一、引言
我们都知道线程和线程池是Android开发中很重要的一个部分。本文会从Java线程谈起,由浅及深总结在Android中线程和线程池的使用。
java:
线程相关:Thread、FutureTask;(Runalbe、Callable)
线程池:ThreadPoolExecutor;
以下四个是在ThreadPoolExecutor基础上实现的
FixedThreadPool
CachedThreadPool
ScheduledThreadPool
SingleThreadExecutor
Android:
Android除开java基本的线程和线程池,额外提供如下辅助工具。
AsyncTask、HandlerThread、IntentService(他们三个本质是Thread/Handler/ThreadPoolExecutor来实现)、Handler
1.1、简单介绍
Thread是和Runnable结合实现线程、Runnable是个接口,当mThread.start()时,执行Runable中run()方法所写代码块。
FutureTask支持Runable和Callable两种接口。FutureTask产生是因为Runable.run方法只是一个单独的方法。而Callable接口的call方法可以返回结果和抛出异常。FutureTask等于是Runable的继承和扩展。
ThreadPoolExecutor线程池的基本实现,统一管理多个线程、线程池中每个线程执行完毕不会立即销毁,等待下一个任务以达到不会频繁创建销毁的目的,以避免资源浪费,GC等
FixedThreadPool只有核心线程,构造参数设定核心线程数,没有超时机制且排队任务队列无限制,因为全都是核心线程,所以响应较快,且不用担心线程会被回收。
CachedThreadPool只有非核心线程,数量无限,当有新任务来时,若没有空闲线程直接创建新线程执行任务。空闲60s直接销毁
ScheduledThreadPool含构固定数量核心线程,和无限量非核心线程。非核心线程执行完毕时立马回收。
SingleThreadExecutor内部只有一个核心线程,使所有任务顺序执行。
Handler其实就是android的消息机制,也是一种简称,它本身不是线程。Handler、MesageQueue、Looper三者结合来达到延时or指定线程执行任务的目的。
AsyncTask封装了线程池和Handler,最主要特色是方便我们在子线程中更新UI提供便利,以及在线程执行的各个阶段添加自己的处理。
HandlerThread继承自Thread,封装了Handler,所以它是Thread和Handler的结合。这样就可以很方便的调用HandlerThread中的Handler在子线程中执行任务。
IntentService继承自Service,它拥有一个HandlerThread对象,所以它是Service、Thread和Handler的结合。简单来说它是一个拥有HandlerThread特性的Service。
二、线程Thread
2.1、 线程的6个状态
Thread.java里边有这个样一个枚举
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
1、新建状态(New) new一个Thred的时候
2、可运行状态(Runnable) 当thread调用start(),线程位于可运行池中,等待cpu使用权。因为此时cpu可能被优先级较高的线程占用。
3、阻塞状态(BLOCKED) synchronize代码块锁定导致的线程阻塞。暂时停止运行。直到线程再次变成可运行状态,等待cpu使用权。阻塞分为两种
<1>、等待阻塞,运行的线程synchronize代码块中执行Objec.waite方法,jvm把线程放入等待池。
<2>、同步阻塞,运行的线程synchronize在获取对象的同步锁时,若此同步锁被别的线程占用,则jvm会把线程放入等待池
4、等待状态(WAITING),三种情况进入等待状态,直至解锁
{@link Object#wait() Object.wait} with no timeout
{@link #join() Thread.join} with no timeout
{@link LockSupport#park() LockSupport.park}
5、有具体时间的等待状态(TIMED_WAITING),五种情况会发生,直至解锁
{@link #sleep Thread.sleep}
{@link Object#wait(long) Object.wait} with timeout
{@link #join(long) Thread.join} with timeout
{@link LockSupport#parkNanos LockSupport.parkNanos}
{@link LockSupport#parkUntil LockSupport.parkUntil}
6、结束状态(TERMINATED),线程执行完毕
2.2、线程调度
1、优先级,整数1~10
public final static int MIN_PRIORITY = 1;
public final static int NORM_PRIORITY = 5;
public final static int MAX_PRIORITY = 10;
Thread.java默认三个优先级,默认Normal,提供setPriority()和getPriority()方法
2、线程睡眠,Thread.sleep()后阻塞,时间结束后转为就绪
3、线程等待,Object.wait()导致当前线程阻塞,当别的线程调用调用Object.notify()/Object.notifyAll才唤醒
4、线程让步,Thread.yield()暂停当前线程,把机会让给同等级or更高等级的线程。yield并非导致线程等待/阻塞/睡眠,只是转为可运行状态,只是让出优先处理别的。
5、线程加入, Thread.join(),等待线程终止。比如在UI线程添加线程A,A.start()后调用A.join(),主线程会等待A执行结束才会继续执行A.join()之后的代码。
