1. 同步容器
在早期的JDK中,同步容器有两种现成的实现,Vector和Hashtable,可以直接new对象获取;在JDK1.2中,引入了同步封装类,可以由Collections.synchronizedXxxx等方法创建;这两种方式底层实现都是通过将状态封装起来,并对每个公有方法进行同步,使得每次只有一个线程能访问容器的状态。
以Hashtable为例查看jdk源码实现如下所示:
public synchronized V remove(Object key) {}
public synchronized V put(K key, V value) {}
public synchronized V get(Object key) {}
可以看到Hashtable与普通HashMap的区别就是相应方法都添加了synchronized进行同步,这个保证了容器操作的安全。但是,所有对容器状态的访问都串行化,这种代价就是严重降低了并发性,多个线程竞争的时候,吞吐量严重降低。
2. 并发容器
前面叙述了同步容器使用的局限性,JDK5.0开始增加了ConcurrentHashMap等并发容器来代替同步容器提高多线程并发情况下的性能。下面就其中典型并发容器使用和实现进行介绍:
2.1 ConcurrentHashMap
2.1.1ConcurrentHashMap设计
ConcurrentHashMap采用了分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个Map加锁的设计,分段锁大大的提高了高并发环境下的处理能力。
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应下图可以看出之间的关系:
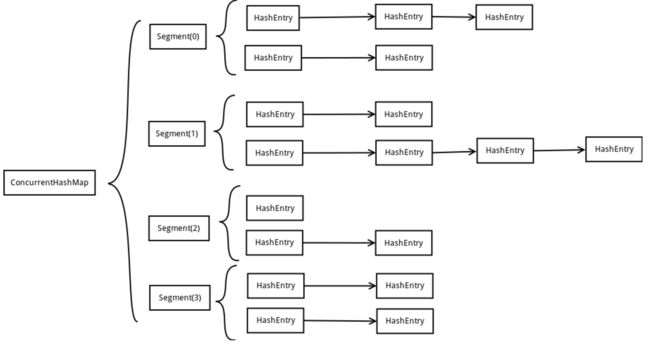
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。由于不同的Segment有各自的锁,理想情况下ConcurrentHashMap可以最高同时支持Segment数量大小的写操作。
2.1.2ConcurrentHashMap常用方法分析
get操作
查看JDK源码整个get操作过程不需要加锁,主要分两步第一步进行再散列,并根据再散列值定位到Segment;第二步找到对应HashEntry并遍历链表找到具体对应值。

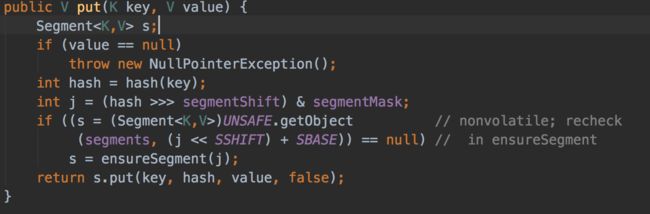
put操作
查看JDK源码put操作,为了线程安全,在操作共享变量时必须加锁。put方法首先定位到Segment,然后在Segment里面进行插入操作。插入操作需要进行两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置,然后将其放在HashEntry数组里。
size操作
前面两个操作都是在单个segment中进行的,但是size操作是在多个segment中进行。ConcurrentHashMap的size操作也采用了一种比较巧的方式,来尽量避免对所有的Segment都加锁。ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计过程中,容器count发生了变化,则采用加锁的方式来统计所有Segment大小。这里ConcurrentHashMap通过判断modCount是否变化来判断容器在计算size过程中是否发生变化。

2.2 CopyOnWrite
CopyOnWrite即写入时复制的容器,每次修改的时,都会创建并重新发布一个新的容器副本,然后新的容器副本里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器,由于当前容器不会被修改所以支持无锁并发读取。
2.2.1 CopyOnWriteArrayList的实现原理
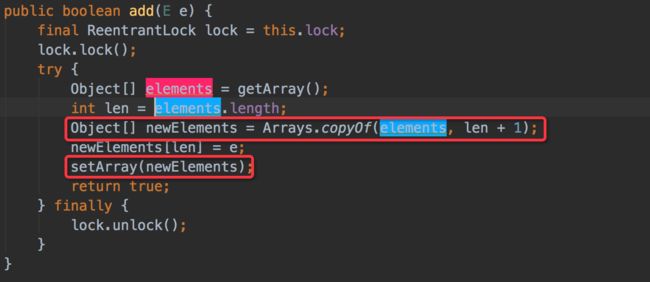
作为CopyOnWrite思想具体实现类CopyOnWriteArrayList,首先看下源码如何实现元素添加修改。可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
同时,读取元素操作非常简单不需要锁如下图所示:

