XML简介
XML常被用于数据存储和传输,其存储结构是树状的,它的重要性来自于以下几点:
- 不同程序之间的通信
- 不同平台之间的通信
- 不同平台之间的数据共享

下面给出一个XML的简单结构
日记
Edwin
99
童话
99
English
03
XML在JAVA中的使用
Java中要获取xml文件的内容有四种解析方式:
DOM:官方提供的解析方式、不需要额外jar包;
SAX:官方提供的解析方式、不需要额外jar包;
DOM4J:其它组织所提供,需要额外的jar包支持;
JDOM:其它组织所提供,需要额外的jar包支持;
DOM方法解析XML:
解析XML属性
public void analyzeXML(){
// 创建DocumentBuilderFactory对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
try {
// 创建DocumentBuilder对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
// 通过DocumentBuilder的parse(String FileName)方法解析XML文件
Document document = documentBuilder.parse("./XMLLearningFolder/Book.xml");
NodeList bookList = document.getElementsByTagName("book");
for (int i = 0;i 除了NamedNodeMap attrs = book.getAttributes();获取所有属性依次遍历外,还可以通过强制转换node到element来使用element中的方法获取属性值。
// 用element的方法输出:
Element elementBook = (Element)bookList.item(i);
String attrValue = elementBook.getAttribute("id");
System.out.println("id:"+attributeString);
解析XML子节点
// 用node中的getChildNodes获得所有子节点
NodeList childNodes = book.getChildNodes();
// 子节点中包括换行符等,解析中也视为子节点
System.out.println("No."+ (i+1) +"book has " +childNodes.getLength()+" childNodes");
for (int j = 0; j 
所以对应的输出结果为:
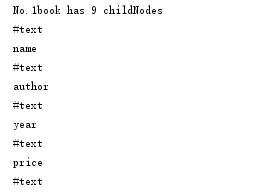
通过上面的表格可以看出,element节点无法获取value值,因为它只识别标签,对标签内部的内容不作解析,所以要获取内容的解析方式:
for (int j = 0; j 区别:
当XML文件内容如下:
...
aa日记
...
输出:
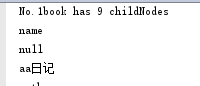
因为getFirstChild获取了element 所以value 为null。
SAX方法解析XML
// 获取SAXParserFactory实例
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
try {
// 通过factory获取SAXParser实例
SAXParser saxParser = saxParserFactory.newSAXParser();
// 创建SAXParserHandler对象
SAXParserHandler handler = new SAXParserHandler();
saxParser.parse("./XMLLearningFolder/Book.xml",handler);
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e){
e.printStackTrace();
}
在调用parse时:saxParser.parse("./XMLLearningFolder/Book.xml",handler);
因为参数需要DefaultHandler,所以要创建一个继承DefaultHandler的类
package pres.edwin.usingXML;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* Created by Edwin_1993 on 2017/8/18.
*/
public class SAXParserHandler extends DefaultHandler{
/**
* 用于遍历xml文件的开始标签
* @param uri
* @param localName
* @param qName 标签名
* @param attributes
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if (qName.equals("book")){
// 已知属性名称是id:
String value = attributes.getValue("id");
System.out.println("book id :" + value);
// 不知道属性名称和个数:
int attributeNum = attributes.getLength();
for (int i = 0; i < attributeNum; i++) {
System.out.println("book attribute NO."+(i+1)+ " name :"+attributes.getQName(i) + "value:"+attributes.getValue(i));
}
}else if (!qName.equals("bookstore")){
// 层层递归到内部的其他节点
System.out.println("节点名" + qName );
}
}
/**
* 用于遍历xml文件的结束标签
* @param uri
* @param localName
* @param qName
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
// 添加针对的节点名:
if (qName.equals("book")){
System.out.println("----end----");
}
}
/**
* 标识解析开始
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("SAX analyze start");
}
/**
* 标识解析结束
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("SAX analyze end");
}
/**
* 获取节点内的具体内容
* @param ch 节点中所有内容
* @param start
* @param length
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
// 同样,所有的回车等也会被认为是值进行获取