6、线程唤醒,Object.notify(),如果多个线程在同一个object上等待,调用nofity()唤醒线程是他们随机中的一个。
2.3、常用方法
Thread.sleep(): 强迫一个线程睡眠N毫秒。
Thread.isAlive(): 判断一个线程是否存活。
Thread.join(): 等待线程终止。
Thread.activeCount(): 程序中活跃的线程数。
Thread.enumerate(): 枚举程序中的线程。
Thread.currentThread(): 得到当前线程。
Thread.isDaemon(): 一个线程是否为守护线程。
Thread.setDaemon(): 设置一个线程为守护线程。(用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束)
Thread.setName(): 为线程设置一个名称。
Thread.setPriority(): 设置一个线程的优先级。
Object.wait(): 强迫一个线程等待。 和synchronized结合使用
Object.notify(): 通知一个线程继续运行。 和synchronized结合使用
Thread的具体代码实现,最后都直接调用到了native方法,都是JDK平台底层的具体实现了。我们看看Thread.start代码
public synchronized void start() {
if (threadStatus != 0 || started)
throw new IllegalThreadStateException();
group.add(this);
started = false;
try {
nativeCreate(this, stackSize, daemon);
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {}
}
}
private native static void nativeCreate(Thread t, long stackSize, boolean daemon);
其它很多方法就不贴代码了,都类似,最后都调用到了jvm具体的实现,笔者这里就不深究了。
2.4、例子
来个waite notify的demo,经典面试题,三个线程,一个线程只打印A,一个线程只打印B,一个线程只打印C,现在按照顺序输出ABC10次
public class MyThreadPrinter implements Runnable {
private String name;
private Object prev;
private Object self;
private MyThreadPrinter(String name, Object prev, Object self) {
this.name = name;
this.prev = prev;
this.self = self;
}
@Override
public void run() {
int count = 10;
while (count > 0) {
synchronized (prev) {
synchronized (self) {
System.out.print(name);
count--;
self.notify();
}
try {
prev.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
Object a = new Object();
Object b = new Object();
Object c = new Object();
MyThreadPrinter pa = new MyThreadPrinter("A", c, a);
MyThreadPrinter pb = new MyThreadPrinter("B", a, b);
MyThreadPrinter pc = new MyThreadPrinter("C", b, c);
new Thread(pa).start();
Thread.sleep(100); //确保按顺序A、B、C执行
new Thread(pb).start();
Thread.sleep(100);
new Thread(pc).start();
Thread.sleep(100);
}
}
简单解释下
1、synchronized是jvm内置的锁机制。本例是Object对象锁。
2、这段代码理解核心:假定A线程执行到prev.waite时,这个时候阻塞的是线程A;
3、因为一开始a、b、c都没被持有,为了顺序执行所以需要sleep下,以免造成死锁,或者错误循环。
这里科普下synchronized和volatile这两个关键字
synchronized提供了互斥性的语义和可见性,可以通过使用它来保证并发的安全。可作用在对象,方法和代码块上。需要注意的是它的作用域。一类是:作用在static的方法或者synchronized(当前类.class)上时,对所有对象有效,不管new了多少个对象,synchronized包含的内容只能被一个线程持有。其它情况是:只对当前对象有效。
volatile可以看做是一种synchronized的轻量级锁,他能够保证并发时,被它修饰的共享变量的可见性。简单理解就是无论何时或者多少个线程读到的变量都是最新值
三、FutureTask
很多文章里边说FutureTask是线程,其实这个说法是错误的。线程最后统一的执行的是Runable的run方法。FutureTask实现了Runable的run方法,并让run执行过程更富有可控制性。这就是FutureTask的作用。它只是基于Runnable上的继承和扩展。
3.1、FutureTask的组成
public class FutureTask implements RunnableFuture{
public FutureTask(Callable callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
...
