首先引用廖老师的一句话:Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并行在Python中就是一个美丽的梦。
线程是进程的一部分, 每个线程也有它自身的产生、存在和消亡的过程,多线程都可以执行多个任务。任何进程默认就会启动一个线程,我们把该线程称为主线程(MainThread),主线程又可以启动新的线程。
Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,执行别的线程。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
线程的优点:
1, 比单线程运行速度快。
2, 共享内存和变量,资源消耗少。
线程的缺点:
1, 线程之间容易发生死锁,产生数据错乱。
线程的状态图:
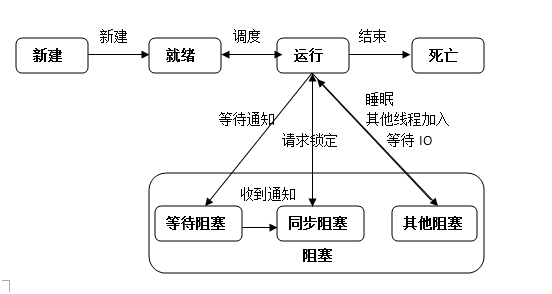
创建线程
Python中常使用的线程模块
- thread(低版本使用的),threading是高级模块,对thread进行了封装。绝大多数情况下,只需要使用threading这个高级模块。
- Queue
- multiprocessing
Thread是threading模块中最重要的类之一,可以使用它来创建线程。创建新的线程有两种方法:
1, 直接创建threading.Thread类的对象,初始化时将可调用对象作为参数传入。
2, 通过继承Thread类,重写它的run方法。
- 直接创建threading.Thread类的对象创建新线程 / 守护进程
#encoding: utf-8
'''
使用threading.Thread类创建新线程。
构造方法:
__init__(group=None, target=None, name=None, args=(), kwargs=None, verbose=None)
参数说明:
group:线程组,目前还没有实现,库引用中提示必须是None。
target:要执行的方法;
name:线程名;
args/kwargs:要传入方法的参数。
'''
import threading
import time
def func():
print '当前运行的是子进程 {}'.format(threading.current_thread().name)
time.sleep(1)
print '子进程 {} 运行结束'.format(threading.current_thread().name)
if __name__ == '__main__':
print '当前运行的是主进程 {}'.format(threading.current_thread().name)
t = threading.Thread(target=func, name='t-1')
t1 = time.time()
#t.setDaemon(True) # 将当前线程设置为守护线程,程序会等待【非守护线程】结束才退出,不会等【守护线程】。
t.start() #启动线程
print t.is_alive()
t.join(2) # 设置等待时间为2s,超过指定时间就会杀死子进程,默认为空,即一直等待子进程结束才往下接续运行。
print t.is_alive()
print '用时:',time.time()-t1
print '主进程 {} 运行结束'.format(threading.current_thread().name)
输出:
当前运行的是主进程 MainThread
当前运行的是子进程 t-1
子进程 t-1 运行结束
用时: 1.07799983025
主进程 MainThread 运行结束
注意:
t.getName()#获得线程对象名称。
t.isAlive()#判断线程是否还活着。
t.setDaemon()设置是否为守护线程。初始值从创建该线程的线程继承而来,当没有非守护线程仍在运行时,程序将终止。也可以通过t = Thread(target = func, args(1,), daemon = True)
- 继承自Thread类创建新线程。
#encoding: utf-8
'''
继承自Thread类创建新线程。
'''
from threading import Thread
import time
class MyThread(Thread):
def __init__(self, a):
super(MyThread, self).__init__() # 调用Thread类的构造函数
self.a = a
def run(self):
print 'sleep:',self.a
# time.sleep(self.a)
if __name__ == '__main__':
t1 = MyThread(2)
t2 = MyThread(4)
t1.start()
t2.start()
t1.join()
t2.join()
输出:
sleep: 2
sleep: 4
注意:
继承Thread类的新类MyThread构造函数中必须要调用父类的构造方法,这样才能产生父类的构造函数中的参数,才能产生线程所需要的参数。新的类中如果需要别的参数,直接在其构造方法中加即可。
