第四章 基本数据管理
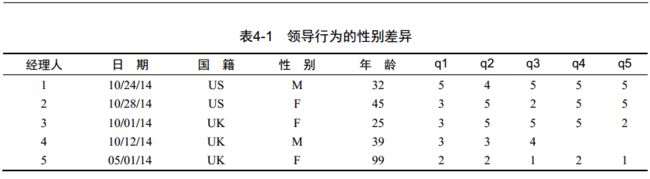
用到的数据
leadership
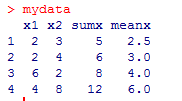
mydata
1. stringAsFactor=FALSE 字符不转换为因子(创建数据框选项参数)
a) 如: > leadership <- data.frame(变量1,变量2,……, stringAsFactors=FALSE)
2. 创建新变量
a) 变量名 <- 表达式
i. 表达式可包含多种运算符和函数
ii. + - * /
iii. X%%Y(求余) X%/%Y(整数除法)
b) 以下得到的为独立变量
i. > sumx <- mydata$x1 + mydata$x2
ii. > meanx <- (mydata$x1 + mydata$x2)/2
c) 将变量整合的原始数据框中
i. 方法1
1. > mydata$sumx <- mydata$x1 + mydata$x2
2. > mydata$meanx <- (mydata$x1 + mydata$x2)/2
ii. 方法2(绑定数据框,简化代码)
1. > attach(mydata)
> mydata$sumx <- x1 + x2
> mydata$meanx <- (x1 + x2)/2
> detach(mydata)
iii. 方法3(使用 transform() )
1. > mydata <- transform(mydata, sumx = x1 + x2, meanx = (x1+x2)/2)
3. 变量的重编码
a) 逻辑运算符
i. < <= > >= ==(严格等于) !=(不等于) x|y(x或y) x&y(x和y)
ii. isTRUE(x) 测试x是否为TRUE
b) 实例
i. 将leadership中的年龄(99)替换为NA,年龄99为错误值
1. leadership$age[leadership$age == 99] <- NA
ii. 将leaderhip中age(连续型变量)重新编码为类别型变量 agecat
1. “Elder”: age >= 66; “Middle Aged”: age >40 & age <66; “Young”: age >= 18 & age <=40;
2. 方法1
a) > leadership$agecat[leadership$age > 66] <- “Elder”
> leadership$agecat[leadership$age > 40 & leadership$age <66] <- “Middle Aged”
> leadership$agecat[leadership$age >= 18 & leadership$age <= 40] <- “Young”
3. 方法2 使用 within()
a) > leadership <- within(leadership, {agecat <- NA
agecat[age>=66] <- “Elder”
agecat[age>40 & age<66] <- “Middle Aged”
agecat[age>=18 & age<=40] <- “Young”})
c) 程序包中的变量重编码函数
i. car包中的 recode()
1. 可以重编码数值型,字符型,向量或因子
ii. doBy包中的 recodevar()
iii. R中自带的 cut()
1. 可以将一个数值型变量按值域切割为多个区间,并返回一个因子
4. 变量的重命名
a) 交互式修改,编辑器
i. fix(object)
b) 编程方法
i. names()
ii. 实例
> names(leadership)[2] <- “testDate” 修改leadership第二列名
>names(leadership)[1:5]<-c(“item1”,”item2”,”item3”,”item4”,”item5”)
leadership 第一到五列分别重名为 item1,…,item5
c) Plyr包中的 rename() 函数
i. > rename(dataframe, c(oldname=”newname”,oldname=”newname”,……))
5. 缺失值 NA
a) NA (Not Avaliable) 在R中数值型和字符型缺失值都用NA表示
i. 缺失值NA判断:is.na(object)
b) 在R中,无限的或者不可能出现的数值不标记为缺失值NA
c) 可使用赋值语句将某些值重新编码为缺失值(如将leadership中年龄99编码为缺失值)
i. 正无穷大:+∞ 识别: is.infinite()
ii. 负无穷大:-∞ 识别: is.infinite()
iii. 不可能出现的值(如2/0):NaN 识别: is.nan()
d) na.rm=TRUE 大多数数值型函数都有此选项,移除缺失值,并使用剩余值进行计算
e) na.omit( ) 移除所有含有缺失值的观测(行),缺失值较少或较集中时使用
6. 日期值