}
RunnableFuture extends Runnable, Future {
void run();
}
public interface Runnable {
public abstract void run();
}
public interface Callable {
V call() throws Exception;
}
public interface Future {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
1、Runnable和Callable,FutureTask的最大特色就是它同时实现这两个接口。Runable我们很熟悉就是提供统一的run方法。Callable也很简单,提供统一的call方法,方便返回执行后的结果。
2、Future,FutureTask还额外实现这个接口。Future提供了取消,判断是否取消,get结果等方法。
核心run方法
public void run() {
...
try {
Callable c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
...
}
private Object outcome;
protected void set(V v) {
if (U.compareAndSwapInt(this, STATE, NEW, COMPLETING)) {
outcome = v;
U.putOrderedInt(this, STATE, NORMAL); // final state
finishCompletion();
}
}
1、FutureTask执行run方法就是间接调用构造函数所带入的Callable参数的call方法;
2、并把执行结果用outcome保存起来;
3.2、FutureTask的6个状态
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
1、可以看到状态用volatile关键字修饰,这避免了多个线程访问的问题;
2、6个状态和单词意思差不多,这里不详述;
2、get获取结果的时候,也会根据状态的不同来返回,只有normal时正常返回刚才保存的outcome;
3.3、等待队列
3.3.1、队列阻塞
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
等待队列是FutureTask最后一个组成部分。当我们调用FutureTask.get的时候,如果state还未执行完毕,会进入一个等待处理状态,或者阻塞。直至重新唤醒处理。核心方法:
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
long startTime = 0L; // Special value 0L means not yet parked
WaitNode q = null;
boolean queued = false;
for (;;) {
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING)
// We may have already promised (via isDone) that we are done
// so never return empty-handed or throw InterruptedException
Thread.yield();
else if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
else if (q == null) {
if (timed && nanos <= 0L)
return s;
q = new WaitNode();
}
else if (!queued)
queued = U.compareAndSwapObject(this, WAITERS,
q.next = waiters, q);
else if (timed) {
final long parkNanos;
if (startTime == 0L) { // first time
startTime = System.nanoTime();
if (startTime == 0L)
startTime = 1L;
parkNanos = nanos;
} else {
long elapsed = System.nanoTime() - startTime;
if (elapsed >= nanos) {
removeWaiter(q);
return state;
}
parkNanos = nanos - elapsed;
}
// nanoTime may be slow; recheck before parking
if (state < COMPLETING)
LockSupport.parkNanos(this, parkNanos);
}
else
LockSupport.park(this);
}
}
状态虽多,但处理不复杂。
首先它是一个无限循环直至处理掉或者线程阻塞
1、创建WaitNode,然后用LockSupport来把当前线程锁住
2、COMPLETING,线程让步。>COMPLETING,直接返回状态。
3、线程中断,移除队列返回InterruptedException
4、!queued,放入队列
5、阻塞 LockSupport.park/ LockSupport.parkNanos
3.3.2、队列唤醒
在run执行完毕后,set结果的时候,会调用finishCompletion();方法。就是在这里调用唤醒的。
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (U.compareAndSwapObject(this, WAITERS, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
1、一个for (;;)唤醒队列里所有的线程;
2、完成后调用可扩展方法done;
3.4、例子
FutureTask f = new FutureTask(new Callable() {
@Override
public String call() throws Exception {
for (int i = 10;i>0;i--) {
Thread.sleep(1000);
Log.d("yink","i = " + i + " time = " + System.currentTimeMillis());
}
return "result";
}
});
new Thread(f).start();
try {
Log.d("yink","f.get() time =" + System.currentTimeMillis());
String result = (String) f.get();
Log.d("yink","f.get() result = " + result + " time = " + System.currentTimeMillis());
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
输出如下,省略几个倒计时打印:
D/yink: f.get() time =1486663241
D/yink: i = 10 time = 1486664242
D/yink: i = 9 time = 1486665246
...
