当一个功能需要对表中的text varchar等文本进行like查询时,MySQL全表扫描很慢,需要sphinx
1.解决性能问题
2.解决中文分词问题

流程:
1.PHP先把要搜索的短语发给sphinx服务器,sphinx服务器返回的是记录的ID
2.PHP用sphinx返回的ID查询数据库

用法一:sphinxse:把sphinx集成到MSQL里去,没有单独的sphinx服务器
PHP只需要写一个sql语句即可,不用用户管sphinx,mysql会自己连接查询sphinx。如果要使用这种,需要在linux下重新编译mysql,把sphinx当成插件编译到mysql中去。
实际操作:
1.先下载sphinx的包,我们下载的是coreseek【coreseek.cn
2:coreseek是一个加了中文的sphinx
3:下载包之后几个重要文件说明

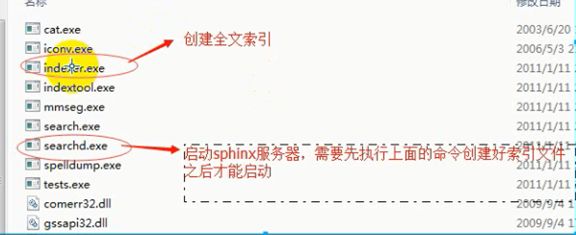
实际应用:将etc文件夹下的csft_mysql.conf,即先复制mysql的配置文件模板到根目录下,并改名为sphinx.conf
以下sql语句要学习下写的不错

配置文件配置好之后就可以使用这个文件生成索引了
#MySQL数据源配置,详情请查看:http://www.coreseek.cn/products-install/mysql/
#请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库
#源定义
#配置数据源(要生成索引的数据)
#说明:一个配置文件中可以定义多个数据源
source goods
{
type= mysql
sql_host= localhost
sql_user= rumble
sql_pass= lumingzhe
sql_db= ushopdata
sql_port= 3306
#sphinx在取数据之前执行的sql语句一般是设置编码的语句set names编码
sql_query_pre= SET NAMES utf8
#一个数据源中只能有一个主查询,这条语句取出的数据就是sphin将要创建全文索引的语句
#主查询的要求:第一个字段必须是ID,如果名字不为ID,取个别名叫id(类型必须是非零唯一、不重复的整数)
#sphinx只能对属性字段排序,sphinx要排序的字段必须取出该字段,sphin排序必须将某个字段定义成一个属性
sql_query= SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title,content FROM documents
#sql_query第一列id需为整数
#后面这些可以不用
#title、content作为字符串/文本字段,被全文索引
#以下是用来定义属性:用来排序的sql_attr_uint可以定义多个比如我要对价格上架时间
#进行排序可以这样操作sql_attr_uint=shop_pricesql_attr_uint=add_time
sql_attr_uint= group_id#从SQL读取到的值必须为整数
sql_attr_timestamp=date_added #从SQL读取到的值必须为整数,作为时间属性
sql_query_info_pre= SETNAMES utf8#命令行查询时,设置正确的字符集
sql_query_info= SELECT* FROM documents WHERE id=$id #命令行查询时,从数据库读取原始数据信息
}
#index定义
#配置索引--》生成的索引文件
#说明:一个数据源对应一个索引的配置
index goods_index
{
source=goods#对应的source名称
#sphinx生成的索引文件存放的目录
#注意:path中的地址的最后一个即data后面的goods是说:索引文件名叫goods
#并不是说goods目录
path= D:\D_E\coreseek-4.1-win32\var\data\goods
#var/data/mysql #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
docinfo= extern
mlock= 0
morphology= none
#允许最短的词
min_word_len= 1
html_strip= 0
#中文分词配置,详情请查看:http://www.coreseek.cn/products-install/coreseek_mmseg/
#charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾
#中文词库在哪中文词库所在的目录
charset_dictpath =D:\D_E\coreseek-4.1-win32\etc
#Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...
charset_type= zh_cn.utf-8
}
#全局index定义
#目前sphin只支持utf8编码
#允许使用多大的内存创建索引文件(indexer.exe这个命令可以使用的内存)
indexer
{
mem_limit= 128M
}
#searchd服务定义
searchd
{
listen=9312
read_timeout= 5
max_children= 30
#最大返回的记录数(即使查询出的记录数量更多也只返回设置的数)
max_matches= 1000
seamless_rotate= 0
preopen_indexes= 0
unlink_old= 1
#以下三个一定要配置,不配置无法用
pid_file =D:\D_E\coreseek-4.1-win32\var\log\searchd_mysql.pid
#var/log/searchd_mysql.pid
log =D:\D_E\coreseek-4.1-win32\var\log\searchd_mysql.log
#var/log/searchd_mysql.log
query_log =D:\D_E\coreseek-4.1-win32\var\log\query_mysql.log
#var/log/query_mysql.log
#请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
binlog_path =#关闭binlog日志
}
说明:indexer.exe命令所在地址–c配置文件所在地址指定生成索引的数据源【比如goods】或者–all【即为所有的数据源生成索引】
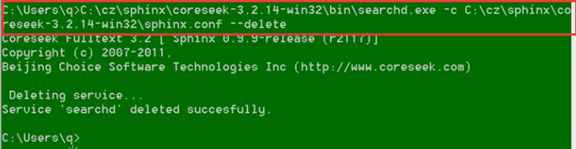
4:启动sphinx服务器
补充:sphinx服务删除
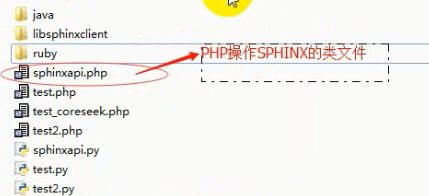
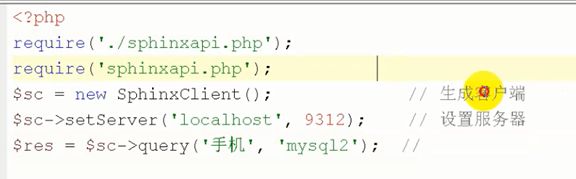
引入sphinx的api的php操作的包这下就可以对中文进行全文索引了
Sphinx自动更新
实际操作:
1:每次生成索引文件之后要把最后一条记录的ID保存下来,下次ID大于这个ID的就是最新的数据。
2:建一张表用来保存这个id
3:
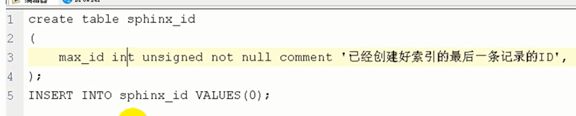
4:配置sphinx让每次生成索引之后能够直接把最大的ID更新进来

定期为新添加的数据生成索引
A:修改sphinx定义一个新的数据源(新插入的数据还没有创建索引)
B:再添加一个index索引(每个数据源对应一个索引文件)
C:写一个bat脚本,让这个定期用新的数据源生成索引文件,并把这个索引文件合并到主索引文件上(第一次生成的索引文件)

D:配置Windows系统让系统定期执行这个bat脚本即可