a) 日期值通常以字符串(character)形式输入到R中,然后转化为以数值(numeric)形式存储的日期变量
b) as.Date() 用于执行这种转化
i. as.Date(x, “input_format”) x:字符型向量 input_format:读入日期的格式
ii. 日期值的默认读入格式为:yyyy-mm-dd (如:2018-01-22)
> mydate <- as.Date(c(“2018-01-18”,”2018-01-22”))
因为“2018-01-18”,”2018-01-22”与默认格式相同,直接读入即可
c) 日期格式
符号 含义 实例
%d 两位数表示的日期(01-31) 01 - 31
%a 缩写的星期名 周一
%A 非缩写的星期名 星期一
%m 两位数表示的月份(00-12) 00-12
%b 缩写的月份 一月
%B 非缩写的月份 一月
%y 两位数的年份 18
%Y 四位数的年份 2018
d) 实例:读入日期 “01/05/1991””12/05/1992”
i. > date <- c(“01/05/1991”,”12/05/1992”)
> dates <- as.Date(date, “%m/%d/%Y”)
e) 日期函数
i. Sys.Date() 返回当天日期 如:”2018-01-18”
ii. date() 返回系统当前时间戳 如:”Thu Jan 18 22:11:14 2018”
f) format()
i. format(x, format=”output_format”)
ii. format() 可接受一个参数,并按某种格式输出结果,可用于提取日期值中的某些成分
iii. 实例
1. > today <- Sys.Date()
> format(today, format=”%B%d%Y”)
[1] "一月182018"
> format(today, format=”%A”
[1] "星期四"
iv. R的内部在存储日期时,是使用自1970年1月1日以来的天数表示的,更早的日期用复数表示
1. 因此日期值可以执行算术运算
2. 可使用 difftime() 来计算时间间隔
a) difftime(x1, x2, units=”days”)
b) units: weeks days hour mins secs
c) 实例:计算 Evan 与 HR 生日相差天数
> HR <- c(“1992-12-05”)
> Evan < c(“1991-10-08”)
> difftime(HR, Evan, units=”days”)
Time difference of 447 days
7. 将日期转换为字符型变量(character)
a) as.charavter()
i. > strDates <- as.character(dates)
b) 进行转换后,即可使用一系列字符处理函数(如:取子集,替换,联接等)
c) 查看帮助: help(as.date) help(strftime)
d) 日期和时间格式: help(ISOdatetime)
e) 相关包: lubtidate包 timeDate包
8. 数据类型转换
a) 数据类型
数据符号 数据类型
numeric 数值
character 字符(需带””)
vector 向量
matrix 矩阵
data.frame 数据框
factor 因子
logical 逻辑值
b) 数据类型转换函数
判断 转换
is.numeric() as.numeric()
is.character() as.character()
is.vector() as.vector()
is.matrix() as.matrix()
is.data.frame() as.data.frame()
is.factor() as.factor()
is.logical() as.logical()
is.datetype() as.datetype()
返回逻辑值 TRUE或FALSE 将参数转化为对应的数据类型
9. 数值排序
a) order()
i. 可对一个数据进行排序(默认为升序,在变量前加减号-即可得到降序结果)
ii. 实例
> newdata1 <- leadership[order(leadership$age), ]
> attach(leadership)
> newdata2 <- leadership[order(gender,age), ]
> newdata3 <- leadership[order(gender,-age), ]
> detach(leadership)
10. 数据集的合并
a) 向数据框(data.frame)添加列(变量)和行(观测)的方法
b) 横向合并,向数据框添加列(变量)
i. 横向合并两个数据框(集),即内联结(inner join),merge()
1. merge(x1, x2, by=”c”)
2. x1 x2为数据集,”c”为公共索引(键)
3. 实例
> total1 <- merge(dataframeA, dataframeB, by=”ID”)
