
大数据文摘出品
来源:pair-code.github
作者:Andy Coenen等
编译:刘佳玮、万如苑、龙心尘
本文是论文(Visualizing and Measuring the Geometry of BERT)的系列笔记的第一部分。这篇论文由Andy Coenen、Emily Reif、Ann Yuan、Kim、Adam Pearce、Fernanda Viegas和Martin Wattenberg撰写。
近日,谷歌大脑负责人Jeff Dean在推特上安利了一篇文章☟

.
这篇文章是为了补充解释论文,大致呈现了主要的结论。请参阅论文以获得完整的参考文献和更多信息。

论文地址:
https://arxiv.org/abs/1906.02715
语言是由离散结构构成的,而神经网络是在连续数据——高维空间的向量——上运算的。一个成功的语言处理网络必须将这些符号信息转换成某种几何形式来表示——但是是以什么形式呢?词嵌入(Word Embedding)提供了两个众所周知的样例:用距离来编码语义相似性,而某些方向则对应词语的极性(例如男性和女性)。
最近一项惊人的发现指向了一种全新的表示形式。句子的句法结构是句子语言信息的一个重要组成部分。这个结构可以用树来表示,它的节点则对应于句子中的单词。休伊特(Hewitt)和曼宁(Manning)在《一种用于在单词表示中查找语法的结构探针》中指出,一些语言处理网络构造了这种语法树的几何副本。而单词是在高维空间中给定的位置,并且(经过一定的转换)这些位置之间的欧氏距离(Euclidean distance)可以映射到树的距离。
但这一发现带来了一个有趣的难题。树的距离与欧氏距离之间的映射不是线性的。相反,休伊特和曼宁发现树的距离对应着欧氏距离的平方。他们于是提出了为什么需要平方距离,以及是否存在其他可能的映射的问题。
这篇短文为这个难题提供了一些可能的答案。我们证明了从数学的角度来看,树映射的平方距离是特别自然的。甚至某些随机的树嵌入也遵循近似的平方距离定律。而且,只要知道平方距离关系,我们就可以对嵌入树的整体形状给出一个简单、明确的描述。
我们通过分析和可视化一个网络(BERT)中的真实世界的嵌入,以及它们如何系统地不同于它们的数学理想化状态来完善这些观点。这些经验性的发现提出了一种新的定量的方法来思考神经网络中的语法表示。(如果你只是为了看经验结果和可视化效果,请直接跳到这一节。)
树嵌入理论
如果你要把一棵树嵌入欧氏空间,为什么不让树的距离直接对应于欧氏距离呢?一个原因是,如果树有分支,就不可能等构地(isometrically)实现。

图1所示。你不能等构地把这棵树嵌入欧氏空间
事实上,图1中的树是一个标准示例,它表明并不是所有度量空间都可以等构地嵌入到R^n其中。因为d(A,B)=d(A,X)+d(X,B), 在任何嵌入中,A,X, B都是共线的。同理,A,X,C是共线的。但这意味着B=C,这就矛盾了。所以并不是所有度量空间都可以等构地嵌入到R^n其中。
如果一棵树有任何分支也包含一个类似图一示例的结构,则它也不能被等构地嵌入。
毕达哥拉斯嵌入
译注:毕达哥拉斯是古希腊数学家,证明了勾股定理,在西方称作毕达哥斯拉定理。
相比之下,平方距离嵌入结果非常好,以至于我们可以直接给它命名。这个名字背后的原因很快就会揭晓。
定义:毕达哥拉斯嵌入
设M是一个度量空间,其距离度量是d。我们说f:M→R^n 是一个毕达哥拉斯嵌入,如果所有属于M的x, y满足d(x,y)=∥f(x)−f(y)∥^2。
图1中的树是否嵌入了毕达哥拉斯嵌入?答案是显然的:如图2所示,我们可以为一个单位立方体的相邻顶点分配树的结点,而勾股定理给出了我们想要的结果。

