1.前言
数据模型是软件开发的重要一环,影响我们对问题的思考等
如今有很多不同的数据模型,每个都对处理的数据有一定的假设。
有些数据模型简单易用有些不是。
有些操作迅速有些不是。
本章讲解一些数据查询以及存储的模型
2.数据模型
2.1关系数据模型
如sql,涉及表,列之类的,不展开了,比较常见
2.2NoSql
即not only sql,有如下优点
- 拓展性强,能存储大量数据或者实现高吞吐
- 开源免费
- 支持一些关系模型不太支持的查询语句
- 关系模型需要schmea,而Nosql更动态,更灵活
2.3object-relational mismatch
在sql数据模型中,需要一个object与表中的行和列的匹配(如何把一个pojo和一行表记录互相转换)
ORM(object-relational mapping)框架如Hibernate和Mybatis等等就用来进行转换
2.4一个简历的设计demo(一对多的关系适合文档模型)
一个简历,如果用关系数据模型表示,大概如下图

缺陷在于各个表之间的关联,外键的处理等
对于建立这种'自包含'的文档,用json格式的文档模型会比较合适
如
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}
感觉上json减少了ORM的工作,但是第4章会讲到json表示的其他问题.
json不需要schema常被称为优点
json表示有更好的局部性,相较多表的schema而言
多表处理中要各种外键join
而文档数据模型里面,一次查询就足够
文档模型适合这种一对多的关系,如下图
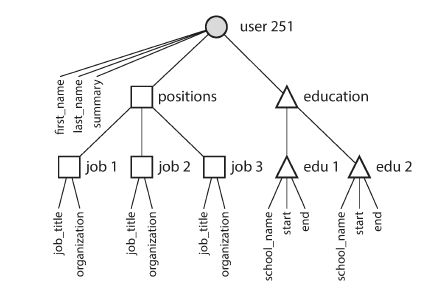
2.5 多对一关系和多对多关系
书上讲解一下关系模型中ID的重要性,这里不赘述了
然后讲关系数据模型的规范化问题,参照refer的wiki链接即可。
由此规范化,使得关系数据模型更适合多对一以及多对多的场景
通过外键,join操作在关系数据模型中常见,
而join在文档模型中的支持较弱
2.6 文档数据模型是否在重复历史
这里讲了一下数据模型的历史(之前我也没听说过),大意就是
原来70年代是有关系数据模型和网络模型的
网络模型也罢记录中的所有数据存在一颗树上,奖项文档模型的json格式一样
就是树状结构中,去掉了一个节点只能有一个parent的限制
查询起来不是靠外键,而是靠一个类似于“指针”的东西,来指向next节点
那么查询一个结构,就类似于从网络上找到一条路径(听起来就麻烦),还得自己记录整个路径,可能有多种不同路径来到达
后来网络模型基本消失了
那么文档模型会步网络模型的后尘吗
结论是否定的,文档模型和关系模型都会根据一个id去进行查询
可以看上面2.4中json表示的数据结构,可是有id的
"user_id": 251,
2.7关系模型和文档模型比较
本章之比较数据模型间,不考虑容错和并发处理等(第5,7章讲)
2.7.1如何方便写代码
如果程序中的数据类似文档结构(树形,一对多)那么用文档模型
如果有多对多,多对一的模型,就用关系模型
2.7.2文档模型的模式(schema)灵活性
文档模型有模糊的schema,因为读的时候需要对结构有一定的假设,不由数据库控制,更多的称为(schema-on-read)
相反的是关系模型中明确的schema,称为schema-on-write,要求所有数据满足该结构
两者类似于动态类型检查和静态编译类型检查
比如一个表记录了用户全名,现在想根据它添加两列,名和姓
那么文档模型操作如下

关系模型操作如下

模式的改动会造成变慢,需要downtime,因为经常需要copy这个表
因此
如果不要求所有记录有同样的结构,文档模型更好:
1.不可能像关系数据库那样操作,会为每个不同的object建立不同的表
2.满足不断改变的场景和需求
如果要求记录结构相同,那还是用schema,即关系模型
2.7.3数据查询的局部性
大意就是
文档模型里面,整篇文档(如简历里面的各种属性job,school等等)都存在一起。
适合一次性需要文档的大部分内容(否则浪费)
缺陷就是要求更新时,文档的size尽量不要变化(否则不是easily performed)
而关系模型里面,通过外键和join(和job表,school表等等)关联在一起
要求更多的disk seek和花更多的时间
2.7.4文档数据库和关系数据库的收敛
现在大多数sql支持存储xml,并且修改xml一部分内容,在xml内索引,查询,就类似文档数据库了
似乎关系数据库和文档数据库会越来越相似
2.8数据查询语言
sql是声明式的声明式语言,大多数编程语言是命令式的
比如命令式语言如下

这里引用一下refer,两者的异同和优缺点

后面讲了一个web页上的声明式查询 P44 这里忽略
再讲了一个MapReduce相关查询 P46 这里忽略
2.9 图数据模型
对于社交图谱,网页引用(如pageRank),交通结构这些,都适合图数据模型
结合自己学的图论的基础(点,边,出度,入度之类的)很好理解
比如下例

讲解了Cypher,Triple-Stores和SPAROL这些图数据库语言的应用以及如何用sql实现(WITH RECURSIVE)
然后说明了图数据库和之前销声匿迹的网络模型的区别 P60
这里不展开了
3.总结
数据模型太多了这里只讲了一部分
文档,关系,图数据模型至今都在广泛应用
选择什么数据模型,不是一个一刀切的问题
感受
感觉科普了一波nosql
了解了文档模型和关系模型的优缺点和适用场景
数据模型和网络模型的历史(2.6部分)
两个模型不同的模式 (2.7.1部分)
两个模型 数据查询的局限性(2.7.2部分)
知道了声明式语言和命令式语言(2.8)
还有图数据库(2.9)
问题
我对nosql并不是非常了解,不清楚nosql是否会需要orm,感觉上不用
nosql和文档数据模型是等价的吗,似乎大部分nosql都是文档数据模型
mapReduce那一块暂时没有看
refer
https://www.jianshu.com/p/91d3d9169d58
https://zh.wikipedia.org/wiki/%E6%95%B0%E6%8D%AE%E5%BA%93%E8%A7%84%E8%8C%83%E5%8C%96