主要内容
探索R中的数据结构
输入数据
导入数据
标注数据
2.1 数据集的概念
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量(本书使用统计学家术语)。
数据集的行和列叫法不同,统计学家术语为观测(observation)和变量(variable),数据库分析师术语为记录(record)和字段(field),数据挖掘和机器学习学科的研究者则把它们叫作示例(example)和属性(attribute)。

表2-1,可以看到数据集的结构(矩形数组)以及其中包含的内容和数据类型。
PatientID是行/实例标识符,AdmDate是日期型变量,Age是连续型变量,Diabetes是名义型变量,Status是有序型变量。
在R中, PatientID 、 AdmDate 和 Age 为数值型变量,而 Diabetes 和 Status则为字符型变量。另外,你需要分别告诉R: PatientID 是实例标识符, AdmDate 含有日期数据,Diabetes 和 Status 分别是名义型和有序型变量。R将实例标识符称为 rownames (行名),将类别型(包括名义型和有序型)变量称为因子( factors )。
2.2 数据结构
R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表。

注意:在R中,术语 对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。对象都拥有某种模式,描述了此对象是如何存储的,以及某个类。
2.2.1向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数 c() 可用来创建向量。各类向量如下例所示:
a <- c(1, 2, 5, 3, 6, -2, 4) #数值型向量
b <- c("one", "two", "three") #字符型向量
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE) #逻辑型向量注意,单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。同一向量中无法混杂不同模式的数据。
如何访问向量中的元素?通过在方括号中给定元素所处位置的数值。如下所示:
> a <- c("k", "j", "h", "a", "c", "m")
> a[3] #访问向量中第三个元素
[1] "h"
> a[c(1, 3, 5)] #访问向量中第一、三、五个元素
[1] "k" "h" "c"
> a[2:6] #访问向量中第二至第六个元素
[1] "j" "h" "a" "c" "m"
2.2.2 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过函数matrix() 创建矩阵。
myymatrix <- matrix(vector, nrow=number_of_rows, ncol=number_of_columns,byrow=logical_value, dimnames=list(char_vector_rownames, char_vector_colnames))
其中 vector 包含了矩阵的元素,nrow和ncol 用以指定行和列的维数,dimnames 包含了可选的、以字符型向量表示的行名和列名。选项 byrow 则表明矩阵应当按行填充(byrow=TRUE )还是按列填充(byrow=FALSE ),默认情况下按列填充。


按行填充的2*2矩阵。

按列填充的2*2矩阵。

如上图: 创建了一个内容为数字1到10的2×5矩阵。默认情况下,矩阵按列填充。然后,我们分别选择了第二行和第二列的元素。接着,又选择了第一行第四列的元素。最后选择了位于第一行第四、第五列的元素。
矩阵都是二维的,和向量类似,矩阵中也仅能包含一种数据类型。
2.2.3 数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过 array 函数创建。
myarray <- array(cecior,dimensions,dimnames)。其中 vector( 下图中的“1:24”) 包含了数组中的数据, dimensions (下图中的“c(2,3,4)”)是一个数值型向量,给出了各个维度下标的最大值,而 dimnames 是可选的、各维度名称标签的列表。

上例中若是c(2,3,4)数值被改变则提示出错,“length of 'dimnames' [1] not equal to array extent”。数组的维度需要符合数值型向量给出的各维度下标最大值。
像矩阵一样,数组中的数据也只能拥有一种模式。从数组中选取元素的方式与矩阵相同。z[1,2,3]相当于A1B2C3为15。
2.2.4 数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。它与你通常在SAS、SPSS和Stata中看到的数据集类似。数据框将是你在R中最常处理的数据结构。
下表所示的病例数据集包含了数值型和字符型数据。由于数据有多种模式,无法将此数据集放入一个矩阵。在这种情况下,使用数据框是最佳选择。
数据框可通过函数 data.frame() 创建: mydata <- data.frame(col1,col2,col3,…)。其中列向量 col1 、 col2 、 col3 等可为任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数 names 指定。

.选取数据框中元素的方式中注意$号是新出现的。它被用来选取一个给定数据框中的某个特定变量。比如:> table(patientdata$diabets,patientdata$status),表示生成糖尿病类型变量 diabetes 和病情变量 status 的列联表。
001 attach()、detach()、和with()的使用。attach()函数可将数据框添加到R的搜索路径中,detach()函数将数据框从搜索路径中移除。函数 attach() 和 detach() 最好在你分析一个单独的数据框,并且不太可能有多个同名对象时使用。with()函数用法略。
002 实例标识符
2.2.5因子
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。
名义型变量是没有顺序之分的类别变量。糖尿病类型 Diabetes ( Type1 、 Type2 )是名义型变量的一例。有序型变量表示一种顺序关系,而非数量关系。病情Status ( poor 、improved 、 excellent )是顺序型变量的一个示例。
具体使用如下:

2.2.6 列表
一般来说,列表就是一些对象(或成分,component)的有序集合。可以使用函数 list() 创建列表:mylist <- list(object1, object2, ...)。其中的对象可以是目前为止讲到的任何结构。
list列表的重要性。首先,列表允许以一种简单的方式组织和重新调用不相干的信息。其次,许多R函数的运行结果都是以列表的形式返回。

2.3 数据的输入
2.3.1 使用键盘输入数据。对于较大的数据集,主要从现有的文本文件、Excel电子表格、统计软件或数据库中导入数据。
2.3.2 从带分隔符的文本文件导入数据。使用 read.table() 从带分隔符的文本文件中导入数据。帮助参考help(read.table)。
2.3.3 导入 Excel 数据。函数read.xlsx() 导入一个工作表到一个数据框中。最简单的格式是 read.xlsx(file, n)。使用install.packages("xlsx")下载xlsx包,使用以下代码
library(xlsx)
workbook <- "c:/myworkbook.xlsx"
mydataframe <- read.xlsx(workbook, 1) 导入工作簿myworkbook.xlsx 的第一个表。
2.3.4 导入 XML 数据
2.3.5 从网页抓取数据
2.3.6 导入 SPSS 数据。使用函数 read.spss() 导入到R中。下载安装Hmisc 包。install.packages("Hmisc")
2.3.7 导入 SAS 数据
2.3.8 导入 Stata 数据
2.3.9 导入 NetCDF 数据
2.3.10 导入 HDF5 数据
2.3.11 访问数据库管理系统
2.3.12 通过 Stat/Transfer 导入数据
2.4 数据集的标注
为了使结果更易解读,数据分析人员通常会对数据集进行标注。
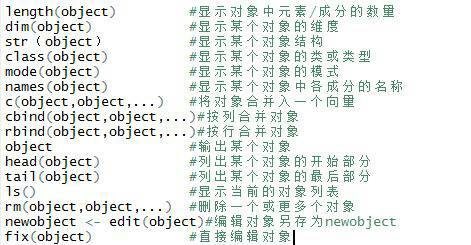
2.5 处理数据对象的实用函数
创建于 2017-01-23