String value = new String(ch,start,length);
// 通过trim()去除所有的空格回车
if (!value.trim().equals("")){
System.out.println("节点值"+value);
}
}
}
JDOM方法解析XML
与上面所提到的两种解析方式不同,JDOM解析非JAVA官方所提供,需要添加JDOM包
实现方式及说明:
SAXBuilder saxBuilder = new SAXBuilder();
// 将xml文件作为输入流进行引入
InputStream in = null;
try {
in = new FileInputStream("./XMLLearningFolder/Book.xml");
org.jdom2.Document document = saxBuilder.build(in);
// 如果有乱码 需要在读入的时候选择解析的字符集
// InputStreamReader inWithCode = new InputStreamReader(in,"UTF-8");
// org.jdom2.Document document = saxBuilder.build(inWithCode);
// document对象用于获取xml根节点
Element rootElement = document.getRootElement();
List bookList = rootElement.getChildren();
for (Element book :bookList){
System.out.println("开始解析第"+ (bookList.indexOf(book) + 1)+"本书。");
// 获取内部属性(清楚内部的属性数量和名字):
// book.getAttributeValue("id");
// 获取内部属性(不清楚内部的属性数量和名字):
List attributeList = book.getAttributes();
for (Attribute attribute:attributeList){
System.out.println(attribute.getName() + "---" + attribute.getValue());
}
// 便利内部子节点:
List bookChildList = book.getChildren();
for (Element element : bookChildList){
System.out.println("节点名:" + element.getName() + "--节点值:"+ element.getValue());
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
DOM4J方法解析XML
DOM4J也需要引入Jar包
具体实现及说明:
// 创建SAXReader
SAXReader saxReader = new SAXReader();
try {
org.dom4j.Document document = saxReader.read(new File("./XMLLearningFolder/Book.xml"));
// 获取document的根节点
org.dom4j.Element bookStore = document.getRootElement();
// 通过elements的elementIterator 获取迭代器
Iterator iterator = bookStore.elementIterator();
while(iterator.hasNext()){
org.dom4j.Element book = (org.dom4j.Element)iterator.next();
List bookAttributes = book.attributes();
for (org.dom4j.Attribute attribute : bookAttributes){
System.out.println(attribute.getName()+"---"+attribute.getValue());
}
Iterator innerIter = book.elementIterator();
while (innerIter.hasNext()){
org.dom4j.Element bookChild = (org.dom4j.Element)innerIter.next();
System.out.println(bookChild.getName()+"----"+bookChild.getStringValue());
}
}
} catch (DocumentException e) {
e.printStackTrace();
}
四种解析方式的对比
DOM:一次性加载xml文件进入内存,树状结构便于解析与修改。
SAX:基于事件的解析方式,对内存的消耗比较少,触发例如startelement endelement。适用于只处理xml中的数据。
JDOM:使用集体类而不使用接口。
DOM4J:JDOM的智能分支,使用接口类与抽象基本方法类,优点很多。使用范围非常广。
四种XML的生成方式
DOM
public void createXMLByDOM(){
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
org.w3c.dom.Document domDocument = documentBuilder.newDocument();
domDocument.setXmlStandalone(true);
org.w3c.dom.Element bookStore = domDocument.createElement("bookStore");
// 添加子节点
org.w3c.dom.Element book = domDocument.createElement("book");
org.w3c.dom.Element bookName =domDocument.createElement("name");
bookName.setTextContent("书名为。。。");
book.appendChild(bookName);
book.setAttribute("id","1");
bookStore.appendChild(book);
// 添加根节点
domDocument.appendChild(bookStore);
// 将现有DOM树转为xml文件
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
// 设置输出格式,INDENT 换行
transformer.setOutputProperty(OutputKeys.INDENT,"yes");
transformer.transform(new DOMSource(domDocument),new StreamResult(new File("XMLLearningFolder/newDomBooks.xml")));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}

