Spring
- spring-core: 核心工具类
- spring-bean: 用于访问配置文件,创建和管理bean
- spring-context: 提供在基础IOC功能上的扩展服务,例如任务调度,邮件服务等
- spring-expression: Spring表达式语言
- com.springsource.org.apache.commons.logging.jar: 第三方的主要用于处理日志
IOC
控制反转:就是将原本在程序中手动创建对象的控制权,交由Spring框架管理。
DI
依赖注入:在Spring框架负责创建Bean对象时,动态的将依赖对象注入到Bean组件,一般通过property
BeanFactory和Applicaton的区别
- BeanFactory:采用延时加载,第一次getBean时才会初始化Bean
- Applicaton: 是对BeanFactory的扩展,采用及时加载,并且提供了很多扩展例如事件传递,国际化处理等
Spring容器装载的三种方式
//Spring容器加载的3种方式
//第一种:ClassPathXmlApplicationContext,后面路径是src路径开始(最常用)
ApplicationContext context=new ClassPathXmlApplicationContext("beans.xml");
//第二种:通过文件系统路径[绝对路径]
//ApplicationContext context=new FileSystemXmlApplicationContext("E:\\WorkSpace\\IDEA\\Demo01\\src\\beans.xml");
//第三种:使用BeanFactory(了解)
// BeanFactory context=new XmlBeanFactory(new FileSystemResource("E:\\WorkSpace\\IDEA\\Demo01\\src\\beans.xml"));
UserServiceImpl userService = (UserServiceImpl) context.getBean("userService");
userService.add();
装配bean的三种方式
public class UserServiceFactory {
public static IUserService createInstance() {
return new UserServiceImpl();
}
public IUserService createInstance2() {
return new UserServiceImpl();
}
}
- 测试方式
@Test
public void test1() {
ApplicationContext context=new ClassPathXmlApplicationContext("beans.xml");
//方式一
// UserServiceImpl userService = (UserServiceImpl) context.getBean("userService");
// userService.add();
//方式二:但是二三方法要注意,spring如果用3.x版本则jdk需要降低到1.7否则报IllegalArgumentException异常
// UserServiceImpl userService2= (UserServiceImpl) context.getBean("userService2");
// userService2.add();
//方式三
UserServiceImpl userService3= (UserServiceImpl) context.getBean("userService3");
userService3.add();
}
bean的作用域(scope)
- singleton
在Spring IOC 容器中仅存在一个Bean实例,Bean以单例方式存在,默认值
- prototype
每次从容器中调用Bean时,都返回一个新的实例,即每次调用getBean()时,相当于执行new XXBean()
- request(了解)
每次HTTP请求都会创建一个新的Bean,该作用于仅适用于WebApplicationContext环境
- session(了解)
同一个HTTP Session共享一个Bean,不同Session使用不同Bean,该作用于仅适用于WebApplicationContext环境
- globalSession(了解)
一般用于Portlet环境,该作用于仅适用于WebApplicationContext环境
bean的生命周期(了解)
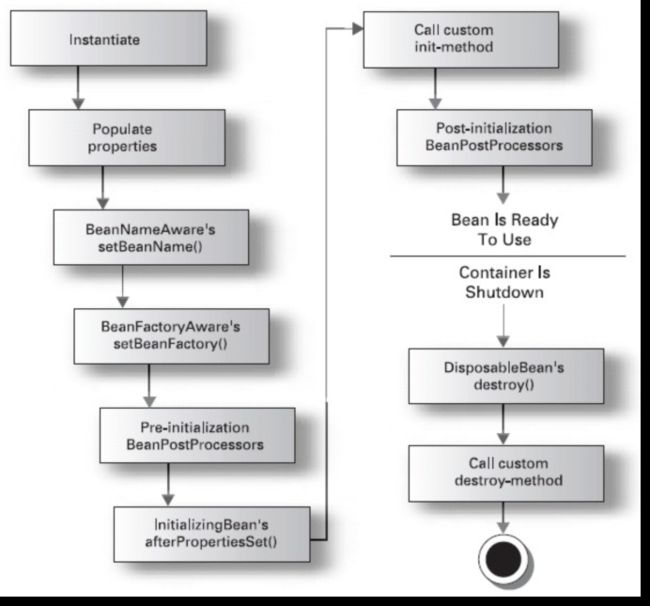
- instantiate bean对象实例化
- populate properties 封装属性
- 如果Bean实现BeanNameAware 执行 setBeanName
- 如果Bean实现BeanFactoryAware 执行setBeanFactory ,获取Spring容器
- 如果存在类实现 BeanPostProcessor(后处理Bean) ,执行postProcessBeforeInitialization
- 如果Bean实现InitializingBean 执行 afterPropertiesSet
- 调用< bean init-method="init"> 指定初始化方法 init
- 如果存在类实现 BeanPostProcessor(处理Bean) ,执行postProcessAfterInitialization
执行业务处理 - 如果Bean实现 DisposableBean 执行 destroy
- 调用< bean destroy-method="customerDestroy"> 指定销毁方法 customerDestroy
参数注入
通过构造方法注入
public class User {
private String username;
private String password;
private int age;
public User(String username, int age) {
this.username = username;
this.age = age;
}
public User(String username, String password) {
this.username = username;
this.password = password;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", password='" + password + '\'' +
'}';
}
}
set方法注入
public class User {
private String username;
private String password;
