简单来说机器学习就是讲一段已经存有的数据,与数据对应的结果通过机器学习的算法,得到估计函数.然后再将需要预测的函数用估计函数得到预测结果
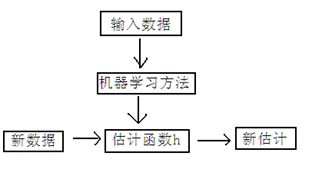
机器学习分类
- 有监督学习
简单来说就是已经给了你数据并且给了数据所产生的结果
- 无监督学习
在只有数据却没有结果的情况下,寻找影藏的模式或内在结构
- 半监督学习
在半监督学习方式下,训练数据有部分被标识,部分没有被标识,这种模型首先需要学习数据的内在结构,以便合理的组织数据来进行预测。算法上,包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
有监督学习
有监督学习机器算法有分类和回归两类
分类主要用于数据分散,且预测结果只分为几类,常用的分类机器算法有以下几种:
- k-邻近算法
K近邻(k-Nearest Neighbor,KNN)分类算法的核心思想是如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
#导入KNN算法
from sklearn.neighbors import KNeighborsClassfier
knn = KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)
# n_neighbors每个类别取多少个点来算距离一般不大于10,weights预测的权函数有uniform与distance两种,p是使用距离度量参数 metric 附属参数,只用于闵可夫斯基距
#离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。默认为2
knn.fit(x_train,y_train)#训练数据,x_train为用来训练的数据,y_train为数据所对应的结果
knn.score(x_train,y_train)#得出训练数据的得分
y_ = knn.predict(x_test) #用测试数据去算出预测结果
knn.score(x_test,y_test)#测试数据的得分
#y_test,是x_test对应的正确结果,而y_是根据knn.fit()训练完后去预测的结果
- Logistics逻辑斯蒂回归分类
根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归” 一词源于最佳拟合,表示要找到最佳拟合参数集。
Logistic Regression和Linear Regression的原理是相似的,可以简单的描述为这样的过程:
(1)找一个合适的预测函数,一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程是非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有梯度下降法(Gradient Descent)。
损失值简单来说就是(y_-y_test)^2求平均
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
#solver参数的选择:
#“liblinear”:小数量级的数据集
#“lbfgs”, “sag” or “newton-cg”:大数量级的数据集以及多分类问题
#“sag”:极大的数据集
#C惩罚项,用来去除权重交小的参数
logistic.fit(x_train,y_train)
logistic.score(x_train,y_train)
y_ = logistic.predict(x_test)
-
决策树
下图为一个女孩的相亲决定绿色表示为条件也就是特征,黄色则为结果
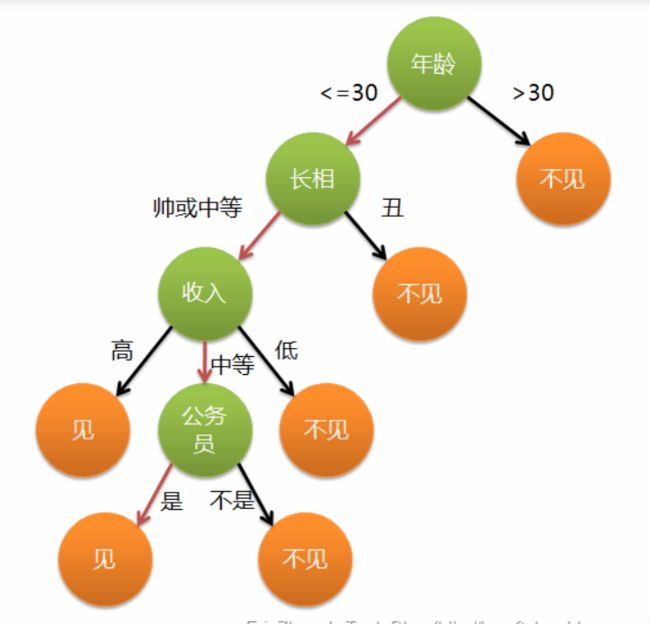 image.png
image.png
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
from sklearn.tree import DecisionTreeClassfier
tree = DecisionTreeClassfier(max_depth)
tree.fit(x_train,y_train)#训练数据,x_train为用来训练的数据,y_train为数据所对应的结果
tree.score(x_train,y_train)#得出训练数据的得分
y_ = tree.predict(x_test) #用测试数据去算出预测结果
tree.score(x_test,y_test)#测试数据的得分
#max_depth为决策深度,需要调节,过高容易过拟合,而过低容易欠拟合
- 贝叶斯(用法与其他算法)
- 高斯分布朴素贝叶斯
用于一般的分类问题,from sklearn.naive_bayes import GaussianNB
- 伯努利朴素贝叶斯
常用于二分类的分类问题,from sklearn.naive_bayes import BernoulliNB
- 多项式朴素贝叶斯
用于文本数据,如垃圾短信分类等,from sklearn.naive_bayes import MultinomialNB
- 补充,当对文本分析的时候需要将文本内容转换
from sklearn.feature_extraction.text import TfidfVectorizer tf = TfidfVectorizer() tf.fit(data)#data为文本数据 X_train = tf.transform(data).toarray()#转换成能使用的训练数据
- 高斯分布朴素贝叶斯
- 支持向量机SVM
原理:支持向量机,其含义是通过支持向量运算的分类器。其中“机”的意思是机器,可以理解为分类器。 那么什么是支持向量呢?在求解的过程中,会发现只根据部分数据就可以确定分类器,这些数据称为支持向量。且SVM的优点就在于可支持线性与非线性分类,而其中线性分类可以理解为这些有n个属性和一个二分类标志,而这个n个属性是存在于n维的空间中,而线性分类就是要寻找一个能使这个超平面能将n个属性分成两类,且离两类的距离最大的超平面.而非线性的话,简单来说会更灵活.
