By云端上的男人—DT大数据梦工厂
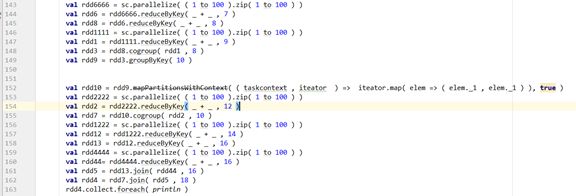
笔者之前读过关于DAGScheduler中关于Stage划分的源码的实现,特此笔者把自己在這里一些的感悟与心得与大家分享一下。如图1所示,这是个RDD之间的依赖图,褐红色的箭头代表着宽依赖。黑色的箭头代表着窄依赖,其中渐变色代表着宽依赖(ShuffleDependency)实体的序号。笔者之前的博文中说过RDD之间是有依赖的,每个子RDD会依赖其父RDD的分区的特性,不过笔者今天不会讲解那方面的知识,笔者今天想把关于DAGScheduler中Stage的划分给分享一下,如有不对,欢迎大家批评指正。
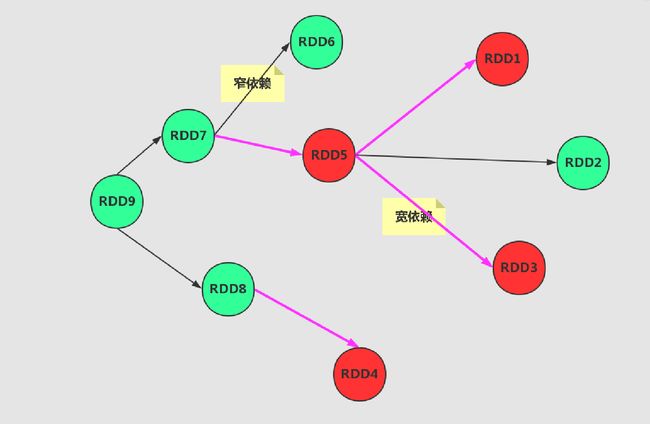
图1中是一个Job,而且RDD4是最后的一个生成的RDD,在完整的看DAGScheduler是如何划分Stage的时候,笔者想先给出DAGScheduler实体中的一些重要的方法,以便于我们对整体的DAGScheduler实体划分Stage的理解。下图是直接从rdd的角度来看如何去获得所需的这个rdd的所有的父Stage的实体
笔者所写的博客面对的人员是有scala基础以及对进程和线程有相关概念的人员和spark会基本使用的人员,如果大家有的对scala不是很熟悉的话,请大家观看家林老师的相关的scala教程链接:链接:http://pan.baidu.com/s/1c2w45ig 密码:juo3
Spark基础相关的链接链接:链接:http://pan.baidu.com/s/1pLTYbEj 密码:2ttp
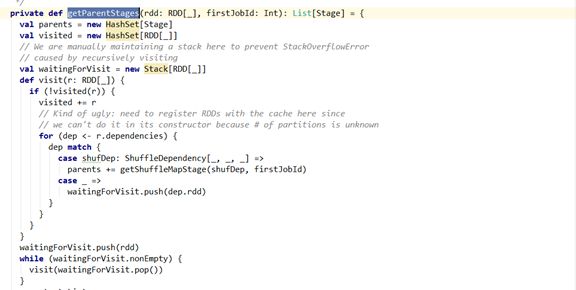
图2中所使用的内部的方法的思维广度遍历。用以找出所有的关于这个rdd与父RDD之间具有宽依赖的特性的信息。

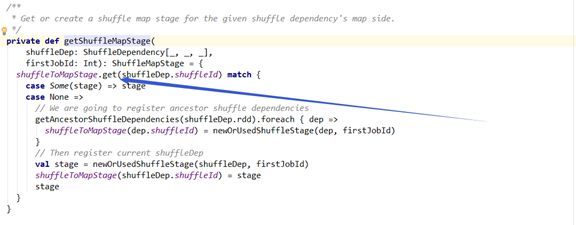
从getShuffleMapStage这个方法的输入值和返回值,我们可以看出需要一个宽依赖的实体,然后给我们生成一个ShuffleMapStage实体,假设我们输入的宽依赖的实体是图1中的2的话,我们跟着代码的走向,默认情况下就会走到getAncestorShuffleDependencies(shuffleDep.rdd),即getAncestorShuffleDependencies( RDD7 )。这个getAncestorShuffleDependencies方法确实是起到了很关键的作用。getShuffleMapStage方法的思路也是很清晰,只需要返回的是跟这个依赖相关的ShuffleMapStage即可,其他的ShuffleMapStage就通过getAncestorShuffleDependencies方法拿到该宽依赖所对应的rdd即可,(这里的rdd是RDD7)。而getAncestorShuffleDependencies方法从名字上看,直观的来说就是获得从这个rdd开始,一直遍历完这颗rdd之前父RDD的所有的节点即可,而getAncestorShuffleDependencies方法的目的也是很简单,拿到这个rdd所有的(祖)父RDD中有关宽依赖的所有的信息即可。然后拿到这些宽依赖之后,就开始把这些宽依赖生成相应的ShuffleMapStage,并且保存在shuffleToMapStage数据结构实体中。getAncestorShuffleDependencies代码如下图所示。

