拉勾的一些反爬机制,例如:
1、职位信息通过ajax加载,直接获取html会报'页面加载中',需要查看ajax请求
2、反爬header,不加header信息会报"您操作太频繁,请稍后再访问"
3、频繁访问封IP,使用time.sleep()解决
整体代码:
import json
import requests
from bs4 import BeautifulSoup
import time
import pandas
def position_detail(position_id):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/4070834.html',
'Upgrade-Insecure-Requests':'1',
'Cookie':'_ga=GA1.2.925224148.1520249382; _gid=GA1.2.1215509072.1520249382; user_trace_token=20180305192941-7f1b8d57-2068-11e8-b126-5254005c3644; LGUID=20180305192941-7f1b9199-2068-11e8-b126-5254005c3644; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAIAACBIDC6D0022285C6CAF595664653AED3310; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1520249382,1520258022,1520300598; LGSID=20180306094319-bf8c1061-20df-11e8-9d87-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%3Fpx%3Ddefault%26city%3D%25E5%25B9%25BF%25E5%25B7%259E; _putrc=81382530AB4F106A; SEARCH_ID=e2307ebf7bf348bd80fc22d967cc5f9c; _gat=1; login=true; unick=%E4%BA%8E%E6%9D%B0; gate_login_token=b4130f20f835c543e0404ca5e937a6c7ad8b2df841a6502c; LGRID=20180306101243-daaf0d82-20e3-11e8-b126-5254005c3644; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1520302363'
}
url = 'https://www.lagou.com/jobs/%s.html' % position_id
result = requests.get(url, headers=headers)
time.sleep(5)
soup = BeautifulSoup(result.content, 'html.parser')
position_conent = soup.find('dd',class_="job_bt")
if position_conent is None:
return
return position_conent.text
def main():
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'Cookie':'user_trace_token=20180426120038-d73f4812-f98c-45f1-80ad-2fa15885541b; _ga=GA1.2.316967756.1524715241; LGUID=20180426120043-640d2714-4906-11e8-a51d-525400f775ce; JSESSIONID=ABAAABAAAGGABCB949979A4BA453871F38CFD8CD7DD59E2; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1524715240,1526206393; _gat=1; LGSID=20180513181313-3f272a9d-5696-11e8-823a-5254005c3644; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Db_WifzKOMEAsBbEykMZM4WuB5QXKYS9D3oDGOxeVcdS%26wd%3D%26eqid%3Df5739de300024fc6000000065af80fb3; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _gid=GA1.2.1991740482.1526206393; index_location_city=%E6%B7%B1%E5%9C%B3; TG-TRACK-CODE=index_search; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1526206657; LGRID=20180513181738-dc96e102-5696-11e8-987d-525400f775ce; SEARCH_ID=73b9a480e63f4300b8c20eec45eb915f',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
info_list = []
for x in range(1,26):
datas = {
'first': True,
'pn': x,
'kd': '数据分析'
}
time.sleep(3)
content=requests.post(url=url,headers=headers,data=datas)
results = content.json()
jobs = results['content']['positionResult']['result']
for job in jobs:
job_dict={
'positionname':job['positionName'],
'workyear':job['workYear'],
'salary':job['salary'],
'education':job['education'],
'industryField':job['industryField'],
'companyshortname':job['companyShortName'],
'companyLabelList':job['companyLabelList'],
'district':job['district'],
'companyFullName':job['companyFullName'],
}
position_id=job['positionId']
job_dict['position_detail'] = position_detail(position_id)
print(position_detail)
info_list.append(job_dict)
df=pandas.DataFrame(info_list)
df.to_excel('E:\\数据分析-深圳.xls')
return df
#print(json.dumps(info_list,ensure_ascii=False,indent=2))
main()
一、通过右键检查找到ajax获取职位数据的那个请求
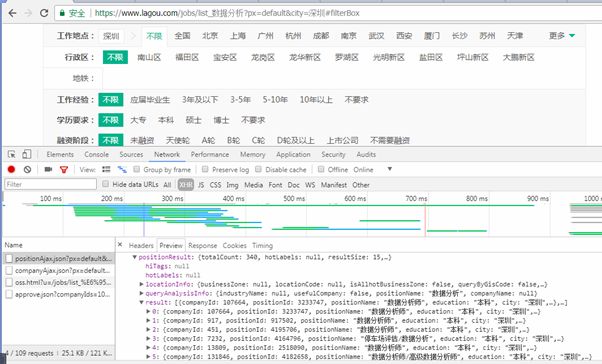
根据这个ajax找到请求的方式、url、头部、参数等信息
url 和requests获取方式

头部:
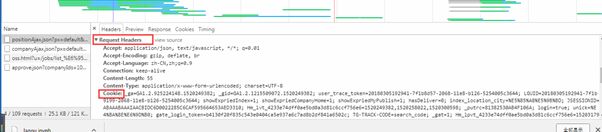

参数:

url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'Cookie':'user_trace_token=20180426120038-d73f4812-f98c-45f1-80ad-2fa15885541b; _ga=GA1.2.316967756.1524715241; LGUID=20180426120043-640d2714-4906-11e8-a51d-525400f775ce; JSESSIONID=ABAAABAAAGGABCB949979A4BA453871F38CFD8CD7DD59E2; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1524715240,1526206393; _gat=1; LGSID=20180513181313-3f272a9d-5696-11e8-823a-5254005c3644; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Db_WifzKOMEAsBbEykMZM4WuB5QXKYS9D3oDGOxeVcdS%26wd%3D%26eqid%3Df5739de300024fc6000000065af80fb3; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _gid=GA1.2.1991740482.1526206393; index_location_city=%E6%B7%B1%E5%9C%B3; TG-TRACK-CODE=index_search; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1526206657; LGRID=20180513181738-dc96e102-5696-11e8-987d-525400f775ce; SEARCH_ID=73b9a480e63f4300b8c20eec45eb915f',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
content=requests.post(url=url,headers=headers,data=datas)
二.
通过 print(content.text) 获取json格式文件
将得到的输出结果通过https://www.bejson.com/ 校验格式是否正确
若正确,https://www.json.cn 输入到此网站解析为xml文件

