻近医学概念,v(c)表示医学概念c的上下文向量,N是医学概念的总数。上下文窗口的大小通常设置为5,为我们提供了围绕目标概念的10个概念。注意,条件概率表示为softmax函数。简单地说,通过最大化邻近概念的内积的softmax分数,Skip-gram学习有效捕获概念之间细粒度关系的实值向量。需要说明的是,我们的Skip-gram表达方式与原始的Skip-gram不同。在原始的Skip-gram[9]中,他们区分目标概念的向量和邻近概念的向量。在我们的公式中,我们强制两组向量保持[15]所建议的相同值。
构造患者表示
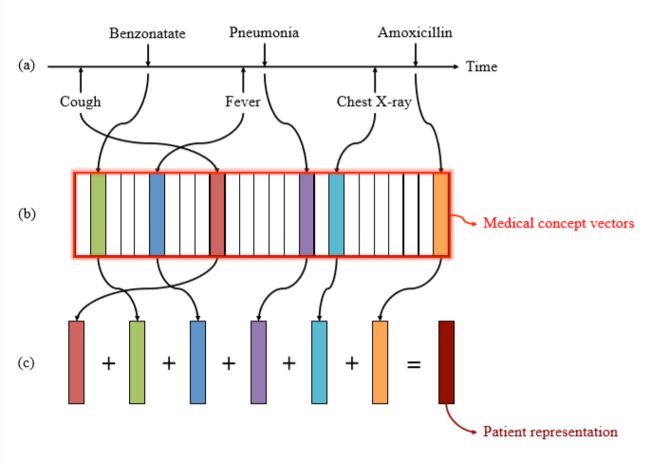
患者的有效表示将简单地将他的病史中的所有医学概念转换为医学概念向量,然后将所有这些向量相加以获得患者的表示向量,如图4所示。
实验及实验结果
人口和数据来源
数据来自Sutter Palo Alto医学基金会(Sutter-PAMF)初级保健患者。 使用在2000年5月16日至2013年5月23日期间确定的病例和对照提取研究数据集。 该数据集包含265,336名患者,总共555,609个独特的临床事件。
EHR数据包括人口统计学,吸烟和酒精消耗,临床和实验室价值,与遭遇,订单和转介相关的国际疾病分类第9版(ICD-9)代码,当前程序术语(CPT)代码中的程序信息和药物处方 医学名称中的信息。
医学概念表示学习的配置
我们先对所有265,336名患者的记录进行扫描,并按时间顺序提取每位患者的诊断,药物和程序编码。如果患者在一次就诊时接受了多次诊断,药物治疗或手术,那么这些医疗代码将被赋予相同的时间戳。诊断,药物和程序的数量分别为11,460,17,769和9,370,共计38,599个独特的医学概念。然后,我们应用Skip-Gram,用100维向量来表示医学概念(即图2(b)中的D = 100),参考300足以有效地表示NLP中的692,000个词汇表。 [9]
我们使用了Theano [16],这是一个用于评估数学表达式以实现Skip-gram的Python库。 Theano还可以利用GPU来大大提高涉及大型矩阵的计算速度。为了优化,我们使用Adadelta [17],它采用自适应学习率。与广泛用于训练神经网络的随机梯度下降(SGD)不同,Adadelta并不非常依赖于学习率的设置,并且表现出良好的性能。在配备Xeon E5-2697和Nvidia Tesla K80的Ubuntu机器上使用Theano 0.7和CUDA 7,运行10个Adadelta时代大约需要43个小时,批量大小为100。
医学概念表征学习的评价
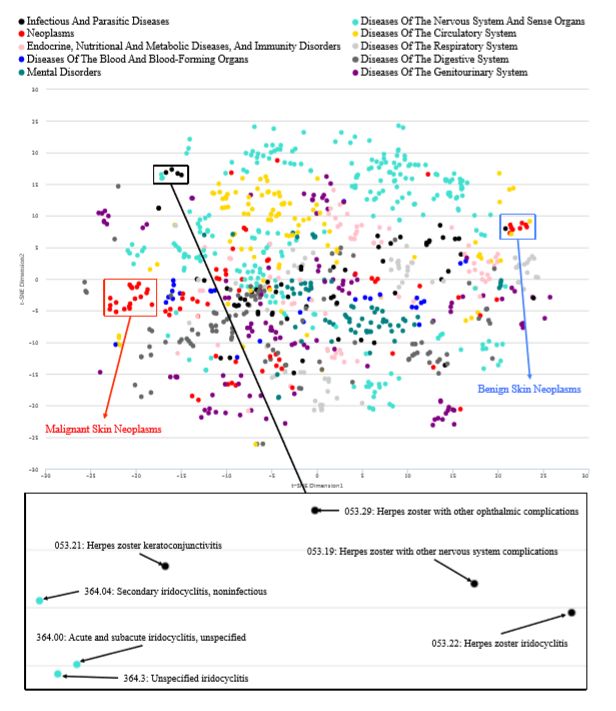