D/yink: i = 1 time = 1486673257
D/yink: f.get() result = result time = 1486673258
1、例子很简单延时输出打印
2、当调用get时,调用get的主线程阻塞,直至run运行结束
3、由于代码很简单,主线程没有别的操作,所以这里没报错。实际这样写很容易ANR。比如点击5秒无响应,广播超时等等。故意写这么个例子就是希望读者理解这里是哪个线程阻塞。考虑阻塞会不会带来别的问题。
四、线程池
撸完线程,我们来撸线程池。线程池的作用很明显了,当我们频繁的创建销毁线程,开销是很大的。线程池可以有效的避免重复创建,合理利用cpu资源。新任务也能最快响应而省去创建线程的时间。统一管理合理分配资源。下图是线程池的类结构,线程池的核心就是ThreadPoolExecutor了。
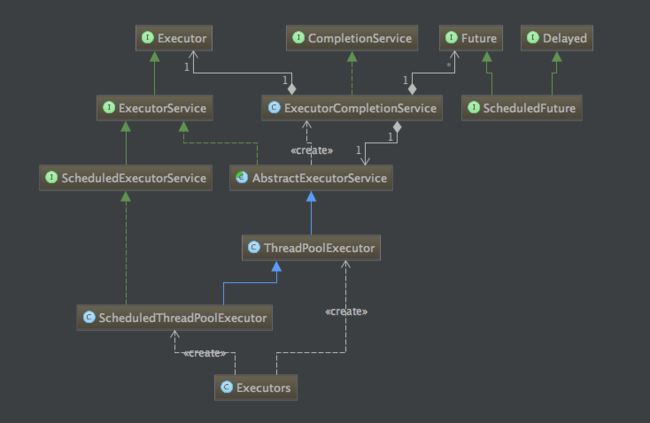
图中ScheduledThreadPoolExecutor是在ThreadPoolExecutor基础上实现的,我们可以先不看。先理解ThreadPoolExecutor。
4.1、ThreadPoolExecutor
4.1.1、构造关系
public class ThreadPoolExecutor extends AbstractExecutorService { ... }
public abstract class AbstractExecutorService implements ExecutorService { ... }
public interface ExecutorService extends Executor {
void shutdown();
List shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
Future submit(Callable task);
Future submit(Runnable task, T result);
Future submit(Runnable task);
List> invokeAll(Collection> tasks)
throws InterruptedException;
List> invokeAll(Collection> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
T invokeAny(Collection> tasks)
throws InterruptedException, ExecutionException;
T invokeAny(Collection> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
public interface Executor {
void execute(Runnable command);
}
1、ThreadPoolExecutor集成抽象类AbstractExecutorService,抽象类实现ExecutorService接口,ExecutorService继承自Executor接口;
2、接口Executor定义了最基本的execute执行任务的方法
3、接口ExecutorService额外定义了shutdown等一系列操作任务的方法
4、抽象类AbstractExecutorService提供了newTaskFor、submit、doInvokeAny、invokeAny、cancelAll,实现了部分逻辑和方法。
5、ThreadPoolExecutor则是线程池的具体实现。
ThreadPoolExecutor的具体实现后边详细描述。关于AbstractExecutorService这里详解最复杂的doInvokeAny方法。doInvokeAny为线程池提供了一个执行一个Callable集合的方法,执行集合内任务时,只要有一个任务执行完毕且有返回结果。就结束所有任务。
private T doInvokeAny(Collection> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
// 集合大小
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
// 创建和集合大小一样的Future(任务结果)的集合LIst
ArrayList> futures = new ArrayList<>(ntasks);
// 它的作用就是额外提供一个BlockingQueue>队列,来记录任务执行完毕后的Future
ExecutorCompletionService ecs =
new ExecutorCompletionService(this);
try {
ExecutionException ee = null;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 迭代器,方便遍历取出下一个元素
Iterator> it = tasks.iterator();
// 取出一个任务,并用ExecutorCompletionService调用submit开始执行任务。
futures.add(ecs.submit(it.next()));
--ntasks;
int active = 1;
// 无限循环
for (;;) {
// ExecutorCompletionService取出队列第一个数据
Future f = ecs.poll();
if (f == null) {
// 取出的执行结果为空,且任务结合还有任务就继续用sbmit提交执行任务
if (ntasks > 0) {