SAX
public void createXMLBySAX(){
// 创建TransformerFactory对象
SAXTransformerFactory saxTransformerFactory = (SAXTransformerFactory) SAXTransformerFactory.newInstance();
try {
// 创建TransformerHandler对象
TransformerHandler transformerHandler = saxTransformerFactory.newTransformerHandler();
// 创建transformer对象
Transformer transformer = transformerHandler.getTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING,"utf-8");
transformer.setOutputProperty(OutputKeys.INDENT,"yes");
// 创建result对象
File outFile = new File("XMLLearningFolder/newSAXBooks.xml");
if (!outFile.exists()){
outFile.createNewFile();
}
Result result = new StreamResult(new FileOutputStream(outFile));
// 将result对象与Handler关联
transformerHandler.setResult(result);
// 打开document
transformerHandler.startDocument();
AttributesImpl attributes = new AttributesImpl();
// 创建节点,startElement endElement 一一对应。
transformerHandler.startElement("","","bookStore",attributes);
attributes.clear();
attributes.addAttribute("","","id","","1");
transformerHandler.startElement("","","book",attributes);
// book内部节点创建
attributes.clear();
transformerHandler.startElement("","","name",attributes);
String tempString = "书名为。。";
transformerHandler.characters(tempString.toCharArray(),0,tempString.length());
// 依次结束节点
transformerHandler.endElement("","","name");
transformerHandler.endElement("","","book");
transformerHandler.endElement("","","bookStore");
// 关闭document
transformerHandler.endDocument();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}

注意几个方法的顺序:
- (可选)setOutputProperty
- transformerHandler.setResult(result);
- transformerHandler.startDocument();
- transformerHandler.endDocument();
DOM4J
DOM4J生成RSS格式的XML文件
public void createXMLByDOM4J(){
// document相当于整个xml文件
org.dom4j.Document document = DocumentHelper.createDocument();
// 创建根节点
org.dom4j.Element rss = document.addElement("rss");
// 添加属性
rss.addAttribute("version","2.0");
// 生成子节点
org.dom4j.Element channel = rss.addElement("channel");
org.dom4j.Element title = channel.addElement("title");
title.setText("国内新闻");
// 设置格式
OutputFormat outputFormat = OutputFormat.createPrettyPrint();
// outputFormat.setEncoding("GBK");
// 生成xml文件
File outFile = new File("XMLLearningFolder/newDOM4JXML.xml");
try {
XMLWriter writer = new XMLWriter(new FileOutputStream(outFile),outputFormat);
// 设置是否转义,默认值是true
writer.setEscapeText(false);
writer.write(document);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}

JDOM
public void createXMLByJDOM(){
// 生成根结点
Element rootElement = new Element("rss");
rootElement.setAttribute("version","2.0");
Element channel = new Element("channel");
rootElement.addContent(channel);
Element title = new Element("title");
title.setText("<内容内容>");
channel.addContent(title);
// 节点间存在特殊字符转义,需要处理。
Element context = new Element("context");
context.addContent(new CDATA("<内容内容>"));
channel.addContent(context);
// 生成document
Document document = new Document(rootElement);
Format format = Format.getCompactFormat();
format.setIndent("");
// format.setEncoding("gbk");
// 生成XMLOutputter 将document转为xml
XMLOutputter xmlOutputter = new XMLOutputter(format);
try {
xmlOutputter.output(document,new FileOutputStream(new File("XMLLearningFolder/newJDOMXML.xml")));
} catch (IOException e) {
e.printStackTrace();
}
}

四种生成方法的对比:
DOM:基于tree,DOM树驻留内存,改动方便
SAX:基于事件,修改不易。
JDOM DOM4J:基于底层API