图2。嵌入到单位立方体顶点中的简单毕达哥拉斯嵌入。
那么其他的更小的树呢,比如一个由四个顶点组成的链?这也可以通过一个简洁的毕达哥拉斯嵌入到立方体的顶点。

图3。一个由四个点组成的链也通过一个毕达哥拉斯嵌入进了一个单位立方体的顶点中。
这两个例子并不是巧合。实际上,这很容易写出一个显式的毕达哥拉斯嵌入,使任何树都可以被嵌入到一个单位超立方体的顶点中。
定理1.1
任何具有n节点的树都有一个毕达哥拉斯嵌入到R^(n-1)中。
证明:
我们已经知道,类似于定理1.1的论证出现在Hiroshi Maehara的《有限度量空间的欧几里德嵌入》文章中。
设树T的节点为t0,…,tn - 1,且 t0为根节点。让{e1,……,en - 1}为R^n−1维的正交单位基向量。 归纳来说,定义一个嵌入f:T→R^n−1通过

给定两个不同的树节点x和y, 其中m是树的距离d(x,y)我们可以用m个相互垂直的单位基向量从f(x)跳跃到f(y), 因此∥f(x)−f(y)∥^2=m=d(x,y)。
另一种理解这个结构的方法是我们给每条边分配了一个基向量。为了计算出节点的嵌入,我们回到根节点并将经过的所有边向量相加。请参阅下面的图。
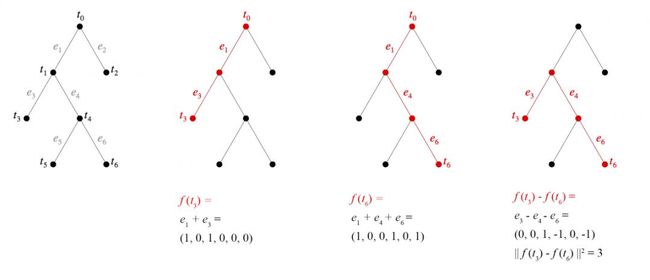
图4。左图:给边分配基向量。中间两图:两个嵌入示例。右图:距离的平方等于树的距离。
附注
这种证明的价值不仅在于结果本身,而且在于其能够显式地几何构造出一个结果。任何同一树结构的两个毕达哥拉斯嵌入都是等构的,并且通过旋转或反射相互关联,每对点之间的距离在这两种情况下都是相同的。我们可以说这是树结构的毕达哥拉斯嵌入,这个定理清楚地告诉我们它的结构是什么样的。
此外,定理1.1中的嵌入有一个清晰的非正式描述:在图中的每个嵌入顶点上,所有到相邻顶点的线段都是彼此正交的单位距离线段,并且与每条边都正交。如果你查看图1和图2,你会看到它们符合是这个描述的。
我们也很容易看到在证明中构造的特定嵌入是一个l^1度量中等构的树,尽管这很大程度上依赖于轴对齐。
我们可以对定理1.1做一个简单的推广。考虑有边权值的树,与两个节点之间的距离是它们之间最短路径的边权值之和。在这种情况下,我们也总是可以创建一个毕达哥拉斯嵌入。
定理1.2
任何有n个节点的加权树都有一个嵌入到R^n - 1中的毕达哥拉斯嵌入。
证明:
如前所述,设树的节点为t0,…,tn - 1, t0为根节点。让{e1,……,en - 1}为R^n−1维的正交单位基向量。 现在,使wi=d(ti,parent(ti)). 归纳来说,定义一个嵌入f,也就是

定理1.2中的嵌入不再存在于单位超立方体上,而是存在于它的压缩版本中:一个边长为{wi^(1/2)}的矩形实体。
我们可以对树结构的边进行索引,每条边都具有与该边上的子节点相同的索引。设P为x和y之间最短路径上的边的指标集,则
∥f(x)−f(y)∥^2=∑i∈P wi=d(x,y)[jg2]
尽管嵌入定理1.2是轴对齐的,也不再是一个ℓ1度量下的等构体。然而,如果我们使用向量wiei而不是wi^(1/2)ei则可以使其恢复一个ℓ1度量下的等构体。
替代嵌入,以及缺乏替代嵌入
休伊特和曼宁问是否可能存在其他有效的树嵌入类型,也许答案是基于欧几里德度量的其他幂。我们可以提供一些关于这类嵌入的部分结论。
定义
设M是一个度量空间,度规d,我们说f:M→Rn是一个幂为p的嵌入,如果对于所有x,y∈M,我们有