我们继续按照之前的逻辑走的话,图4这个函数输入的rdd则是图1中的RDD7,输入之后,getAncestorShuffleDependencies内部使用了广度优先的遍历方法,把所有的在关于RDD7的所有的与(祖)父RDD之间的宽依赖的信息给找到。找出的结果如图所示。

如图红色标记的宽依赖实体,有4,3,6,5
Note:getAncestorShuffleDependencies方法返回的ShuffleDependency列表的顺序是非常重要,从RDD7这个子树根到叶子结点,越是靠近(祖)父的宽依赖,返回的宽依赖的栈列表中位置就会越高,即会先得到执行。所以在返回的栈列表的结果的顺序则是4,3,6,5几个数字的逆序。
分析完图4,图5之后,我们继续我们的分析,接下来将会出现一个有些绕的方法,即newOrUsedShuffleStage(dep,firstJobId),这个方法内部会调用newShuffleMapStage( rdd。。。)等参数。

而图6又会去调用newShuffleMapStage方法。如下图所示

而图7中的关键的代码,是getParentStagesAndId(rdd,firstJobId),如图所示

而在下图中,我们又看到了一些个熟悉的代码。即getShuffleMapStage方法,如果读者还记得的话,这个方法在笔者刚开始说的就是这个方法,如图3所示。这显然就是一个间接递归的调用。


我们再次去分析一下图3中的代码。我们从图中可以看出,一个宽依赖可只能对应一个RDD这样的实体,但是一个RDD确实可以对应多个宽依赖这样的实体。getShuffleMapStage方法,也是给了我们一些启示,
就像是图10一样,一个宽依赖的实体可以对应一个RDD,但是关于这个RDD的(祖)父的信息是一无所知的,所以就通过getAncestorShuffleDependencies去找一下是否有宽依赖的实体。当然,没有宽依赖的实体是最好的,但是这个只是一种情况,当我们得知还是有宽依赖的时候,我们的想法还是去继续去找这个依赖是还有其他的宽依赖的,说到这里,相信读者也都出来有递归的感觉了。
笔者也曾困惑一段时间,不过随着对这个源码继续的深入发现,还是有解决的思路。即shuffleToMapStage数据结构实体,以及这段代码的体现。

笔者刚才说过一个特性就是getAncestorShuffleDependencies方法返回的栈列表列表的顺序是有特性的,即从RDD7这个子树根到叶子结点,越是靠近(祖)父的宽依赖,返回的宽依赖的列表中位置就会越高,即会优先得到执行。所以在返回的栈列表的结果的顺序则是4,3,6,5这几个数字的逆序。也就是说,newOrUsedShuffleStage( 6 )是最先被调用执行。而且其中的getParentStagesAndId(RDD1),是会被调用执行的。这个RDD1已经是没有任何依赖的,即没有父Stage。而这个RDD1所对应的ShuffleMapStage也会生成,不仅如此,shuffleToMapStage数据结构实体也会记录这个ShuffleMapStage的存在。
接下来的5,和4这两个宽依赖和6处理思路一样,都没有父Stage。那么现在到3这个宽依赖了,newOrUsedShuffleStage方法追中调用了3这个宽依赖的的所对应的RDD3,如图11所示。紧接着调用了getShuffleMapStage方法,回到了我们熟悉的方法中。但是调用的方法变了,如图12所示

也就是说,宽依赖3被newOrUsedShuffleStage方法调用之后,宽依赖3的(祖)父宽依赖早已经被记录了,所以不会再让getShuffleMapStage走递归调用。
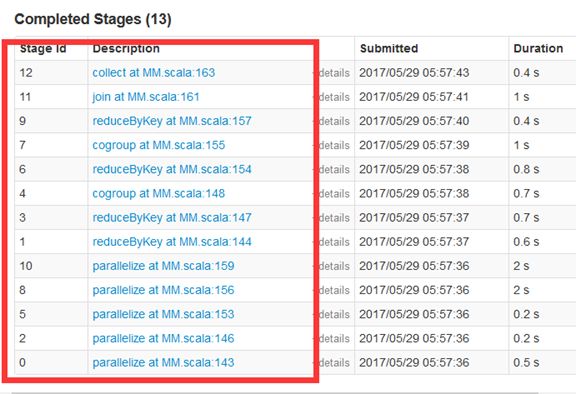
最后标出生成的Stage Id的序列号。注:图13是笔者另画的一个rdd之间依赖的关系图,这次是为在集群中做运行,为的是动手实践要获得的所需要论证的结果。详细的Stage图为下图所示

这个是在Spark UI中 显示的结果,而且,通过之前的方法得到的结果是一样的。图中小圆圈的符号代表着宽依赖的序号,且序号随意标出的,只是为了方便记忆。
相关的代码如下所示。读者可以通过观看代码中各个rdd中的名字来观看图13中各个stage中各个rdd存在的位置的准确性(根据getAncestorShuffleDependencies方法获得的栈列表的特性,以及广度优先遍历的规则,还要记得的是,在getAncestorShuffleDependencies方法中,一定要理顺宽依赖节点入栈与出栈的顺序,这对后面要输出的stageID非常重要,切记 )。也可以通过之前提到的递归的方法来测验一下结果是否正确。图15则是所需测试的rdd集合。