泰坦尼克事件被一再提起,因为这次沉船事件的戏剧化的悲剧色彩,一瞬间华丽到幻灭的无常都使人嗟叹不已。只是没想到在R语言的学习中,竟然也要再次触碰这场事件。第一次接触kaggle,一个为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台,入门第一步就是从泰坦尼克事件中的数据分析开始。
拜读了PPV课大数据的文章之后,也试图结合自己的思考模仿做一下数据分析。
首先下载和加载数据包:
在Kaggle上,有三个csv可供下载:train.csv,test.csv,gender_submission.csv.
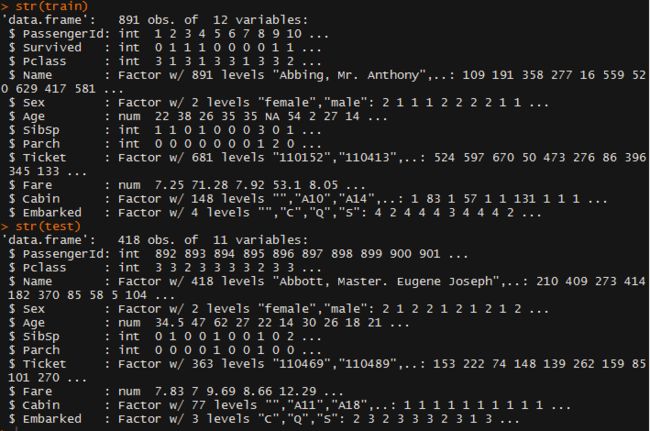
在train.csv中有891个观测值(行),每个观测值有12个变量。test.csv较小,只有418名乘客的命运需要预测,且只有11个变量,这是因为“Survived”列缺失了。这就是我们想要预测的列。
一、首先预测看下观测数据中的存活率:
table(train$Survived)01549342
0代表死亡,1代表存活,从此看出,多数人未能存活。但就此来预测未免太粗略了。
二、泰坦尼克号事件中比较著名的“妇女和孩子先走”,先来看看是否如此。先看船上男女数量:
> table(train$Sex)
female male 314 577
显然女性乘客数量远少于男性,所以用存活的男女数量比较是得不出想要的结果的。想知道男女分别存活的比率才是我们想要的。
prop.table(table(train$Sex, train$Survived),1)
0 1
female 0.2579618 0.7420382 male 0.8110919 0.1889081
女性74.2%存活,而男性只有19%存活。
接着来看一下年龄因素的影响。
> prop.table(table(train$Child,train$Survived),1)
summary(train$Age)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 0.42 20.12 28.00 29.70 38.00 80.00 177
缺失的记录达177份,我们可以用年龄的均值来填补这些缺失值。我们把成人定义为18岁以上的人,孩子定义为18岁及以下的人,来对所有人作个归类。
> train$Child<-"adult"> train$Child[train$Age<18]<-"child"
年龄的均值为29.7岁,大于18岁,属性child已被设为“adult”。
> prop.table(table(train$Child,train$Survived),1)
0 1
adult 0.6388175 0.3611825 child 0.4601770 0.5398230
成人的存活比例是36%,而孩子的存活比例是54%。这个维度如果和性别交叉起来看,又该如何呢?先看一下各类人群人数。
> aggregate(Survived~Child+Sex,data=train,FUN=length)
Child Sex Survived1
adult female 2592
child female 553
adult male 5194
child male 58
现在要找出存活比例,此时需创建一个函数来解决:
> aggregate(Survived~Child+Sex,data=train,FUN=function(x){sum(x)/length(x)}) Child Sex Survived1 adult female 0.75289582 child female 0.69090913 adult male 0.16570334 child male 0.3965517
这里能看出,无论女性是否是孩子,比例很相近,而男孩子的存活比例要略高于成年男性,均远低于女性比例。看到这个比例,似乎不太符合孩子优先存活的说法,生活中其实十八岁的孩子其实身形已和成年人没有什么区别,在沉船发生后的混乱局面中,很难去分辨是否低于18岁,因此,被优先的可能是更小的孩子。因此,我们把孩子的年龄定义改为10岁,再来看看。