结果表明,在不同的术语下,一般度量空间下幂为p的嵌入已经被研究了几十年。其中奠基之作是勋伯格1937年的一篇论文。那篇论文的一个关键结果,用我们的术语来说,就是如果一个度规空间X有一个幂为p的嵌入到Rn中,那么它也有一个幂为q的嵌入对于任意q>p。因此,对于p>2,任何树都有一个幂为p的嵌入。与p=2的情况不同,我们尚不知道怎样用一种简单的方法来描述这种嵌入的几何形状。
另一方面,事实证明,当p <2时,p次幂树嵌入不一定存在。
定理二
对于任意p <2,存在一棵没有p次幂嵌入的树。
详细证明请参阅我们的论文。总结一下这个想法,对于任何给定的p <2,没有足够的“空间”来嵌入具有足够多子节点的树的节点。
随机分支嵌入是毕达哥拉斯嵌入的近似
毕达哥拉斯嵌入的属性十分强大,至少在维度上远高于树形结构。(在用于NLP的神经网络激活函数中就是这样。)在上面的证明中,我们可以完全随机地选择n个向量,而不是使用来自Rm中的单位高斯分布e1,...,en-1∈Rn-1中的基向量。如果m远大于n,很可能结果是近似的毕达哥拉斯嵌入。
原因在于,在高维中,(1)从单位高斯分布提取的向量长度接近1的概率很高; (2)当m远大于n时,n个单位高斯向量可能近似相互正交。
换句话说,在足够高维度的空间中,树的随机分支嵌入(其中每个子节点通过随机单位高斯向量从其父节点偏移)将近似为毕达哥拉斯(Pythagorean)嵌入。
这种结构甚至可以通过迭代过程完成,只需要本地信息。使用完全随机的树嵌入进行初始化,另外为每个顶点选择一个特殊的随机向量;然后在每个步骤中,移动每个子节点,使其更接近其父节点的位置加上子节点的特殊向量。结果将是近似的毕达哥拉斯嵌入。
由于其简单性以及来自局部随机模型的事实,毕达哥拉斯嵌入通常可用于表示树型结构。需要注意的是树的大小是由环境维度控制的,毕达哥拉斯嵌入可能是基于双曲几何的方法的简单替代方案。
有关双曲树表示的更多信息,请参阅这两篇文章。
https://dawn.cs.stanford.edu/2018/03/19/hyperbolics/
https://arxiv.org/abs/1705.08039
树嵌入的实践
在描述了树嵌入的数学定义之后,让我们回到神经网络的世界。
我们的研究对象是BERT模型,这是一个最近在NLP领域十分成功的模型。我们对这个模型感兴趣的一个原因是它对许多不同的任务表现良好,这表明它正在提取通常有用的语言特征。 BERT是Transformer架构的一个案例。
我们不会在这里描述BERT架构,但粗略地说,网络将一系列单词作为输入,并且在一系列层中为每个单词生成一系列嵌入。因为这些嵌入考虑了上下文,所以它们通常被称为上下文嵌入。