> total2 <- merge(dataframeA, dataframeB, by=c(“ID, “country”))
ii. 直接合并两个数据框或矩阵(不需要公共索引),cbind()
1. > total <- cbind(A, B)
a) 对象A,对象B必须拥有相同的行数
b) 且对象A,对象B以同顺序排序
c) 纵向合并,向数据框添加行(观测),rbind()
i. > total <- rbind(dataframeA, dataframeB)
ii. dataframeA dataframeB 必须拥有相同的数量
1. 若dataframeA dataframeB变量不同
a) 删除多余变量
b) 追加变量
11. 数据集取子集
a) 选入(保留)变量
i. dataframe[row indices(行数), column indices(列数) ]
> newdata <- leadership[ , c(6:10)] #选入leadership 6至10列
> myvars <- c(“q1”,”q2”,”q3”,”q4”,”q5”)
> newdata <- leadership[myvars] #选入leadership q1-q5变量(使用变量名称)
ii. paste() 字符连接函数
1. > myvars <- paste(“q”,1:5,sep=””,)
> newdata <- leadership(myvars)
b) 删除(丢弃)变量
i. > myvars <- names(leadership) %in% c(“q3”,”q4”)
> newdata <- leadership[!myvars]
# names(leadership) 生成了一个含有leadership所有变量名的字符型向量
#names(leadership) %in% c(“q3”,”q4”),返回一个逻辑型向量,names(leadership中每个匹配q3或q4的元素的值为TRUE,反正为FALSE
# !myvars 反转myvars 逻辑值
# newdata <- leadership[!myvars] ,选择逻辑值为TRUE的列,即删除 q3 q4(q3, q4逻辑值为FALSE)
c) 选入观测(行)
i. > newdata1 <- leadership[1:3, ] #选入leadership 1至3行
ii. > newdata2 <- leadership[leadership$gender=”M”& leadership$age>30,]
iii. > attach(leadership)
> newdata3 <- leadership[gender=”M”& age>30, ]
>detach(leadership)
iv. 限定时间
> leadership$date <- ad.Date(leadership$date, “%m/%d/%y”) #读入日期
> startdate <- as.Date(“2017-01-01”) #创建开始日期
> enddate <- as.Date(“2017-12-31”) #创建结束日期
> newdata <- leadership[which(leadership$date >= startdate & leadership$date <= enddate), ] #选取满足要求的日期
v. subset()
1. 使用subset() 函数是选择变量和观测的简单方法
2. >newdata1<-subset(leadership,age>=35|age<24, select=c(q1,q2,q3,q4,q5))
>newdata2 <- subset(leadership, gender=”M” & age>25,
select=gender:q4)
d) 随机抽样
i. sample() 可以从数据集中(有放回(raplace=TRUE)或无放回(repalce=FALSE)地抽取一个大小为n的随机样本
1. > mysample <- leadership[sample(1:nrow(leadership), 3, replace=FALSE), ]
ii. sampling包:抽取和校正调查样本
iii. survery包:分析复杂调查数据
iv. 自助法,重新抽样统计方法
12. 使用SQL语句操作数据框
a) SQL: Structured Query Language 结构化查询语言
b) 需要安装 sqldf 包: install.packages(sqldf)
i. 实例1
> library(sqldf)
> newdf <- sqldf(“select * from mtcars where carb=1 order by mpg”,
row.names=TRUE) #row.names=TRUE 延用原始数据框行名
ii. 实例2
> sqldf(“select avg(mpg) as avg_mpg, avg(disp) as avg_disp, gear from
mtcars where cyl in (4,6) group by gear”)