阿里云最近推出了一些图片检测相关API
https://help.aliyun.com/document_detail/28432.html?spm=5176.doc28443.6.121.QFlD2y
经测试,还算靠谱~
下面说明一下具体步骤:
①自己的bucket开通绿网,并且开放外网访问权限
②下载sdk
https://help.aliyun.com/document_detail/28442.html?spm=5176.doc28432.6.137.S0oTaB
这里选用python版,用python自身的pip安装sdk即可
③参考api接口修改相应代码
#coding=utf-8
if __name__=='__main__':
import sys
reload(sys)
sys.setdefaultencoding('gbk')
imgurl=sys.argv[1]
imgurl2=imgurl.encode('utf8')
sys.setdefaultencoding('utf8')
# 同步图片检测服务接口, 会实时返回检测的结果
from aliyunsdkcore import client
from aliyunsdkgreen.request.v20161018 import ImageDetectionRequest
import json
# 请替换成你自己的accessKeyId、accessKeySecret, 您可以类似的配置在配置文件里面,也可以直接明文替换
clt = client.AcsClient("你自己的accessKeyId", "你自己的accessKeySecret",'cn-hangzhou')
request = ImageDetectionRequest.ImageDetectionRequest()
request.set_accept_format('json')
# 设置成同步调用
request.set_Async('false')
# 设置要检测的图片链接
# json字符串格式, 同步只支持单张图片
#request.set_ImageUrl(json.dumps(imgurl).encode('gbk'))
request.set_ImageUrl(json.dumps([imgurl2]))
# 设置要检测的服务场景
# 异步支持多个场景同时识别
# porn: 黄图检测
# ocr: ocr文字识别
# illegal: 暴恐敏感识别
request.set_Scene(json.dumps(["porn","ocr","illegal"]))
response = clt.do_action(request)
#"The request has failed due to a temporary failure of the server"
print response.encode('gbk')
result = json.loads(response)
if "Success" == result["Code"]:
imageResults = result["ImageResults"]["ImageResult"]
for imageDetectResult in imageResults:
#print "完整json串:".encode('gbk')
#print imageDetectResult
# 黄图检测结果
pornResult = imageDetectResult["PornResult"]
#print "色情检测结果:".encode('gbk')
#print pornResult
# 黄图结果中,包含检测分值,和参考建议
# 打印检测分值,0-100
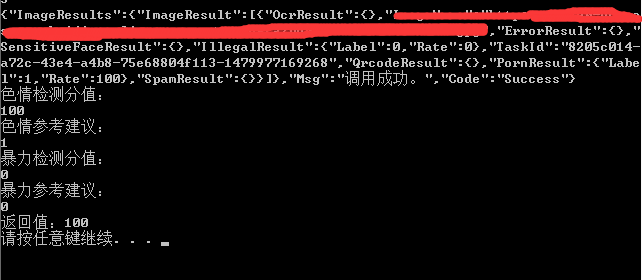
print "色情检测分值:".encode('gbk')
print pornResult["Rate"]
print "色情参考建议:".encode('gbk')
# 打印参考建议, 0表示正常,1表示色情,2表示需要review
print pornResult["Label"]
# ocr结果
# 返回检测出来的文本数组
#print "图文识别检测文本:".encode('gbk')
#ocrResult = imageDetectResult["OcrResult"]
#print ocrResult["Text"]
# 暴恐敏感结果
illegalResult = imageDetectResult["IllegalResult"]
# 分值:0-100
print "暴力检测分值:".encode('gbk')
print illegalResult["Rate"]
# 参考建议: 0表示正常,1表示暴恐敏感,2表示需要review
print "暴力参考建议:".encode('gbk')
print illegalResult["Label"]
#加入了一些返回值
if(pornResult["Label"]!=0):
sys.exit(pornResult["Label"]*100)
elif(illegalResult["Label"]!=0):
sys.exit(pornResult["Label"]*100+200)
else:
sys.exit(0)
注意:
①本文里加入了一些汉字编码转换,具体如何选取要看你自己的服务器编码了
②注意,站点一定要填hangzhou,而不是你自己服务器的站点
③url一定是已开通权限的bucket里的oss地址,外网url不可以。
新增ocr文字识别并打印到第二个参数文本里
# ocr结果
# 返回检测出来的文本数组
print "图文识别检测文本:".encode('gbk')
ocrResult = imageDetectResult["OcrResult"]
dictText=ocrResult["Text"]["String"]
strText=('').join(dictText)
print strText.encode('gbk')
#print type(dictText)
#print len(sys.argv)
if len(sys.argv)==3:
f=open(sys.argv[2],'w+')
f.write(strText.encode('gbk'))
f.close()
注:我们知道python里json.loads后会将编码转化为unicode,如果此后用str()将dict转换为str,将输出编码为unicode,即使用encode也没有办法转回其他编码
所以要用join函数将其转化为str,之后再用encode改变编码阿里云最近推出了一些图片检测相关API