图5显示了在2D空间中绘制的训练诊断向量,其中我们使用t-SNE [18]将尺寸从100减小到2. t-SNE是一种维度降低算法,专门用于绘制高维数据到二维或三维空间。我们从10个最高类别的ICD-9中随机选择了1,000个诊断,这些诊断显示在图的顶部。很容易看出,诊断通常按其相应的类别很好地分组。但是,如果来自同一类别的诊断实际上完全不同,它们应该分开。这由图5中的红色框和蓝色框显示。即使它们来自相同的肿瘤类别,红色框表示一组恶性皮肤肿瘤(172.X,173.X),而蓝色框表示一组良性皮肤肿瘤(216.X)。红色和蓝色框的详细图形在补充部分。更重要的是,正如黑匣子所示,来自不同群体的诊断如果实际相关则彼此靠近。在黑匣子中,与带状疱疹相关的虹膜睫状体炎和眼部感染位于紧密位置,这与大约43%带状疱疹眼科(HZO)患者发生虹膜睫状体炎的事实相对应。 [19]
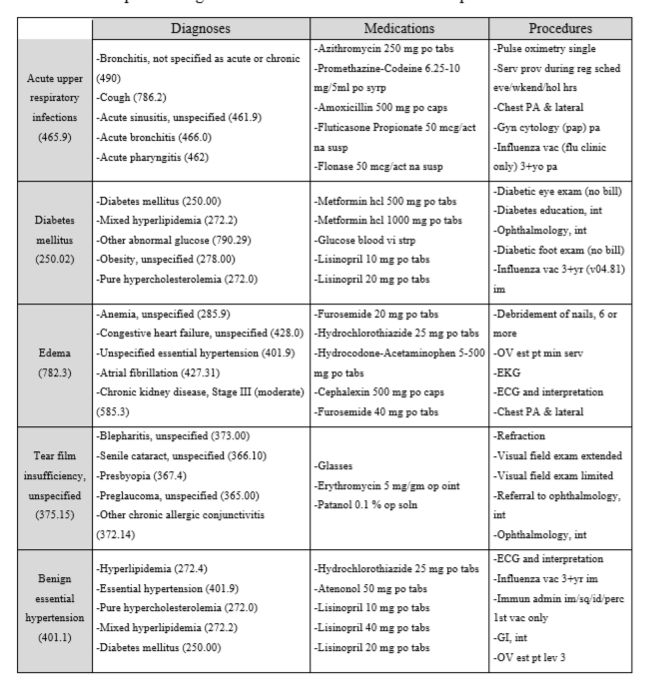
为了了解代表性学习如何很好地捕捉药物和程序以及诊断之间的关系,我们进行了以下研究。我们选择了数据中最频繁发生的100个诊断,根据余弦相似性获得每个诊断50个最接近的载体,在50个载体中选择5个诊断,药物和程序载体。表1描绘了整个lis的一部分。请注意,某些单元格包含少于5个项目,这是因为在50个最接近的向量中少于5个项目。
医学概念向量加法的评价
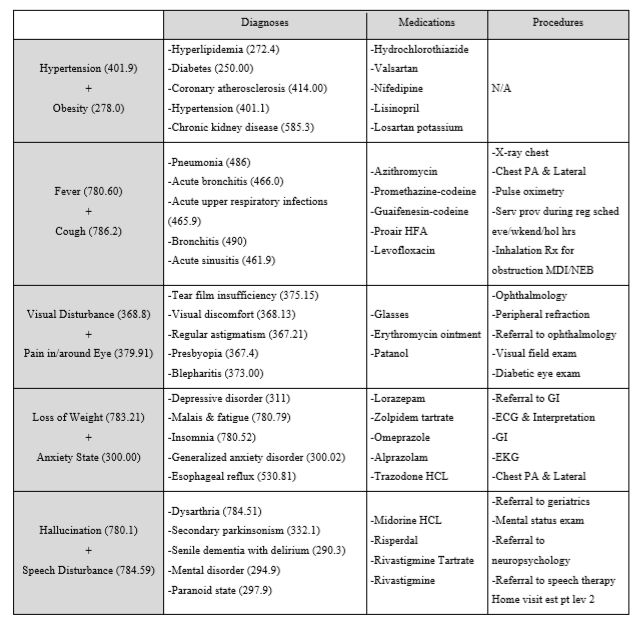
由于难以生成医学上有趣的例子,我们选择了5个直观的例子,如表2的第一列所示,给出了医学概念向量添加的简单演示。我们再次为两个医学概念向量的总和生成了50个最接近的向量,并从每个诊断,药物和程序类别中选择了5个。
心力衰竭预测评估的设置
在本节中,我们首先描述为什么我们选择心力衰竭(HF)预测任务作为应用程序。然后我们简要提一下要使用的模型,然后描述数据处理步骤,为所有模型创建训练数据。最后,评估策略将遵循实施细节。
心力衰竭预测任务:HF的发作与高水平的残疾,医疗保健成本和死亡率相关(诊断后5年内死亡风险约为50%)。 [20] [21]在减缓HF严重程度的进展方面进展相对较小,主要是因为在实际诊断之前很难检测到。因此,干预主要局限于诊断后的时间段,对疾病进展影响很小或没有影响。较早的HF检测可以通过患者参与和使用血管紧张素转换酶(ACE)抑制剂或血管紧张素II受体阻滞剂(ARBs),轻度运动和减少盐摄入量以及可能的其他选择[22] [[22] [ 23] [24] [25]。
性能比较模型:我们的目标是强调医学概念表示的有效性和从中得出的患者表征。 因此,我们使用单热矢量和医学概念向量训练了四种流行的分类器,即逻辑回归,MLP,SVM和KNN。
