提到股票数据的获取,平时我们用的行情软件同花顺上就可以直接导出股票交易数据,包括开盘价、最高价、最低价、收盘价、涨幅、振幅等数据,具体的方法网上有很多,这里不赘述。不过我们所期望的量化交易系统,应该是能够自动从网上下载股票数据的系统。说到从网上下载股票数据,我们会联想到网络爬虫,其实本节介绍的股票数据自动下载的方式和网络爬虫爬取网上资源的方式十分相似。目前像雅虎财经、新浪财经等门户网站提供了免费的金融数据接口,同时像Pandas库、Tushare库等工具提供了从财经网站获取股票数据的API,这么一来我们就可以调用API轻松获取到股票数据了。
一、pandas获取股票数据
我们知道Pandas库在金融量化分析中优势明显,应用也非常广泛。Pandas库提供了从雅虎财经、新浪财经这些财经网站获取股票数据的接口,通过调用这些接口,我们可以轻松获取到股票数据。
Pandas专门处理金融数据的模块叫做pandas-datareader。补充说明下,早期Pandas处理金融数据的模块为 。由于目前已经迁移到了pandas-datareader包,因而在import 库的时候要导入的是pandas-datareader。
import pandas_datareader.data as web
具体获取股票数据的方法是 data.DataReader() ,这里将pandas-datareader模块的 data 类 取名为 web ,该方法的第一个参数为股票代码,可以是国外的,也可以是国内的,比如苹果公司的代码为“AAPL”,这里主要针对A股市场的数据获取,我们采用的输入方式为“股票代码”+“对应股市”。上证股票在股票代码后面加上.SS,深圳股票在股票代码后面加上 .SZ(创业板、中小板为深圳交易所下子板块),"000001.SS"为指定获取上证指数的交易数据。第二个参数指定获取股票数据的网站,DataReader可从从多个金融网站获取到股票数据,此处"yahoo"指定是从雅虎网站获取股票数据。第三、四个参数为指定股票数据的起始时间,此处指定获取从2017年1月1日至今的交易数据。
#获取上证指数2017年1月1日至今的交易数据
df_stockload = web.DataReader("000001.SS", "yahoo", datetime.datetime(2017,1,1), datetime.date.today())
#打印结果如下:
print (df_stockload.columns)#查看列名
Index([u'Open', u'High', u'Low', u'Close', u'Adj Close', u'Volume'], dtype='object'
#打印结果如下:
print (df_stockload.index)#查看索引
DatetimeIndex(['2017-01-03', '2017-01-04', '2017-01-05', '2017-01-06',
'2017-01-09', '2017-01-10', '2017-01-11', '2017-01-12',
'2017-01-13', '2017-01-16',
...
'2018-11-12', '2018-11-13', '2018-11-14', '2018-11-15',
'2018-11-16', '2018-11-19', '2018-11-20', '2018-11-21',
'2018-11-22', '2018-11-23'],
dtype='datetime64[ns]', name=u'Date', length=462, freq=None)
#打印结果如下:
print (df_stockload.describe())#查看各列数据描述性统计
Open High Low Close Adj Close \
count 462.000000 462.000000 462.000000 462.000000 462.000000
mean 3121.875050 3139.787476 3104.777923 3124.951808 3124.951808
std 245.048873 241.854855 248.790364 245.807224 245.807224
min 2460.081055 2544.910889 2449.197021 2486.418945 2486.418945
25% 3058.461609 3084.214783 3042.248779 3062.479248 3062.479248
50% 3179.507080 3192.935425 3163.997070 3182.991455 3182.991455
75% 3287.011536 3303.148743 3270.466553 3289.904480 3289.904480
max 3563.639893 3587.031982 3534.195068 3559.465088 3559.465088
Volume
count 462.000000
mean 167505.844156
std 42426.788651
min 88200.000000
25% 134225.000000
50% 159900.000000
75% 192075.000000