https://help.aliyun.com/document_detail/28432.html?spm=5176.doc28443.6.121.QFlD2y
经测试,还算靠谱~
下面说明一下具体步骤:
①自己的bucket开通绿网,并且开放外网访问权限
②下载sdk
https://help.aliyun.com/document_detail/28442.html?spm=5176.doc28432.6.137.S0oTaB
这里选用python版,用python自身的pip安装sdk即可
③参考api接口修改相应代码
#coding=utf-8
if __name__=='__main__':
import sys
reload(sys)
sys.setdefaultencoding('gbk')
imgurl=sys.argv[1]
imgurl2=imgurl.encode('utf8')
sys.setdefaultencoding('utf8')
# 同步图片检测服务接口, 会实时返回检测的结果
from aliyunsdkcore import client
from aliyunsdkgreen.request.v20161018 import ImageDetectionRequest
import json
# 请替换成你自己的accessKeyId、accessKeySecret, 您可以类似的配置在配置文件里面,也可以直接明文替换
clt = client.AcsClient("你自己的accessKeyId", "你自己的accessKeySecret",'cn-hangzhou')
request = ImageDetectionRequest.ImageDetectionRequest()
request.set_accept_format('json')
# 设置成同步调用
request.set_Async('false')
# 设置要检测的图片链接
# json字符串格式, 同步只支持单张图片
#request.set_ImageUrl(json.dumps(imgurl).encode('gbk'))
request.set_ImageUrl(json.dumps([imgurl2]))
# 设置要检测的服务场景
# 异步支持多个场景同时识别
# porn: 黄图检测
# ocr: ocr文字识别
# illegal: 暴恐敏感识别
request.set_Scene(json.dumps(["porn","ocr","illegal"]))
response = clt.do_action(request)
#"The request has failed due to a temporary failure of the server"
print response.encode('gbk')
result = json.loads(response)
if "Success" == result["Code"]:
imageResults = result["ImageResults"]["ImageResult"]
for imageDetectResult in imageResults:
#print "完整json串:".encode('gbk')
#print imageDetectResult
# 黄图检测结果
pornResult = imageDetectResult["PornResult"]
#print "色情检测结果:".encode('gbk')
#print pornResult
# 黄图结果中,包含检测分值,和参考建议
# 打印检测分值,0-100
print "色情检测分值:".encode('gbk')
print pornResult["Rate"]
print "色情参考建议:".encode('gbk')
# 打印参考建议, 0表示正常,1表示色情,2表示需要review
print pornResult["Label"]
# ocr结果
# 返回检测出来的文本数组
#print "图文识别检测文本:".encode('gbk')
#ocrResult = imageDetectResult["OcrResult"]
#print ocrResult["Text"]
# 暴恐敏感结果
illegalResult = imageDetectResult["IllegalResult"]
# 分值:0-100
print "暴力检测分值:".encode('gbk')
print illegalResult["Rate"]
# 参考建议: 0表示正常,1表示暴恐敏感,2表示需要review
print "暴力参考建议:".encode('gbk')
print illegalResult["Label"]
#加入了一些返回值
if(pornResult["Label"]!=0):
sys.exit(pornResult["Label"]*100)
elif(illegalResult["Label"]!=0):
sys.exit(pornResult["Label"]*100+200)
else:
sys.exit(0)
注意:
①本文里加入了一些汉字编码转换,具体如何选取要看你自己的服务器编码了
②注意,站点一定要填hangzhou,而不是你自己服务器的站点
③url一定是已开通权限的bucket里的oss地址,外网url不可以。
新增ocr文字识别并打印到第二个参数文本里
# ocr结果
# 返回检测出来的文本数组
print "图文识别检测文本:".encode('gbk')
ocrResult = imageDetectResult["OcrResult"]
dictText=ocrResult["Text"]["String"]
strText=('').join(dictText)
print strText.encode('gbk')
#print type(dictText)
#print len(sys.argv)
if len(sys.argv)==3:
f=open(sys.argv[2],'w+')
f.write(strText.encode('gbk'))
f.close() 注:我们知道python里json.loads后会将编码转化为unicode,如果此后用str()将dict转换为str,将输出编码为unicode,即使用encode也没有办法转回其他编码
所以要用join函数将其转化为str,之后再用encode改变编码
原文地址:http://m.blog.csdn.net/sm9sun/article/details/53321888