需求说明:在一个大list src(60w个)中找出含有 小list oth(10w)的值去掉,返回结果为,在src中含有且在oth中不含有的值的集合。
先上代码:
package com.suyl.designpattern;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.*;
@RunWith(SpringRunner.class)
@SpringBootTest
public class RemoveAllProfile {
@Test
public void test() {
// 构建 大list 60w
long a = System.currentTimeMillis();
List src =new ArrayList(600001);
for (int i =0; i <600000; i++) {
src.add(i);
}
// 构建 大list 6w
long b = System.currentTimeMillis();
List oth =new ArrayList(60001);
for (int i =0; i <600000; i++) {
if (i %10 ==1) {
oth.add(i);
}
}
long c = System.currentTimeMillis();
List result =removeAll(src, oth);// 高效方法
long d = System.currentTimeMillis();
System.out.println(b - a +"ms src" + src.size() +"个");
System.out.println(c - b +"ms oth" + oth.size() +"个");
System.out.println(d - c +"ms result" + result.size() +"个");
List res =new ArrayList();
src.removeAll(oth);// 使用自带 removeAll普通方法
long e = System.currentTimeMillis();
System.out.println(e - d +"ms res" + src.size() +"个");
}
/**
* 高效方法
*
* @param src
* @param oth
* @return
*/
public static List removeAll(List src, List oth) {
LinkedList result =new LinkedList(src);// 大集合用LinkedList
HashSet othHash =new HashSet(oth);// 小集合用HashSet
Iterator iterator = result.iterator();// 采用Iterator迭代器进行数据操作
while (iterator.hasNext()) {
if (othHash.contains(iterator.next())) {
iterator.remove();
}
}
return result;
}
}
结果截图:
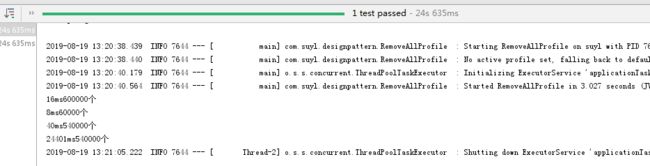
比较一下两种实现方式,为什么差距这个大。
1、外层循环
一个是普通的for循环,一个迭代器遍历元素,二者相差不大
2、内层数据比较
前者通过index方法把整个数组顺序遍历了一遍;
后者调用HashSet的contains方法,实际上是调用HashMap的containKey方法,查找时是通过hash表查找,复杂度为O(1)。
接下来我们简单看一下hash表。
hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。可以简单理解为,以空间换时间,牺牲空间复杂度来换取时间复杂度。
hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为hash函数,而通过hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为hash地址。
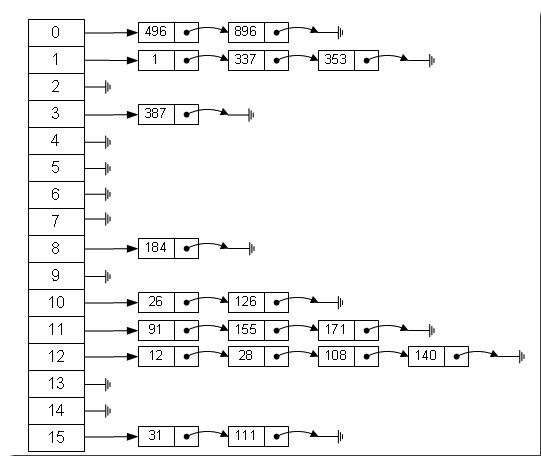
上面的图大家应该都很熟悉,hash表的一种实现方式,是由数组+链表组成的。元素放入hash表的位置通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。
另外hash表大小的确定也很关键,如果hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
参考:https://m.jb51.net/article/117750.htm