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
else if (active == 0)
break;
else if (timed) {
f = ecs.poll(nanos, NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
else
f = ecs.take();
}
if (f != null) {
--active;
try {
// 取出的结果不为空,说明有执行结果了。返回取出的结果。
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
// 最后取消执行所有任务。
cancelAll(futures);
}
}
1、代码中的ExecutorCompletionService封装了一下FutureTask任务,提供了一个保存Future的队列。只要执行完任务就把结果添加到队列里。下面是ExecutorCompletionService的部分代码
public Future submit(Runnable task, V result) {
if (task == null) throw new NullPointerException();
RunnableFuture f = newTaskFor(task, result);
executor.execute(new QueueingFuture(f, completionQueue));
return f;
}
private static class QueueingFuture extends FutureTask {
QueueingFuture(RunnableFuture task,
BlockingQueue> completionQueue) {
super(task, null);
this.task = task;
this.completionQueue = completionQueue;
}
private final Future task;
private final BlockingQueue> completionQueue;
protected void done() { completionQueue.add(task); }
}
上面doInvokeAny在new ExecutorCompletionService
2、关键理解点就是当submit提交第一个任务后,只有任务执行完毕才有可能返回结果。
3、假设任务执行时间较长,poll方法删除队列第一个元素。因为任务没有执行完毕,所以队列没有元素,poll出来的是null,所以代码循环就会立即提交执行下一个任务。直至所有的任务都提交执行。
4、当有任务执行完毕了,这时任务可能有执行结果,也可能没有执行结果。没有结果的时候poll删除的Future结果本来就是null,所以不影响。有结果的时候poll出来的结果就就return返回。
5、finally最后取消执行所有任务
4.1.2、ThreadPoolExecutor构造函数
从构造函数开始认识ThreadPoolExecutor,代码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
1、corePoolSize 核心线程数,核心线程数还没到corePoolSize时,即使有空闲线程,新任务也会创建新线程;
2、maximumPoolSize最大线程数;
3、keepAliveTime非核心线程存活时间,即非核心线程执行完毕后不会立即销毁,直至时间到达;
4、TimeUnit枚举时间单位;
5、BlockingQueue队列;
6、ThreadFactory线程工厂,用于线程的创建;
7、RejectedExecutionHandler这个接口用来处理这种情况:添加任务失败时,就靠handler来处理。四种处理策略,也就是四种接口实现,
AbortPolicy 默认抛出异常
CallerRunsPolicy用调用者所在的线程来执行任务
DiscardOldestPolicy丢弃阻塞队列中靠最前的任务,并执行当前任务
DiscardPolicy直接丢弃任务
4.1.3、线程池的状态
对线程池大概认识后,我们来看它在运行时的几个状态。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
// 最大数量
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 获取线程池状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 获取线程池数量
private static int workerCountOf(int c) { return c & CAPACITY; }
// 组装状态和数量,返回ctl
private static int ctlOf(int rs, int wc) { return rs | wc; }
1、RUNNING运行状态,创建时的状态;
2、SHUTDOWN停工状态,不接收新任务,已接收的任务会继续执行;
3、STOP停止状态,不接收新任务,接收的和正在执行的也会中断;
4、TIDYING清空状态,所有任务都停止了,工作线程也结束了;
5、TERMINATED终止状态,线程池已销毁;
AtomicInteger是个int型变量,它的高三位用来表示状态,剩下的29位用来表示数量
4.1.4、提交任务
提交任务有两个方法,一个是Executor.execute,一个是AbstractExecutorService.submit