同时,新类中,在重写父类的run方法时,它默认是不带参数的,如果需要给它提供参数,需要在类的构造函数中指定,因为在线程执行的过程中,run方法时线程自己去调用的,不用我们手动调用,所以没法直接给传递参数,只能在构造方法中设定好参数,然后再run方法中调用。
创建线程池并发执行
Python中线程与进程使用的同一模块 multiprocessing。使用方法也基本相同,唯一不同的是,from multiprocessing import Pool这样导入的Pool表示的是进程池;
from multiprocessing.dummy import Pool这样导入的Pool表示的是线程池。这样就可以实现线程里面的并发了。
#encoding: utf-8
'''
创建线程池并发执行
'''
import time
from multiprocessing.dummy import Pool as ThreadPool
def func(ans):
time.sleep(1)
print ans
if __name__ == '__main__':
l = [1,2,3,4,5]
pool = ThreadPool(5) #创建5个容量的线程池并发执行
t1 = time.time()
pool.map(func, l)
pool.close()
pool.join()
print '用时:',time.time() - t1
输出:
45
321
用时: 1.09400010109
注意:这里的pool.map()函数,跟进程池的map函数用法一样,也跟内建的map函数一样。
把程序改为pool = ThreadPool(1)
输出:
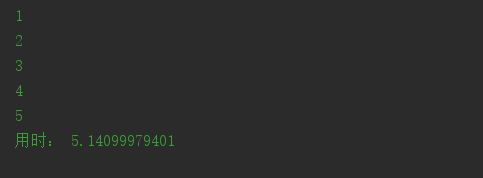
现在就相当于时单线程,一个方法执行完了再执行另一个方法。
再把程序改成pool = ThreadPool(10000)
输出:

发现运行的时间没有缩短反而变长了。
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。
如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型,或者批处理任务模型。
假设你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以幼儿园小朋友的眼光来看,你就正在同时写5科作业。
但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
所以,多任务一旦多到一个限度,就会消耗掉系统所有的资源,结果效率急剧下降,所有任务都做不好。
就这个程序而言, l 列表长度为5,有5个线程就够用了,但开了10000个线程做这件事,时间反而浪费在了线程之间的切换操作。
线程锁
在并发情况下,指令执行的先后顺序由内核决定。同一个线程内部,指令按照先后顺序执行,但不同线程之间的指令很难说清除哪一个会先执行。因此要考虑多线程同步的问题。同步(synchronization)是指在一定的时间内只允许某一个线程访问某个资源。
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
- 看这个程序:
#encoding: utf-8
'''
数据错乱
'''
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
change_it(n)
if __name__ == '__main__':
lock = threading.Lock()
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
先存后取,结果应该为0 ,但是结果是 -2540
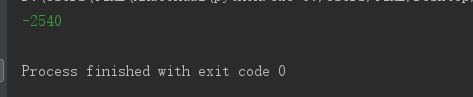
我们当然不希望存款变成了负的。这是因为在两个线程执行过程中,存在同时访问 change_it 函数的时候,而 balance = balance - n 语句在CPU中是分开拆分开执行的 :
先 balance-n 存入临时变量
然后 balance = 临时变量
这样当两条线程同时执行change_it 函数时就会发生一加一减的赋值或算数错误。所以账户余额就有可能负的。
- 死锁:假设有两个全局资源,a和b,有两个线程thread1,thread2. thread1占用a,想访问b,但此时thread2占用b,想访问a,两个线程都不释放此时拥有的资源,那么就会造成死锁。
这两种情况都可以用线程锁轻松解决(一口气写这么多,好累啊~~)。
#encoding: utf-8
'''
添加线程锁保证某时刻 只有一个线程在执行某函数
'''
import time, threading
balance = 0
def change_it(n):
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
try:
# 添加锁
lock.acquire()
change_it(n)
finally:
# 释放锁
lock.release()
if __name__ == '__main__':
lock = threading.Lock()