max 282500.000000
DataReader 方法返回的是DataFrame格式数据,我们可以参照《股票数据规整化处理》一节中的方法查看数据的整体情况并进行相应处理,此处我们打印返回的DataFrame对象的列名和索引及基本统计信息对数据进行查看。我们发现和《股票数据规整化处理》小节CSV导入的股票数据格式相近,也包括行索引-时间、列索引-开盘、最高价、最低价、成交量等,以及对应的数据值,仿佛这已经是存储股票数据的一种通用格式。
由于Pandas封装了Matplotlib,我们在Pandas中可以以更直接、简单的方式绘制数据曲线,如下图所示:
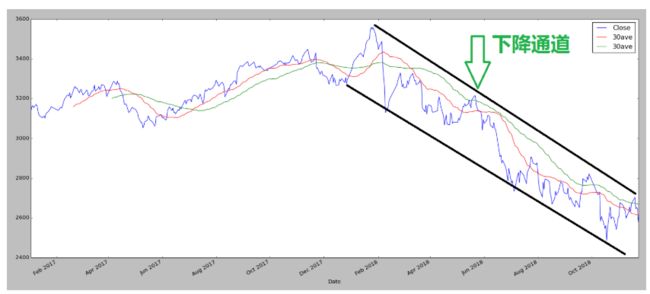
我们绘制了上证指数的收盘价、30日均线和60日均线,关于均线的具体绘制方法后续章节中会详细介绍,这里我们主要以可视化的方式了解下Pandas库下载得到的上证指数数据形式,我们看到2018年的行情整体属于熊市行情,从2月份开始指数一直处于下降通道的趋势中。注:最新的绘制移动平均线接口为 df.rolling().mean()
#绘制移动平均线
df_stockload.Close.plot(c='b')
df_stockload.Close.rolling(window=30).mean().plot(c='r') #pd.rolling_mean(df_stockload.Close,window=30).plot(c='r')
df_stockload.Close.rolling(window=60).mean().plot(c='g') #pd.rolling_mean(df_stockload.Close,window=60).plot(c='g')
plt.legend(['Close','30ave','60ave'],loc='best')
plt.show()
tushare-获取股票数据
Tushare是一个免费、开源的Python财经数据接口包,它返回的绝大部分数据格式都是Pandas DataFrame类型,因此非常便于结合Pandas、NumPy、Matplotlib进行数据分析和可视化。从2014年作为开源项目发布至今,Tushare 提供的金融数据种类日趋丰富,而且技术资料也非常详细。目前团队推出了Tushare Pro版本,这个版本相比于旧版本来说数据更加稳定、质量也更好了,使用的话需要先注册获取TOKEN凭证,不过旧版本仍然可以使用,只是团队不再维护数据获取的接口。这里我们介绍下旧版本股票数据获取的方法(http://tushare.org) , 感兴趣的同学可以在Tushare金融大数据社区获取到Tushare Pro版本的具体使用介绍。
Pandas中仅需要使用简单的API就可以获取到股票的交易数据,在Tushare中也是一样,这里我们使用 get_hist_data() 方法来获取上证指数2017年1月1日至今的交易数据。说明一下其中的参数:
第一个参数为6位数字股票代码,或者指数代码(sh表示上证指数、sz表示深圳成指、hs300表示沪深300指数、sz50表示上证50、zxb表示中小板 、cyb表示创业板);
start和end分别为开始日期和结束日期,格式为YYYY-MM-DD形式的字符串;
ktype参数指定数据类型,D表示日K线、W表示周、M表示月、5表示5分钟、15表示15分钟、 30表示30分钟、 60表示60分钟,默认为D,即日K线;
retry_count为当网络异常后重试次数,默认为3;
pause为重试时停顿秒数,默认为0。
在返回值方面,get_hist_data() 方法返回的列索引内容相比于DataReader 方法更为丰富,比如多了价格变动 price_change 、涨跌幅p_change、5日到20日的均价、5日到20日均量等,这些内容在Pandas中单独使用相应的接口也是可以获取到的。
由于get_hist_data() 方法返回的数据为DataFrame类型,因而我们可以直接使用Pandas的一系列方法对数据进行查看和处理。
#导入Tushare库
import tushare as ts
df_stockload = ts.get_hist_data('sh',start='2017-01-01',end=datetime.datetime.now().strftime('%Y-%m-%d'))
#打印结果如下:
print df_stockload.columns#查看列名
Index([u'open', u'high', u'close', u'low', u'volume', u'price_change',
u'p_change', u'ma5', u'ma10', u'ma20', u'v_ma5', u'v_ma10', u'v_ma20'],
dtype='object')
#打印结果如下:
print df_stockload.index#查看索引
Index([u'2018-11-23', u'2018-11-22', u'2018-11-21', u'2018-11-20',
u'2018-11-19', u'2018-11-16', u'2018-11-15', u'2018-11-14',
u'2018-11-13', u'2018-11-12',
...
