豆瓣时期
我在豆瓣工作的时候,主要是写 Douban App Engine 。大体上它和 GAE 类似,有自己的 SDK 和服务端的 Runtime。因为是对内使用,所以在 SDK 和 Runtime 实现细节上,我们并没有像 GAE 那样做太多的 Mock 来屏蔽一些系统层面的 API(比如重写 OS库等)。对于一家大部分都是使用 Python 的公司而言,我们只做了 Python 的 SDK 和 Runtime,我们基于 Virtualenv 这个工具做了运行时的隔离,使得 App 之间是独立分割的。但是在使用过程中,我们发现有些运行时的隔离做得并不是很干净,比如说我们自己在 Runtime 使用了 werkzeug 这个库来实现一些控制逻辑,然后叠加应用自身 Runtime 的时候可能因为依赖 Flask 因此也安装了另一个 werkzeug 这个库,那么到底用哪个版本的就成了我们头疼的一个问题了。
一开始我们考虑修改 CPython 来做这件事,包括一些 sys.path 的黑魔法,但是发现成本太高,同时要小心翼翼的处理依赖和路径关系,后面就放弃使用这种方法了,采用分割依赖来最小化影响,尽量使得 Runtime 层叠交集最小。
进入 2013 年之后,Docker 在 3 月默默的发布了第一个版本,我们开始关注起来。紧接着我就离职出发去横穿亚洲大陆了,一路上我一直对 Docker 持续关注并思考如何通过它来做一个或者改造一个类似 DAE 一样的 PaaS,直到我回国。机缘巧合之下,我加入到芒果TV隶属于平台部门,有了环境便开始尝试我在路上时产生的这些想法。
芒果TV 的 Nebulium Engine
加入芒果TV之后,一开始我实现了类似于 DAE 架构的一个新的 PaaS —— Nebulium Engine(a.k.a NBE),只不过运行时完全用 Docker 来隔离,控制层移到了 Container 之外。除此之外,整体架构上和 DAE 并未有太多的差别。另外由于这边并没有一个大一统的强势语言,所以我们把 Runtime 的控制权完全交给了业务方。综合大半年线上运行结果来看,在资源管理和工作流整合上面,其实 NBE 做得并不是很好。原因有很多,一方面是公司基础设施没有豆瓣那么完善,另外一方面还是因为语言五花八门,完全放开 Runtime 控制层在对资源竞争和预估这两方面平台层面就完全没法做了,而恰恰这两方面对于业务而言非常重要。
于是在 2014 年年底重新回顾关于 Borg 和 Omega 的文章之后,我们开始了第二代目 NBE —— Project Eru 的开发。这一次我们基本完全抛弃了以前的设计思路,不再是实现一个 PaaS,而是一个类似于 Borg 一样的服务器编排和调度的平台。
Project Eru
有了第一代 NBE 的开发经验,我们明显开发速度快了很多,第二周的时候就已经有了一个大体上面用的 demo。到目前为止,Eru 平台可以混编 Offline 和 Online 的服务(binary/script),对于资源尤其是 CPU 资源实现了自由维度(0.1,0.01,0.001等)的弹性分配,使用 Redis 作为数据总线对外进行消息发布,动态感知集群所有的 Containers 状态并监控其各项数据等。基于 Docker 的 Images 特性我们很好的跟 Git 给结合起来,实现了 Github Workflow 的自动化 Build/Test 流程,统一了线上操作,同时也使得线上的各语言运行时都不会有“污染”的问题,并且能很快速的进行部署/扩容/缩容。
业务层方面在逻辑上我们使用了类似于 Kubernetes 的 Pod 来描述一组资源,使得 Eru 有了 Container 的组资源控制的能力。但是和 Kubernetes 不同的是,我们 Pod 仅仅是逻辑上的隔离,主要用于业务的区分,而实际的隔离则基于我们的网络层。通过标准化的 App.yaml 我们统一 Dockerfile 的生成,通用化的 Entrypoint 则满足了业务一份代码多个角色的复用和切换,使得任何业务几乎都可以完全无痛的迁移上来。
同时这个项目上我们放弃了以前考虑的完整闭环设计。之前实现的 NBE 第一代打通了项目整个生命周期的每一个环节,但实际上落地起来困难重重,并且使得 Dot(Master)的状态太重没法 Scale Out,因此是它是单点部署,可靠性上会糟糕一些。所以 Eru 中每一个 Core 都是一个完整的无状态的逻辑核心,使得其可以 Scale Out 的同时可靠性上也比 NBE 第一代要好健壮得多。任何业务可以根据自身业务特性,通过监控自身数据,订阅 Eru 广播,调用 Eru-Core 的 API ,实现复杂的自定义的部署扩容等操作。
细节