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
输出:
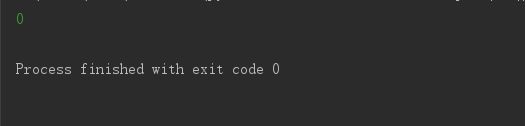
注意:
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
GIL(全局解释锁) and Lock(线程锁)
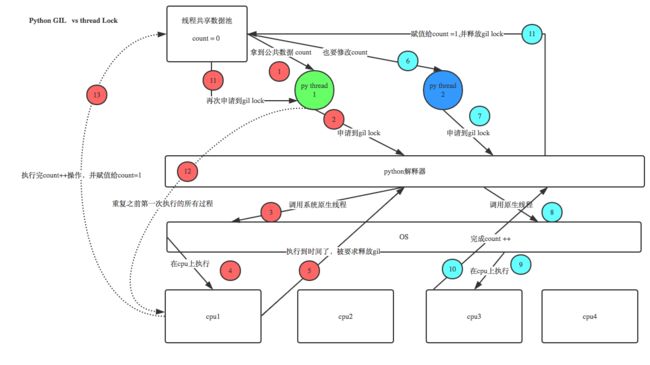
Semaphore(信号量)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import threading
import time
def func(n):
semaphore.acquire()
time.sleep(1)
print("this thread is %s\n" % n)
semaphore.release()
semaphore = threading.BoundedSemaphore(5) # 信号量
for i in range(23):
t = threading.Thread(target=func,args=(i,))
t.start()
while threading.active_count() != 1:
pass
# print(threading.active_count()) #当前存活线程个数
else:print("all threads is done...")
ThreadLocal( 类似C语言中的结构体 )
#encoding: utf-8
import threading
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print 'Hello,{} in {}'.format(std,threading.current_thread().name)
def process_name(name):
# 绑定ThreadLocal的student:
local_school.student = name
process_student()
if __name__ == '__main__':
t1 = threading.Thread(target=process_name, args=('Alice',),name='Thread-A')
t2 = threading.Thread(target=process_name, args=('Bob',),name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
输出:
Hello,Alice in Thread-A
Hello,Bob in Thread-B
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式?
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
下面来学习一个最基本的生产者消费者模型的例子
import threading,time
import queue
q = queue.Queue(maxsize=10)
def Producer(name):
count = 1
while True:
q.put("骨头%s" % count)
print("生产了骨头",count)
count +=1
time.sleep(0.1)
def Consumer(name):
#while q.qsize()>0:
while True:
print("[%s] 取到[%s] 并且吃了它..." %(name, q.get()))
time.sleep(1)
p = threading.Thread(target=Producer,args=("Alex",))
c = threading.Thread(target=Consumer,args=("ChengRonghua",))
c1 = threading.Thread(target=Consumer,args=("王森",))
p.start()
c.start()
c1.start()
生产了骨头 1
[ChengRonghua] 取到[骨头1] 并且吃了它...
生产了骨头 2
[王森] 取到[骨头2] 并且吃了它...
生产了骨头 3
生产了骨头 4
生产了骨头 5
生产了骨头 6
生产了骨头 7
生产了骨头 8
生产了骨头 9
生产了骨头 10
[ChengRonghua] 取到[骨头3] 并且吃了它...
生产了骨头 11
[王森] 取到[骨头4] 并且吃了它...
生产了骨头 12
生产了骨头 13
生产了骨头 14
[ChengRonghua] 取到[骨头5] 并且吃了它...
生产了骨头 15
生产了骨头 16
...
...
...
总结:
Python多线程很适合用在IO密集型任务中。I/O密集型执行期间大部分是时间都用在I/O上,如web应用,数据库I/O,较少时间用在CPU计算上。因此该应用场景可以使用Python多线程,当一个任务阻塞在IO操作上时,我们可以立即切换执行其他线程上执行其他IO操作请求。Python多线程在IO密集型任务中还是很有用处的,而对于计算密集型任务,应该使用Python多进程。