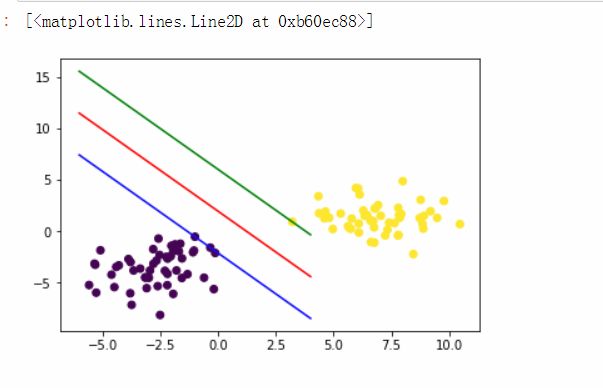 image.png
image.png
如图中,只根据几个点就能得出最适合的分类线
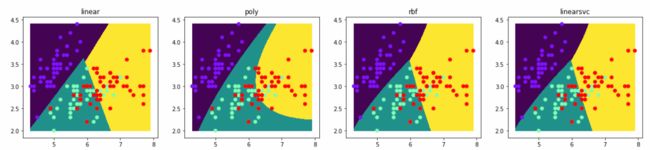
# 比较几种核函数
#导入鸢尾花数据
from sklearn.datasets import load_iris
#svm中的svc是做分类,而svm是做回归
from sklearn.svm import SVC,LinearSVC
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
data = load_iris()['data'][:,0:2]
target = load_iris()['target']
# 取data中的两个特征画点
x_min,x_max = data[:,0].min(),data[:,0].max()
y_min,y_max = data[:,1].min(),data[:,1].max()
# 设置面的范围
x,y = np.linspace(x_min,x_max,1000),np.linspace(y_min,y_max,1000)
# 创建网格
X,Y = np.meshgrid(x,y)
# 创建预测数据
x_test = np.c_[X.ravel(),Y.ravel()]
#将svc核设置为线性
plt.figure(figsize=(5*4,4))
index = 1
for i in ['linear', 'poly', 'rbf']:
svc = SVC(kernel=i)
svc.fit(data,target)
y_ = svc.predict(x_test)
#设置每个图的位置
axes = plt.subplot(1,4,index)
#画出面
axes.pcolormesh(X,Y,y_.reshape(1000,1000))
#画出点做对比
axes.scatter(data[:,0],data[:,1],c=target,cmap='rainbow')
#设置标题
axes.set_title(i)
index += 1
#在加入Linearsvc比较
Linearsvc = LinearSVC()
Linearsvc.fit(data,target)
y_ = svc.predict(x_test)
axes = plt.subplot(1,4,4)
axes.pcolormesh(X,Y,y_.reshape(1000,1000))
axes.scatter(data[:,0],data[:,1],c=target,cmap='rainbow')
axes.set_title('linearsvc')
而回归则是用在数据是连续的,并且预测结果明显是不同的.例如温度变化或时间变化.包括一元回归和多元回归,线性回归和非线性回归,回归的机器算法有以下几种:
- LinearRegression普通线性回归
原理:假定输人数据存放在矩阵X中,而回归系数存放在向量W中。那么对于给定的数据X1, 预测结果将会通过
Y=XW
Y=X1W1+X2W2+X3W3+.......(几个特征就会有几个回归系数,通过算法可以找出这些回归系数)
给出。现在的问题是,手里有一些X和对应的Y,怎样才能找到W呢?
一个常用的方法就是找出使误差最小的W。这里的误差是指预测Y值和真实Y值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消,所以我 们采用平方误差。
最小二乘法:

from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(x_train,y_train)
y_ = linear(x_test)
linear.coef_ #回归系数
linear.intercept_ #截距

- Ridge岭回归
当数据的特征比样本点还多的时候,输入的矩阵X就不是满秩矩阵将不可逆所以就引入Ridege岭回归,简单来说就引入一个惩罚项λ使矩阵X成为满秩矩阵可逆,并且去掉一些不重要的参数,适用于一些过拟合或各边存在多重共线性的时候
from sklearn.linear_model import Ridge
ridge= Ridge(alpha)
ridge.fit(x_train,y_train)
y_ = ridge(x_test)
ridge.coef_ #回归系数
ridge.intercept_ #截距
#alpha就是λ惩罚项
- Lasso回归
#与岭回归相似
from sklearn.linear_model import Lasso
lasso= Lasso(alpha)
lasso.fit(x_train,y_train)
y_ = lasso(x_test)
lasso.coef_ #回归系数
lasso.intercept_ #截距
#alpha就是λ惩罚项
#Lasso效果会比岭回归好
- K-邻近算法也可用于回归
from sklearn.neighbors import KNeighborsRegressor
- 决策树也可以用于回归问题
from sklearn.tree import DecisionTreeRegressor
- svm中SVR也可以解决回归问题
from sklearn.svm import SVR