2.2.2使用场景和注意点
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新的场景。
使用注意点:
- 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。
- 根据实际需求初始化容器大小,减少扩容带来的开销。
- 该容器不适合存储占据内存大的大对象由于复制的原因容易引起FullGC
- CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
2.3 并发队列ConcurrentLinkedQueue
在并发编程中需要使用线程安全的队列有两种实现方式一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环CAS的方式来实现。并发队列ConcurrentLinkedQueue通过非阻塞方式实现。
2.3.1 ConcurrentLinkedQueue设计
ConcurrentLinkedQueue 的非阻塞算法实现主要可概括为下面几点:
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。
- head/tail 并非总是指向队列的头 / 尾节点,也就是说允许队列处于不一致状态。 这个特性把入队 /出队时,原本需要一起原子化执行的两个步骤分离开来,从而缩小了入队 /出队时需要原子化更新值的范围到唯一变量。这是非阻塞算法得以实现的关键。
- 以批处理方式来更新head/tail,从整体上减少入队 / 出队操作的开销。
ConcurrentLinkedQueue由head节点和tail节点组成,每个节点(Node)由节点元素(item)和指向下一个节点的引用(next)组成,节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列。默认情况下head节点存储的元素为空,tail节点等于head节点。
3. 阻塞队列
阻塞队列(BlockingQueue)与普通队列的区别在于添加了两个附加操作:当队列是空的时,从队列中获取元素的操作将会被阻塞;当队列是满时,往队列里添加元素的操作会被阻塞。
BlockingQueue最终会有四种状况,抛出异常、返回特殊值、阻塞、超时,下表总结了这些方法:

- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException("Queue full")异常。
- 返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null。
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
3.1 JDK提供阻塞队列
JDK7提供了7个阻塞队列实现类,下面就其中常用类进行分析:
- ArrayBlockQueue:一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。创建其对象必须明确大小,像数组一样。默认情况下不保证访问者公平的访问队列,即不会根据阻塞的先后顺序来提供给访问者。
- LinkedBlockQueue:一个可改变大小的阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。创建其对象如果没有明确大小,默认值是Integer.MAX_VALUE。
- PriorityBlockingQueue:类似于LinkedBlockingQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数所带的Comparator决定的顺序。
- SynchronousQueue:同步队列。同步队列没有任何容量,每个插入必须等待另一个线程移除,反之亦然。即每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。
- DelayQueue:一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
3.2 ArrayBlockQueue实现原理
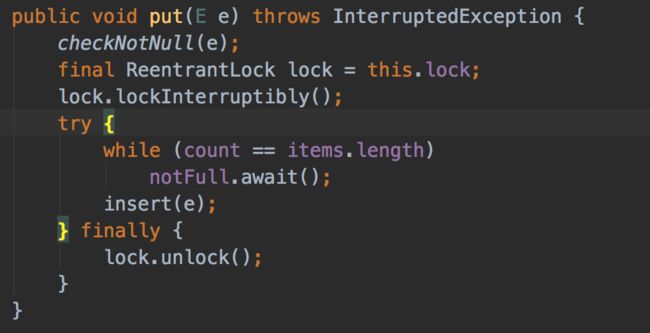
以ArrayBlockingQueue为例我们查看下JDK源码可以发现其主要使用Condition来实现通知模——当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
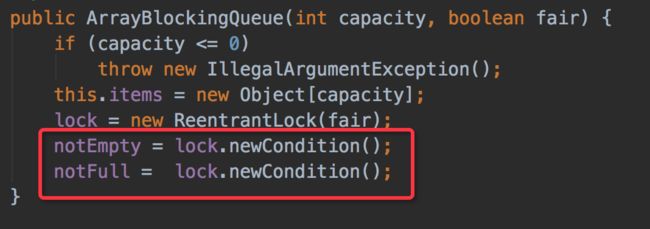
生产者往满的队列里添加元素时会阻塞住生产者
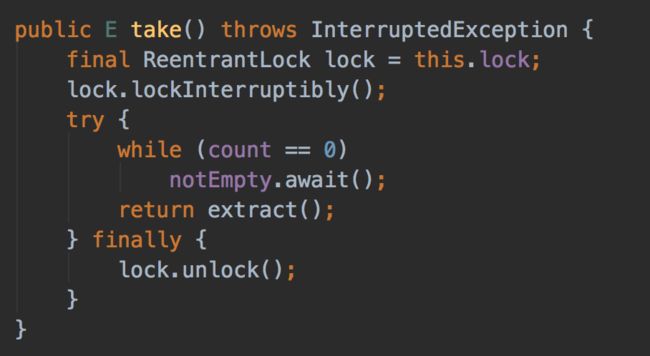
消费者消费空队列的时候会阻塞消费者
3.3 阻塞队列的应用
阻塞队列支持生产者——消费者这种设计模式,当数据产生时候,生产者把数据放到队列当中,而当消费者准备处理数据时,将从队列中获取数据。生产者不需要知道消费者的标识或数量,只需要将数据放入队列即可。同样,消费者也不需要知道生产者是谁。 阻塞队列简化了生产者——消费者设计的实现过程,支持任意数量的生产者和消费者。
参考
http://www.cnblogs.com/dolphin0520/p/3932905.html
http://www.importnew.com/22007.html
http://ifeve.com/java-copy-on-write/
http://ifeve.com/java-blocking-queue/
http://blog.csdn.net/ghsau/article/details/8108292