人们提出了许多描述句法结构的方法。在依存句法分析中,每个单词都是树的节点。
https://en.wikipedia.org/wiki/Dependency_grammar
很多人研究过这些嵌入,看看它们可能包含哪些信息。为了概括介绍,我们研究树嵌入的动机是Hewitt和Manning的最新成果。他们的论文“一种用于在单词表示中查找语法的结构探针”中表明,上下文嵌入似乎在几何上编码依存句法分析树。
https://nlp.stanford.edu/pubs/hewitt2019structural.pdf
这个地方有点绕:首先你需要将上下文嵌入通过某个矩阵B(一个所谓的结构探针)进行转换。但在此之后,两个单词的上下文嵌入之间的欧式距离的平方近又似于两个单词之间的分析树距离。
这是上一节中的数学成果。在我们的术语中,上下文嵌入近似于毕达哥拉斯嵌入句子的依存句法分析树。这意味着我们有一个树嵌入的好主意:简单地利用平方距离属性和定理1.1
可视化和测量解析树的表示
当然,我们并不能精确地知道形状,因为嵌入只是近似于毕达哥拉斯嵌入。但理想形状和实际形状之间的差异可能非常有趣。经验嵌入与其数学理想化之间的系统差异可以为BERT如何处理语言提供进一步的线索。
注:PCA比t-SNE或UMAP的可视化有更好的可读性。当点聚类或分布在低维流形上时,非线性方法可能做得最好——几乎与n立方体的顶点相反。
为了研究这些差异,我们创建了一个可视化工具。我们的论文有详细介绍,但我们将在此提供一个广泛的描述。作为输入,该工具采用具有相关依存句法分析树的句子。该工具从BERT中提取该句子的上下文嵌入,由Hewitt和Manning的“结构探针”矩阵转换,在1024维空间中产生一组点。
然后,我们通过PCA将这些点投影到两个维度。为了显示基本的树结构,我们连接表示具有依赖关系的单词的点对。下面的图5显示了样本句子的结果,并且为了比较,显示了精确毕达哥拉斯嵌入、随机分支嵌入和节点坐标完全随机的嵌入对于相同数据的PCA预测。


图5. a)BERT解析树嵌入的PCA视图。 b)精确的毕达哥拉斯嵌入。 c)不同的随机分支嵌入。 d)不同的嵌入,其中节点位置是随机独立选择的。
PCA映射很有趣——BERT嵌入和理想化之间有一定的相似性。图5c展示了一系列随机分支嵌入,它们也类似于BERT嵌入。作为基准,图5d显示了一系列嵌入,其中单词随机独立放置。
但我们可以更进一步,并展示嵌入与理想化模型的不同之处。在下面的图6中,每条边的颜色表示欧几里德距离和树距离之间的差异。我们还用虚线连接没有依赖关系但其位置(在PCA之前)比预期更接近的单词对。

生成的图像让我们既可以看到树嵌入的整体形状,也可以看到偏离真正的毕达哥拉斯嵌入的细粒度信息。图5显示了两个示例。这些是典型案例,说明了一些共同的主题。在图中,橙色虚线连接part/of、same/as和sale/of.。这种效果是特征性的,介词嵌入到与它们相关的单词附近。我们还看到两个名词之间的联系显示为蓝色,表明它们比预期的更远——这是另一种常见模式。
图8在本文末尾显示了这些可视化的其他示例,你可以在其中查找更多模式。
基于这些观察,我们决定对不同依赖关系如何影响嵌入距离进行更系统的研究。回答这个问题的一种方法是考虑一大组句子并测试单词对之间的平均距离是否与它们的句法关系有任何关联。我们用一组Penn Treebank句子以及派生的解析树进行了这个实验。

图7.具有给定依赖性的两个单词之间的平均平方边长
图7显示了该实验的结果。事实证明,每个依赖关系的平均嵌入距离变化很大:从大约1.2(prt,advcl)到2.5(mwe,parataxis,auxpass)。推测这些系统差异的原因是有趣的。它们可能是非句法特征的影响,例如句子中的单词距离。或者,使用加权树,BERT的句法表示可能超出了普通的依存语法。
结论
神经网络究竟如何代表语言信息仍然是神秘的。但我们开始看到了吸引人的线索。Hewitt和Manning最近的工作提供了解析树的直接几何表示的证据。他们发现了一种有趣的平方距离效应,我们认为它反映了一种数学上自然的嵌入类型——这使我们对嵌入几何有了惊人的完整概念。同时,BERT中解析树嵌入的实证研究表明,可能还有更多定量方面的关于解析树表示的内容。
非常感谢James Wexler对本笔记的帮助。感谢David Belanger,Tolga Bolukbasi,Dilip Krishnan,D。Sculley,Jasper Snoek和Ian Tenney对本研究的有益反馈和讨论。有关语义和语法的更多详细信息和结果,请阅读我们的全文!敬请期待本系列中的更多笔记。







阅读另一篇BERT可视化文章,请戳《用可视化解构BERT,我们从上亿参数中提取出了6种直观模式》
相关报道:
https://pair-code.github.io/interpretability/bert-tree/
https://arxiv.org/abs/1906.02715