下载及处理文件和图片
Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方法和结构(我们称之为media pipeline)。一般来说你会使用Files Pipeline或者 Images Pipeline。
这两种pipeline都实现了以下特性:
1、避免重新下载最近已经下载过的数据;
2、指定存储媒体的位置(文件系统目录,Amazon S3 bucket)图像管道有一些额外的功能来处理图像;
3、将所有下载的图片转换成通用的格式(JPG)和模式(RGB);
4、缩略图生成;
5、检测图像的宽/高,确保它们满足最小限制;
这个管道也会为那些当前安排好要下载的图片保留一个内部队列,并将那些到达的包含相同图片的项目连接到那个队列中。 这可以避免多次下载几个项目共享的同一个图片。
一、使用Files Pipeline
当使用 FilesPipeline ,典型的工作流程如下所示:
1、在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
2、项目从爬虫内返回,进入项目管道。
3、当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
4、当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
二、使用图像管道Images Pipeline
当使用 ImagesPipeline ,典型的工作流程如下所示:
1、在一个爬虫里,你抓取一个项目,把其中图片的URL放入 image_urls 组内。
2、项目从爬虫内返回,进入项目管道。
3、当项目进入 ImagesPipeline,image_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
4、当文件下载完后,另一个字段(images)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 image_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 image_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 images 组中。
使用ImagesPipeline非常类似于使用FilesPipeline,除了使用的默认字段名称不同:您使用image_urls作为项目的图像URL,并将填充图像字段以获取有关下载的图像的信息。
使用ImagesPipeline进行图像文件的优点是您可以配置一些额外的功能,例如生成缩略图,并根据大小对图像进行过滤。
Pillow 是用来生成缩略图,并将图片归一化为JPEG/RGB格式,因此为了使用图片管道,你需要安装这个库。 Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在一些设置里会出现问题,因此我们推荐使用 Pillow 而不是PIL。
下面利用Images Pipeline爬取花瓣网下载想要的图片。
1、新建一个工程,打开cmd,
输入scrapy startproject huaban_imagepipeline
这里的每个文件的含义上一篇文章 scrapy的快速入门(一)已介绍过了,可以自行翻看之前的文章;
2、定制item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class HuabanImagepipelineItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field() # 图片的链接
images = scrapy.Field()
3、爬虫的关键部分——spiders
在spiders的文件下新建一个huaban_spider.py
import scrapy
from ..items import HuabanImagepipelineItem
from scrapy.conf import settings #从settings文件中导入Cookie,这里也可以from scrapy.conf import settings.COOKIE
import requests
import json
import math
from scrapy.http import Request
class HuabanSpider(scrapy.Spider):
name = "huabanSpider"
allowed_domains = ['huaban.com']
query = "张敏"
start_urls = ['http://huaban.com/search/?q=%s' % query]
# 带着Cookie向网页发请求
cookie = settings['COOKIE']
#利用抓包获取必要的参数,这里我用的是postman
headers = {
'cookies': 'uid=21839587; sid=8ckMdriGQD28yFUdISQIqykQwGn.KuxyNV3X2l9A87ShUPD1LLauT6PZdgi4AUm44wZqFXs;',
'X-Requested-With': 'XMLHttpRequest',
}
html = requests.get(start_urls[0], headers = headers).content
infos = json.loads(html)
totalpage = math.ceil(int(infos['pin_count'])/20) #总的页数
#构造每页的链接
def parse(self, response):
for i in range(1, int(self.totalpage) + 1):
page = str(i)
urls = ["http://huaban.com/search/?q={}&page={}".format(self.query, page)]
for url in urls:
yield Request(url, headers = self.headers, meta = {'key':url}, callback=self.parse_image)
#构造每个图片下载的链接
def parse_image(self, response):
item = HuabanImagepipelineItem()
pin_html = requests.get(response.meta['key'], headers=self.headers).content
infos = json.loads(pin_html)
pins = infos['pins']
url_list = []
for pin in pins:
key_id = pin['file']['key']
download_url = "http://img.hb.aicdn.com/" + key_id + "_fw658"
url_list.append(download_url)
item['image_urls'] = url_list
yield item
4、图片管道pipeline
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class HuabanImagepipelinePipeline(ImagesPipeline):
def get_media_requests(self, item, info): # 重写ImagesPipeline get_media_requests方法
'''
:param item:
:param info:
:return:
在工作流程中可以看到,
管道会得到文件的URL并从项目中下载。
为了这么做,你需要重写 get_media_requests() 方法,
并对各个图片URL返回一个Request:
'''
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
'''
当一个单独项目中的所有图片请求完成时(要么完成下载,要么因为某种原因下载失败),
item_completed() 方法将被调用。
'''
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
在自定义ImagePipeline代码中,作为重要的是要重载get_media_requests(self, item, info)和item_completed(self, results, item, info)这两个函数。
1)get_media_requests(self,item, info):
ImagePipeline根据image_urls中指定的url进行爬取,可以通过get_media_requests为每个url生成一个Request;比如:
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
2)图片下载完毕后,处理结果会以二元组的方式返回给item_completed()函数。这个二元组定义如下:
(success, image_info_or_failure)
其中,第一个元素表示图片是否下载成功;第二个元素是一个字典。比如:
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
5、在settings.py中设置条件和属性
# -*- coding: utf-8 -*-
import random
from useragent import Agent #导入请求头,防止被ban
BOT_NAME = 'huabanSpider'
SPIDER_MODULES = ['huaban_imagepipeline.spiders']
NEWSPIDER_MODULE = 'huaban_imagepipeline.spiders'
ITEM_PIPELINES = {
'huaban_imagepipeline.pipelines.HuabanImagepipelinePipeline': 1,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = '%s'%random.choice(Agent.user_agent)
#USER_AGENT = 'huaban_imagepipeline (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 100
# Retry many times since proxies often fail
RETRY_TIMES = 10
# Retry on most error codes since proxies fail for different reasons
RETRY_HTTP_CODES = [500, 503, 504, 400, 403, 404, 408]
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)禁止使用cookie
COOKIES_ENABLED = False
#图片存储路径
IMAGES_STORE='E:\\spider\\pictures\\huaban\\zm'
#存储缩略图
IMAGES_THUMBS = {#缩略图的尺寸,设置这个值就会产生缩略图
'small': (50, 50),
'big': (200, 200),
}
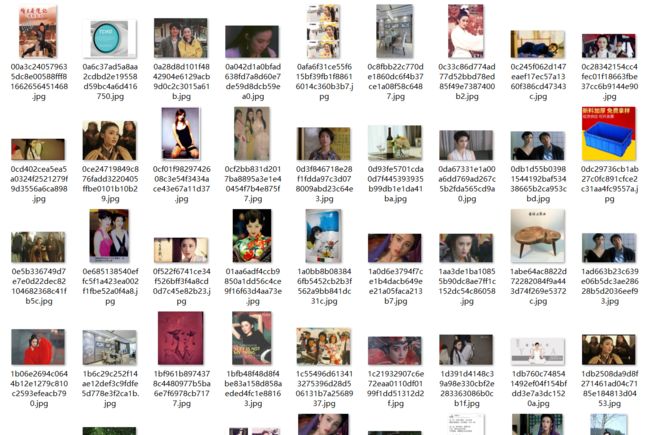
运行结果:
会生成2个文件夹,

full:原图,
thumbs:缩略图,包含2个文件夹:big、small,