Eru 主要分 Core 和 Agent 两个部分。Agent 和 Core 并没有很强的耦合,通过 Redis 来交互信息(依赖于我们自己的 Redis Cluster 集群技术),主要用来汇报本机 Containers 情况和做一些系统层面的操作(比如增加减少 veth)。Core 则是刚才所说无状态的逻辑核心,控制所有的 Docker Daemon 并且和 Agent 进行控制上的交互。
容器内存储上,我们目前大部分使用了 Devicemapper 小部分是 Overlay,因此我们有的 Docker Host 上使用了内核 3.19 的内核,并外挂了一个 MooseFS 作为容器间数据共享的卷。考虑到 Docker 本身大部分时间是版本越新越靠谱(1.4是个悲剧),因此基本上我们使用的都是最新版的 Docker。网络方面对比了若干个解决方案之后,在隧道类(Weave/OVS等)和路由类(MacVLAN/Calico等)中我们选择了后者中的 MacVLAN。

网络
相比于 Route 方案,Tunnel 方案灵活度会更高,但是会带来两个问题:
- 性能,比如 Weave,通过 UDP 封装数据包然后广播到其他跑着 Weaver 的 Host,封包解包的过程就会带来一些开销。另外大多数 OVS 方案性能其实都不太乐观,之前和某公司工程师交流过,大体上会影响 20%~30% 左右的吞吐性能。
- Debug 困难。Tunnel 的灵活是构建在 Host 间隧道上的,物理网络的影响其实还没那么大,但是带来一个弊端就是如果现在出了问题,我怎样才能快速的定位是物理链路还是隧道本身自己的问题。
而 Route 方案也会有自己的问题:
- Hook,Route 方案需要 Container Host 上有高权限进程去 Hook 系统 API 做一些事情。
- 依赖于物理链路,因此在公有云上开辟新子网做 Private SDN 使得同类 Containers 二层隔离就不可能了。
- 如果是基于 BGP 的 Calico,那么生效时间差也可能带来 Container 应用同步上的一些问题。
网络之所以选择 MacVLAN 主要是考虑到我们组人少事多,隧道类方案规模大了之后 Debug 始终是一件比较麻烦的事情,路由方案中 MacVLAN 从理解上和逻辑上是最简单的一个方案。
使用这种方案后,我们可以很容易在二层做 QoS,按照 IP 控流等,这样避免了使用 tc(或者修改内核加强 tc)去做这么一件事件,毕竟改了内核你总得维护对吧。因为是完全独立的网络栈,性能上也比 Weave 等方案表现得好太多,当然还有二层隔离带来的安全性。
某种意义上 MacVLAN 对 Container 耦合最小,但是同时对物理链路耦合最大。在混合云上,无论是 AWS 也好还是青云亦或者微软的 Azure,对二层隔离的亲和度不高,主要表现在不支持自定义子网上。因此选取这个方案后,在混合云上是没法用的。所以目前我们也支持使用 Host 模式,使得容器可以直接在云上部署,不过这样一来在云上灵活度就没那么高了。
存储
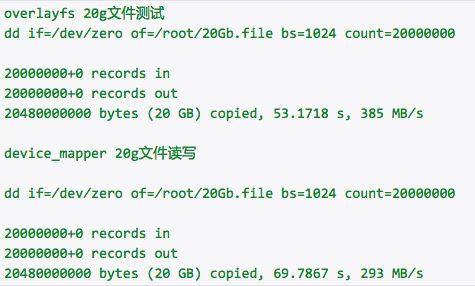
容器内存储我们目前对这个需求不是太高,小部分选取 Overlay 主要是为了我们 Redis Cluster 集群方案上 Eru 之后 Redis 的 AOF 模式需要,目前来看情况良好。在 Devicemapper 和 Overlay 的性能对比上,大量小文件持续写 Overlay 的性能要高不少。
对于我们现有的 Redis Cluster 集群,我们采用内存分割的方式部署 Container。一个 Container 内部的 Redis 限制在 Host 总内存数/ Container 数这么大。举个栗子,我们给 Redis 的 CPU 分配为 0.5 个,一台机器 24 Core 可以部署 48 个 Container,而我们的 Host 申请下来的一般只有 64G,因此基本上就是 1G 左右一个 Redis Container 了。
这样会有2个好处:
- AOF 卡顿问题得到缓解。
- 数据量或者文件碎片量远远达不到容器内存储的性能上限,意外情况可控。
Scale
扩容和缩容,我们更加希望是业务方去定制这么组件去做。我们所有的容器基础监控数据均存储在了 influxdb 上面,虽然现在来看它不是蛮靠谱(研究 Open-falcon 中)。业务方也可以写入其自定义数据到任何其他服务中,所以实现上业务方可以通过读取这些数据(基础容器监控数据和业务方自己数据),判断并决策,然后调取 Core 的 API 去做相应的事情即可,因此平台这边并不需要熟悉业务特性,对业务扩容缩容也更加弹性一些。
谁关心,谁做
资源分配和集群调度