在content.json().['content']['positionResult']['result']中我们找到了要爬取的职位信息
content=requests.post(url=url,headers=headers,data=datas)
results = content.json()
jobs = results['content']['positionResult']['result']
三.获取所有页的职位信息
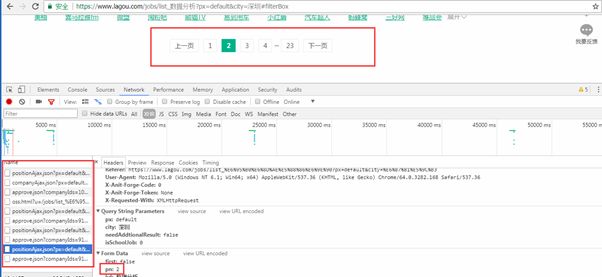
接着我们看下此请求的参数:
'first':'true'#是否是第一页
'pn':1 #请求第几页
'kd':'python'#搜索条件
所以只要改变请求页数就可以获得分页的数据
此处有25页 就可以用一个range(1,26)搞定,同时针对反扒机制,把线程休眠时间调长
info_list = []
for x in range(1,26):
datas = {
'first': True,
'pn': x,
'kd': '数据分析'
}
time.sleep(3)
content=requests.post(url=url,headers=headers,data=datas)
results = content.json()
jobs = results['content']['positionResult']['result']
四.提取所需字段,组成一个新字典
在jobs这个字典中 我们选取需要爬取的条目 组成一个新的字典job_dict
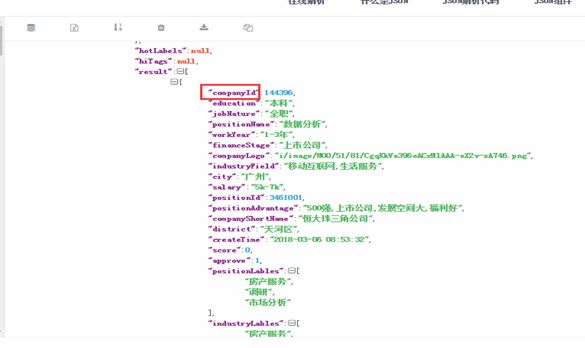
for job in jobs:
job_dict={
'positionname':job['positionName'],
'workyear':job['workYear'],
'salary':job['salary'],
'education':job['education'],
'industryField':job['industryField'],
'companyshortname':job['companyShortName'],
'companyLabelList':job['companyLabelList'],
'district':job['district'],
'companyFullName':job['companyFullName'],
}
五.
接着我们要爬取每一个职位里的职位描述详细信息 利用positionId进行网页联结

在dd class = “job_bt”中找到职位描述信息
相同原理进行爬取 修改URL positionId为s% 定义一个爬取职位描述的函数,使用BeautifulSoup将文本提取,返回职位要求内容,对于没有job_bt的跳过
def position_detail(position_id):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/4070834.html',
'Upgrade-Insecure-Requests':'1',
'Cookie':'_ga=GA1.2.925224148.1520249382; _gid=GA1.2.1215509072.1520249382; user_trace_token=20180305192941-7f1b8d57-2068-11e8-b126-5254005c3644; LGUID=20180305192941-7f1b9199-2068-11e8-b126-5254005c3644; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAIAACBIDC6D0022285C6CAF595664653AED3310; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1520249382,1520258022,1520300598; LGSID=20180306094319-bf8c1061-20df-11e8-9d87-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%3Fpx%3Ddefault%26city%3D%25E5%25B9%25BF%25E5%25B7%259E; _putrc=81382530AB4F106A; SEARCH_ID=e2307ebf7bf348bd80fc22d967cc5f9c; _gat=1; login=true; unick=%E4%BA%8E%E6%9D%B0; gate_login_token=b4130f20f835c543e0404ca5e937a6c7ad8b2df841a6502c; LGRID=20180306101243-daaf0d82-20e3-11e8-b126-5254005c3644; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1520302363'
}
url = 'https://www.lagou.com/jobs/%s.html' % position_id
result = requests.get(url, headers=headers)
time.sleep(5)
soup = BeautifulSoup(result.content, 'html.parser')
position_conent = soup.find('dd',class_="job_bt")
if position_conent is None:
return
return position_conent.text
六.
position_id=job['positionId']
job_dict['position_detail'] = position_detail(position_id)
print(position_detail)
info_list.append(job_dict)
df=pandas.DataFrame(info_list)
df.to_excel('E:\\数据分析-深圳.xls')
通过id在函数中运行获取的职位信息添加到job_dict字典中 将job_dict添加到空列表中info_list
通过pandas转化为DataFrame数据
保存为excel文件