public Future submit(Callable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
public Future submit(Runnable task, T result){ ... }
public Future submit(Runnable task) { ... }
submit的方法都类似、都是封装成FutureTask以提交给execute方法。所以我们接下来看execute方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//检查线程池是否是运行状态,并将任务添加到等待队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//如果线程池不是运行状态,则将刚添加的任务从队列移除并执行拒绝任务
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果工作线程为0,先添加一个worker线程。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 线程池不是运行状态会添加失败,就会执行reject,走拒绝任务的处理任务
else if (!addWorker(command, false))
reject(command);
}
添加的逻辑不复杂,最后逻辑走向两个分支,一个是addWorker添加线程,一个reject拒绝任务处理逻辑先看reject,默认是AbortPolicy拒绝任务的策略,这个策略处理结果是直接抛出rejectedExecution
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
4.1.5、内部类Worker
接着上面addWorker分析之前,我们先认识Worker。它其实就是线程池管理内部任务的最小单位,线程池就是维护的一组Worker。上代码
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
1、AbstractQueuedSynchronizer简称AQS是一个抽象同步框架,可以用来实现一个依赖状态的同步器。可以简单理解为控制线程获取一个统一volatile类型的state变量的Synchronized工具。即同步器
2、构造函数创建一个Thread,和获得Runable这两个核心组件
3、剩下几个常规锁操作方法。由AQS来实现。
于是简单总结Worker就是一个同步器+Thread+Runable的结合
4.1.6、addWorker
接着分析线程池的execute方法中addWorker的代码
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
代码大概三部分
1、先判断状态,如果大于等于SHUTDOWN不执行,返回false
2、然后判断线程数量是否超过核心线程数,或者最大数。没有超过跳出循环走到下半部分代码创建新的worker。
3、在mainLock保护下,创建worker后加入HasSet容器。并启动t.start();
根据上面的worker类的代码可知,t.start调用的是Worker自身的run方法。所以实际调用到了线程池的runWorker方法
4.1.7、runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
1、task.run();之前会检查中断or停止。在run前后可以添加自定义的处理beforExecute(),afterExcute
2、task = getTask()会取出BlockingQueue队列(workQueue)中的任务来执行。
4.1.7、ThreadPoolExecutor小结
这里先对ThreadPoolExecutor做一个小小的总结。整理一下思绪
1、ThreadPoolExecutor主要就是构造函数那几个参数来组成它的功能。记住worker管理线程来执行workerQueue中的task任务。然后有核心线程数、最大线程数。添加失败用RejectedExecutionHandler处理失败逻辑,非核心线程活跃时间keepAliveTime
2、提交任务都是最后走到execute来提交,没有达到核心线程数量,直接走addWorker来创建worker来工作。woker保存在HashSet集合里。添加任务时,如果添加到workQueue队列失败会触发创建非核心线程。如果线程池是running状态但工作线程为0,也会直接触发先创建一个非核心线程来执行
3、addWorker添加线程,保存在HashSet
4、runWorker通过重复取出队列里的task = getTask(),来达到一直执行知道执行完毕的目的
5、getTask没有任务的时候会阻塞并挂起,不会消耗cpu资源。这样worker就等于一直在等任务队列workerQueu队列有新的任务进来。进来就执行
6、至于FixedThreadPool、CachedThreadPool、ScheduledThreadPool、SingleThreadExecutor只是线程池创建时指定了不同的参数,通过java.util.concurrent.Executors的静态方法创建,就不详述了。
7、流程图里的ScheduledThreadPoolExecutor是JDK1.5开始提供的来支持周期性的任务调度。在ThreadPoolExecutor基础上实现。多了一个堆结构队列来管理。有兴趣的读者可以自行分析。
五、写在组后
好了,线程和线程池的知识点讲到这里也差不多了。线程线程池的基本原理我想你也应该很清楚了。希望本文能对你有所帮助。
Read the fucking source code!