说明:
- 接上次试验:
- 505-实验记录
本次试验说明
- 使用了不同的上次的网络,本次试验使用的是cifar10网络
- 进行了两次试验,主要是修改了图片大小
试验1
数据集说明:
| 序号 | 切割图像大小 | train(张) | test(张) |
|---|---|---|---|
| 1 | 11*11 | 3101136 | 539328 |
| 2 | 7*7 | 1831500 | 333000 |
网络以及参数说明:
试验一(11*11):
cifar10_quick_train_test.prototxt
由于原来的cifar处理的图片大小是3232的,而试验用的图片大小是1111大小的,所以将除了第一层意外的
所有层的kernel_size都设置为3,并且删除了pool3层,以防止提取特征到最后某层的时候feature_map变
为0
修改了权重初始化参数weight_filler为** 'xavier' **,理由就是,真的很玄学,看经验贴得来的。
name: "Retina_CIFAR10_quick"
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
data_param {
source: "data/train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
data_param {
source: "data/test_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
std: 0.0001
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "conv3"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 64
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 2
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
cifar10_quick_solver.prototxt
net: "cifar10_quick_train_test.prototxt"
test_iter: 1100
test_interval: 500
base_lr: 0.001
lr_policy: "step"
gamma: 0.01
stepsize: 500000
display: 500
max_iter: 2000000
momentum: 0.9
weight_decay: 0.0005
snapshot: 100000
snapshot_prefix: "retina_cifar_11_train"
solver_mode: GPU
- 相应的deploy文件如下:
cifar10_quick.prototxt
name: "CIFAR10_quick_test"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 11 dim: 11 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 3
stride: 1
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 3
stride: 1
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
name: "CIFAR10_quick_test"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 11 dim: 11 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 3
stride: 1
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 3
stride: 1
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "conv3"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 64
}
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 2
}
}
layer {
name: "result"
type: "Softmax"
bottom: "ip2"
top: "result"
}
- 最后,是我训练的caffemodel:点击我获取model
- 试验获得的准确率得到了93%,效果还是不错的
试验预测效果图

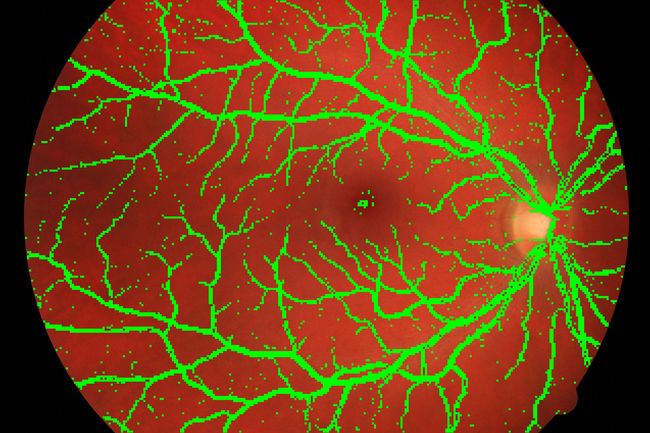
试验二(7*7)
- cifar10_quick_train_test.prototxt :点击下载并查看
- cifar10_quick_solver.prototxt :点击下载并查看
- cifar10_quick.prototxt : 点击下载并查看
- caffemodel :点击下载
- 说明:
同样用的是cifar网络,不同的是,我将所有的pooling层都删除了
-
试验效果图:
 7*7效果图1
7*7效果图1
 7*7效果图2
7*7效果图2
总结
- 试验效果已经比较好了,现在需要考虑的是和实验室中其他师兄的试验结合起来
- 本实验终止更新