private int age;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
其他还有通过p命名空间注入值,不细谈(知道即可)
SpEL表达式(了解)
集合注入
集合的注入都是给< property >添加子标签
- 数组:< array>
- List:< list>
- Set:< set>
- Map:< map> map存放k/v键值对,使用< entry>描述
- Properties: < props> < prop key="">< /prop>
ofo
mobai
宝马
小黑
小黄
小白
mysql:jdbc://localhost:3306/dbname
root
123456
哥哥
弟弟
妹妹
姐姐
public Properties getMysqlInfo() {
return mysqlInfo;
}
public void setMysqlInfo(Properties mysqlInfo) {
this.mysqlInfo = mysqlInfo;
}
private Properties mysqlInfo;
说明:Properties类似于Object,打印出来也是类似于map
@Component注解的使用
- @Component取代< bean class="">
- @Component("id")取代< bean class="" id="">
基本案例:
@Test
public void test1() {
/**
* 1.默认Spring不开启注解功能
* 2.需要去.xml中开启注解
*/
ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
//如果@Component没有配置id,则通过类型获取
IUserService service= context.getBean(UserServiceImpl.class);
service.add();
}
说明:
添加xmlns:context="http://www.springframework.org/schema/context"
然后在xsi:schemaLocation中添加
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
这样配置下面的context才有提示
web开发,提供3个@Component注解衍生注解(功能一样)取代< bean class="">
@Repository(“名称”):dao层
@Service(“名称”):service层
@Controller(“名称”):web层
@Autowired:自动根据类型注入,可以用来消除 set ,get方法
@Qualifier(“名称”):指定自动注入的id名称
@Resource(name=“名称”),相当于4,5的综合
@PostConstruct 自定义初始化,相当于init-method
@PreDestroy 自定义销毁,相当于destory-method
@Scope("prototype")多例,默认单例
之所以把@Component细分为三种常用的不同注解,是因为它们的实例化有先后关系,先dao->service->action
基本案例
注解形式
无注解形式,action调用service,service调用dao
注意:对应的java类中,该创建的变量还是要创建,只是Bean的new过程交给Spring执行
注解形式
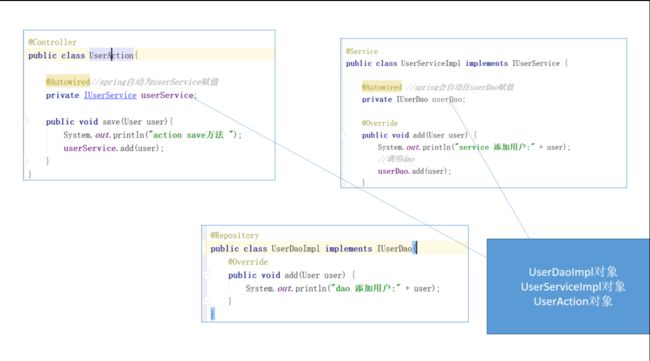
@Controller
@Scope("prototype")//多例,默认单例
public class UserAction{
/**
* Autowired是根据类型注入值
* 如果你是一个接口,从容器找接口实现类
* 如果你就是一个类,就查找类
*/
@Autowired//spring自动注入userService赋值【用的多】
//@Qualifier("myUserService")//根据指定的id注入属性【用的比较少】
//@Resource(name = "myUserService")//等效于前面两行代码【用的比较少】
private IUserService userService;
public void save(User user){
System.out.println("action save方法 ");
userService.add(user);
}
}
说明:因为Service的一个接口一般只对应一个实现,所以@Autowired//spring自动注入userService赋值,也会自动根据类型找到对应的实现然后自动注入,而且和配置文件不同,用了@Auto不需要写set get了,但是如果非要指定对应实现service的id也可以通过 @Qualifier("id")
spring(数据库)事务隔离级别分为四种(级别递减):
1、Serializable (串行化):最严格的级别,事务串行执行,资源消耗最大;
2、REPEATABLE READ(重复读) :保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据。避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”,但是带来了更多的性能损失。
3、READ COMMITTED (提交读):大多数主流数据库的默认事务等级,保证了一个事务不会读到另一个并行事务已修改但未提交的数据,避免了“脏读取”,但不能避免“幻读”和“不可重复读取”。该级别适用于大多数系统。
4、Read Uncommitted(未提交读) :事务中的修改,即使没有提交,其他事务也可以看得到,会导致“脏读”、“幻读”和“不可重复读取”。
脏读、不可重复读、幻读:
也许有很多读者会对上述隔离级别中提及到的 脏读、不可重复读、幻读 的理解有点吃力,我在这里尝试使用通俗的方式来解释这三种语义:
- 脏读:所谓的脏读,其实就是读到了别的事务回滚前的脏数据。比如事务B执行过程中修改了数据X,在未提交前,事务A读取了X,而事务B却回滚了,这样事务A就形成了脏读。
也就是说,当前事务读到的数据是别的事务想要修改成为的但是没有修改成功的数据。
- 不可重复读:事务A首先读取了一条数据,然后执行逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读了。
也就是说,当前事务先进行了一次数据读取,然后再次读取到的数据是别的事务修改成功的数据,导致两次读取到的数据不匹配,也就照应了不可重复读的语义。
- 幻读:事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。
也就是说,当前事务读第一次取到的数据比后来读取到数据条目少。
不可重复读和幻读比较:
两者有些相似,但是前者针对的是update或delete,后者针对的insert。