病例和对照的定义:HF事件发生的标准在[26]中描述,并从[27]中采用。标准定义为:1)HF的合格ICD-9代码在遭遇,问题列表或药物订单字段中显示为诊断代码。符合条件的ICD-9代码列在补充部分。排除了带有图像和其他相关订单的ICD-9代码,因为这些订单通常代表对HF的怀疑,其结果往往是负面的; 2)至少有三次符合条件的ICD-9代码的临床遭遇必须在12个月内相互发生,其中诊断日期分配到三个日期中的最早日期。如果HF诊断代码的第一次和第二次出现之间的时间跨度大于12个月,则第二次遭遇的日期被用作第一次排位赛; 3)在HF诊断时年龄大于或等于50且小于85。
对于每个HF事件,选择最多十个(平均九个)符合条件的初级保健诊所,性别和年龄匹配(5年间隔)对照。如果在诊断HF事件之前的12个月内没有进行HF诊断,初级保健患者就有资格作为对照。控制对象被要求在匹配的HF病例患者的第一次办公室访问的一年内进行他们的第一次办公室访问,并且在病例的HF诊断日期之前或之后30天至少有一次办公室遭遇以确保在病例之间观察的类似持续时间和控制。
从265,336名Sutter-PAMF患者中,确定了3,884例HF事件和28,903例对照患者。
数据处理:为了训练这四个模型,我们再次从3,884个案例和28,903个控件的遭遇,药物订单,程序顺序和问题列表记录中生成数据集。根据每位患者的HF诊断日期(HFDx),我们提取了HFDx之前18个月的所有记录。为了使用医学概念向量训练模型,我们将医疗记录转换为患者向量,如图4所示。为了使用单热编码训练模型,我们以与图相同的方式将医疗记录转换为聚合的单热矢量。 4,使用单热矢量代替医学概念矢量。
为了研究用不同大小的数据训练的医学概念向量与它们对模型的预测性能的影响之间的关系,我们使用了三种医学概念向量:1)仅用HF病例训练的那个(3,884名患者), 2)接受HF病例和对照组训练的患者(32,787名患者),3)接受全部样本训练的患者(265,336名患者)。注意,用较少数量的患者训练的医学概念向量覆盖较少数量的医学概念。因此,当如图4所示将患者记录转换为患者向量时,我们排除了没有匹配的医学概念向量的所有医疗代码。将所有输入向量归一化为零均值和单位方差。
评估策略:我们使用六重交叉验证来训练和评估所有模型,并估计模型对独立数据集的推广程度。使用ROC曲线下面积(AUC),对训练中未使用的数据测量预测性能。我们使用置信度得分来计算其SVM的AUC。交叉验证的详细说明在补充部分给出。实施细节:使用Theano实施Logistic回归和MLP,并使用Adadelta进行培训。 SVM和KNN是使用Python Scikit-Learn实现的。所有模型均由用于医学概念表示学习的相同机器训练。用于训练每个模型的超参数在补充部分中描述。