u'2017-01-16', u'2017-01-13', u'2017-01-12', u'2017-01-11',
u'2017-01-10', u'2017-01-09', u'2017-01-06', u'2017-01-05',
u'2017-01-04', u'2017-01-03'],
dtype='object', name=u'date', length=462)
#打印结果如下:
print df_stockload.describe()#查看各列数据描述性统计
open high close low ... ma20 v_ma5 v_ma10 v_ma20
count 462.000000 462.000000 462.000000 462.000000 ... 462.000000 4.620000e+02 4.620000e+02 4.620000e+02
mean 3121.875065 3139.787576 3124.951407 3104.777944 ... 3134.794929 1.673643e+06 1.670299e+06 1.667885e+06
std 245.048978 241.854688 245.805599 248.790221 ... 230.163844 3.707376e+05 3.454490e+05 3.108617e+05
min 2460.080000 2544.910000 2486.420000 2449.200000 ... 2596.037000 9.709432e+05 1.009584e+06 1.042750e+06
25% 3058.462500 3084.217500 3062.482500 3042.252500 ... 3096.980500 1.379906e+06 1.413100e+06 1.443074e+06
50% 3179.510000 3192.935000 3182.990000 3164.000000 ... 3188.116000 1.614503e+06 1.606943e+06 1.637024e+06
75% 3287.012500 3303.150000 3289.902500 3270.470000 ... 3297.524000 1.920979e+06 1.905979e+06 1.866792e+06
max 3563.640000 3587.030000 3559.470000 3534.200000 ... 3477.327000 2.529509e+06 2.481610e+06 2.355928e+06
[8 rows x 13 columns]
除了获取丰富的交易数据之外,Tushare库还能获取到股票的分类信息数据(行业分类、概念分类、地域分类、中小板分类、创业板分类、风险警示板分类、沪深300成份股及权重、上证50成份股、中证500成份股、终止上市股票列表、暂停上市股票列表)、影响股票价格走势的信息数据(分配预案、业绩预告、限售股解禁、基金持股、新股上市、融资融券)、所有股票的基本面数据(业绩预告、业绩报告、盈利能力数据、营运能力数据、成长能力数据、偿债能力数据、现金流量数据)等等,这些都可以作为量化策略模型的因子纳入到模型的计算中,比如二级市场交易中,经常会以”概念”来炒作,那么在一些统计套利方法中,可以以股票的概念分类来做切入,根据概念分类来监测资金等信息的变动情况,制定近期的交易策略。这里我们使用 get_concept_classified() 接口来获取股票的概念分类数据,我们看到Tushare库相对来说还是很方便、很强大的。
df_concept = ts.get_concept_classified()#概念分类
print (df_concept.head(20))
code name c_name
0 600007 中国国贸 外资背景
1 600114 东睦股份 外资背景
2 600132 重庆啤酒 外资背景
3 600182 S佳通 外资背景
4 600595 中孚实业 外资背景
5 600641 万业企业 外资背景
6 600779 水井坊 外资背景
7 600801 华新水泥 外资背景
8 600819 耀皮玻璃 外资背景
9 000001 平安银行 外资背景
10 000005 世纪星源 外资背景
11 000541 佛山照明 外资背景
12 000608 阳光股份 外资背景
13 000659 *ST中富 外资背景
14 000869 张 裕A 外资背景
15 000895 双汇发展 外资背景
16 000932 *ST华菱 外资背景
17 000935 四川双马 外资背景
18 002032 苏 泊 尔 外资背景
19 002047 宝鹰股份 外资背景
20 600023 浙能电力 核电核能
本小节分别介绍了Pandas和Tushare获取股票交易数据的方法。需要注意的是,Pandas返回的数据顺序为由升序排列,即2017-01-03到2018-11-23,而Tushare的顺序刚好相反,这里推荐大家必要时使用升序 sort_index() 方法和降序方法 sort_index(ascending=False) 进行调整。Pandas返回的对象行索引为datetime64[ns]类型,而Tushare返回的对象行索引为object,另外Pandas和Tushare返回的对象列索引大小写是不同的。同学们可以根据自己的偏好选择自动获取股票数据的方法。