资源分配我们采取的是 CPU 为主,MEM 半人工审核机制。磁盘 IO 暂时没有加入到 Eru 豪华午间套餐,而流量控制交给了二层控制器。之所以这么选择主要是因为考虑到一个机房建设成本的时候,CPU 的成本是比较高的,因此以 CPU 为主要调度维度。在和腾讯的讲师聊过之后,关于 CPU 的利用率上我们也实现了掰开几分用这么个需求,当然,这也是可以设置的,因此我们不会局限于 0.1 这个粒度,0.01或者 0.5 都是可以的,并且是 Pod 的自身属性。内存方面的话,我们并没有实现 softlimit subsystem 在内核中,主要还是通过数据判断 Host 内存余量和在上面 Container 内存使用量/申明量对比来做旁路 OOM Kill。
以 CPU 为主维度的来调度上,我们把应用申请 CPU 的数目计算为两类,一类称之为独占核,一类为碎片核。一个 Container 有且仅有一个碎片核,比如申请为 3.2 个 CPU 的话(假定一个 Cpu 分为 10 份),我们会通过 CpuSet 参数设定 4 个核给这个 Container,然后统一设定 CpuShare 为 1024*2。其中一个核会跟其他 5个 Container 共享,实现 Cpu 资源的弹性。
目前我们暂不考虑容器均匀部署这么个需求,因为我们对应的都是一次调度几台甚至几十台机器的情况,单点问题并不严重。
所以在应用上线时,会经过这些步骤:
- 申报内存最大使用量和单个 Container CPU 需求。比如 1G 1.5个CPU。
- 请求在哪个 Pod 上进行上线。
- Eru 计算 Pod 中剩余 CPU 资源是否足够这一次上线的请求数量。
- 足够的话开始锁定 CPU 资源,调度 Host 上的 Docker Daemon 开始部署。
另外我们加入了一个 Public Server 的机制,不对机器的 CPU 等资源做绑定,只从宏观的 Host 资源方面做监控和限制。使得 Eru 本身可以对服务进行降级操作,实际上我们用这种 Host 现在跑了一部分单元测试的工作。
服务发现和安全
对于服务发现和安全控制,我们把控制权交给了业务方和运维部门。一般情况下同类 Container 将会在同一个子网之中(就是依靠 SDN 的网络二层隔离,一组 Container 理论上都会在一个或者多个同类子网中),调用者接入子网即可调用这些 Container。同时我们也把防火墙策略放到了二层上,保证其入口流量安全。因而整体上,对于业务部门而言,服务基本上说一个完整的黑箱(组件),他们并不需要关心服务的部署细节和分布情况,他们看到的是一组 IP (当然使用内网 DNS 的话会更加透明),同一子网内才有访问权限,直接调用就完了。我们认为一个自建子网内部是安全的。
另外我们基于 Dnscache 和 Skydns 构建了可以实时生效的内网 DNS 体系,分别部署在了我们现有的三个机房里面。业务方可以自行定义域名用来描述这个服务(其实是一组 Container),完全不需要关心服务背后的物理链路物理机器等,实现了线上的大和谐。
举个栗子
目前我们 Redis Cluster 有 400个 instance,10个集群,按照传统方式部署。每一次业务需求到我们这边之后我们需要针对业务需求调配服务器,初始化安装环境,并做 instance 部署的操作。在我们完成 Redis instance Dockerize 之后,Redis Cluster Administrator 只需要调取 API biu 一个最小集群,交付子网入口 IP 即可(或者内网域名)。遇到容量不足则会有对应的 Redis Monitor 来自动调用 Eru API 扩容,如果过于清闲也能非常方便的去缩容。现在已经实现了秒级可靠的 Redis 服务响应和支撑。
此外我们打算上线的另一个服务也打算基于这一套平台来解决自动扩容问题。通过 Eru 的 Broadcasting 机制结合 Openresty 的 lua 脚本动态的更新服务的 Upstream 列表,从而使得我们这样平时 500 QPS 峰值 150K QPS 的业务不再需要预热和准备工作,实现了无人值守。
总结
我们整个 Eru 项目设计思路都是以组合为主,依托于我们现有的 Redis 解决方案,我们通过“消息”把各个组件串了起来,从而使得整个平台的扩展性和自由度达到我们的需求。除了一些特定的方法,比如构建 Image,其他的诸如构建 Dockerfile,如何启动应用等,我们均不做强一致性的范式去规范业务方/服务方怎么去做,当然这和我们公司本身体系架构有关,主要还是为了减少落地成本。毕竟不是每个公司业务线都有能力和眼界能接受和跟上。
最后我们现在主要在搞 Redis instance Dockerize 这么一件事,又在尝试把大数据组 Yarn task executor docker 化。在这个过程中我们搞定了 sysctl 的参数生效,容器内权限管理等问题,那又是另外一个故事了……我们计划今年年末之前,业务/服务/离线计算 3个方向,都会开始通过 Eru 这个项目构建的平台开始 Docker 化调度和部署,并对基于此实现一个 PaaS。