实施细节:使用Theano实施Logistic回归和MLP,并使用Adadelta进行培训。 SVM和KNN是使用Python Scikit-Learn实现的。 所有模型均由用于医学概念表示学习的相同机器训练。 用于训练每个模型的超参数在补充部分中描述。
心力衰竭预测评估
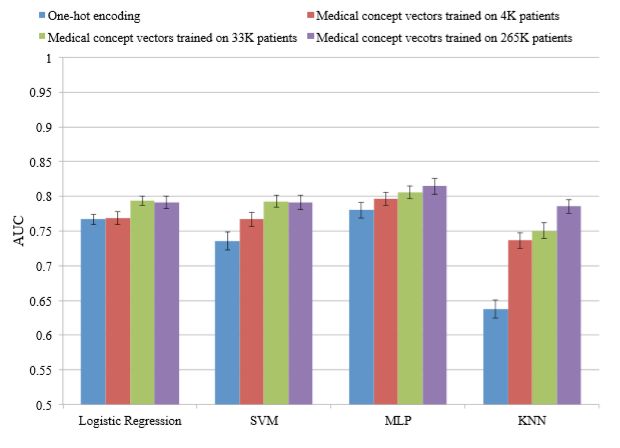
图6显示了各种模型和输入向量的6倍交叉验证的平均AUC。颜色代表不同的训练输入向量。误差棒表示从6倍交叉评估得出的标准偏差。医学概念表示学习的力量是显而易见的,因为所有模型都显示出HF预测性能的显着改善。 Logistic回归和SVM都是线性模型,在使用医学概念向量进行训练时表现出相似的性能,尽管SVM从使用更好的医学概念表示中获益更多。 MLP也受益于使用医学概念向量,并且作为非线性模型,与逻辑回归和SVM相比,显示出更好的性能。有趣的是,KNN从使用医学概念向量中受益最多,甚至是在最小数据集上训练的向量。考虑到KNN分类基于数据点之间的距离这一事实,这清楚地表明适当的医学概念表示可以减轻由简单的单热编码引起的稀疏性问题。
图6还告诉我们,医学概念表示最好用大数据集学习,如Mikolov等人所示。 [6]然而,在大多数模型中,尤其是KNN,甚至用最少数量的患者训练的医学概念向量也改善了预测性能。考虑到在使用少数患者训练的医学概念向量时,通过排除不匹配的医疗代码来使用较少量的信息这一事实,这是非常令人惊讶的,模型仍然显示出更好的预测性能。这再次清楚地证明,医学概念表示学习提供了比单热编码更有效的方式来表示医学概念。
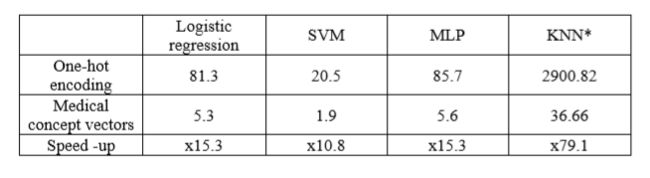
表3描述了使用单热编码和医学概念向量时每个模型的训练时间。 考虑到单热编码的高维性,用医学概念向量训练模型应该提供显着的加速,如表3的最后一行所示。这表明医学概念向量不仅提高了性能,而且显着降低 训练时间。
未来的工作
整个实验完全没有专业知识,如医学本体或医学专家设计的功能。 仅使用医疗订单记录,就能够产生临床上有意义的医学概念表示,这一点可以扩展到许多其他医疗问题。未来的可能的发展方向包括:
- 1.嵌入更深入的医学信息
- 2.使用专家知识
- 3.解决心力衰竭之外的其他医疗问题
结论
本文提出了一种将异质医学概念表示为实值向量并使用最先进的深度学习方法构建有效患者表示的新方法。 文中定性地证明,经过训练的医学概念向量确实捕获了与我们的医学知识和经验相符的医学见解。 对于心力衰竭预测任务,医学概念向量改善了许多分类器的性能,从而定量地证明其有效性。 文中还讨论了提出的方法和未来可能的工作的局限性,包括更深入地利用医学信息,将专家知识结合到框架中,以及扩展我们对各种医学应用的方法。