> train$Child<-"adult"> train$Child[train$Age<10]<-"child"> aggregate(Survived~Child+Sex,data=train,FUN=function(x){sum(x)/length(x)})
Child Sex Survived1
adult female 0.75352112
child female 0.63333333
adult male 0.16513764
child male 0.5937500
10岁以下的男孩子存活比例明显高于10岁以上的男性。
那么除了这些因素以外,其他因素是如何影响存活率的?想看看舱位等级是否对存活率有影响,船上有三种舱位,用Pclass表示。
> aggregate(Survived~Pclass+Sex,data=train,FUN=function(x){sum(x)/length(x)})
Pclass Sex Survived1
1 female 0.96808512
2 female 0.92105263
3 female 0.50000004
1 male 0.36885255
2 male 0.15740746
3 male 0.1354467
可以看出,对女性来说,一等舱和二等舱的存活率几乎是三等舱的二倍,男性来说,一等舱是二等舱和三等舱存活率的二倍。
先按照以上推论做一版提交,打个底
> test$Survived<-0> test$Survived[test$Sex=="female"]<-1> test$Survived[test$Age<10]<-1> test$Survived[test$Pclass=="1"]<-1>
submit<-data.frame(PassengerId=test$PassengerId,Survived=test$Survived)> write.csv(submit, file ="theyallperish.csv", row.names =FALSE)
这次的成绩:6485,0.7081
显然,目前利用到的信息只有性别、年龄、舱位,在下一步利用“决策树”(rpart—Recursive Partitioning andRegression Trees,递归分割和回归树)从更多的维度去分析。
library(rpart)
fit <- rpart(Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked,data=train,method="class")
我们看看fit:
> plot(fit)
> text(fit)
有些不清,用武器强化一下:
> install.packages('rattle')
> install.packages('rpart.plot')
> install.packages('RColorBrewer')
> library(rattle)
> library(rpart.plot)
> library(RColorBrewer)
> fancyRpartPlot(fit)
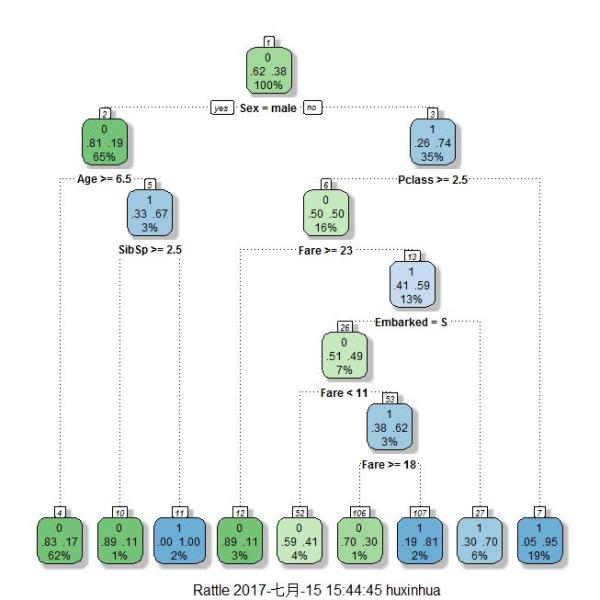
决策树按照算法,将数据分析后一层层地,找到最可能分界点,最上一层是总比例,多数为“0”即死亡,按性别分,男性占比65%,但是多数为“0”即死亡,女性占比35%,多数为“1”即存活。年龄这层,分界点选在了6.5岁,因为在这个分界线上,生存概率区分最明显,在6.5岁以下,兄弟姐妹数量大于2.5的存活机率又比其他的更多。以此类推。
> Prediction <- predict(fit, test, type ="class")
> submit <- data.frame(PassengerId = test$PassengerId, Survived = Prediction)
> write.csv(submit, file ="myfirstdtree.csv", row.names =FALSE)
这次上传后排名直接上升到3039名。
这次的作业是一个实例练习,没有明确的指引该怎么往下做。在两眼一抹黑的情况下,幸有前人引路,一点点揭开R语言神秘的面纱。现在只是简单地一窥尊容,发现R里面的乾坤世界,在Kaggle上更是见识了机器学习的浩然大海。