ApacheSqoop(SQL-to-Hadoop)项目旨在协助RDBMS与Hadoop之间进行高效的大数据交流。用户可以在Sqoop的帮助下,轻松地把关系型数据库的数据导入到Hadoop与其相关的系统(如HBase和Hive)中;同时也可以把数据从Hadoop系统里抽取并导出到关系型数据库里。除了这些主要的功能外,Sqoop也提供了一些诸如查看数据库表等实用的小工具。理论上,Sqoop支持任何一款支持JDBC规范的数据库,如DB2、MySQL等。Sqoop还能够将DB2数据库的数据导入到HDFS上,并保存为多种文件类型。常见的有定界文本类型,Avro二进制类型以及SequenceFiles类型。在本文里,统一用定界文本类型。
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。
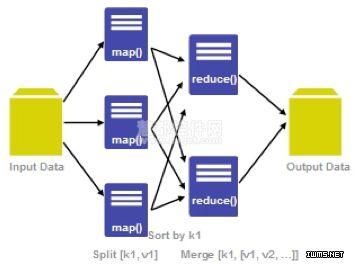
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。比如selectmax(split_by),min(split-by)from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为selectXXXfromtablewheresplit-by>=1andsplit-by<500和selectXXXfromtablewheresplit-by>=501andsplit-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
Sqoop大概流程
读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
设置好job,主要也就是设置好以上第六章中的各个参数
这里就由Hadoop来执行MapReduce来执行Import命令
1) 首先要对数据进行切分,也就是DataSplit,DataDrivenDBInputFormat.getSplits(JobContext job)
2) 切分好范围后,写入范围,以便读取DataDrivenDBInputFormat.write(DataOutput output),这里是lowerBoundQuery and upperBoundQuery
3) 读取以上2)写入的范围DataDrivenDBInputFormat.readFields(DataInput input)
4) 然后创建RecordReader从数据库中读取数据DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)
5) 创建MAP,MapTextImportMapper.setup(Context context)
6) RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给MapDBRecordReader.nextKeyValue
7) 运行MAP,mapTextImportMapper.map(LongWritable key, SqoopRecord val, Context context),最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get
Sqoop1和Sqoop 2架构的变迁
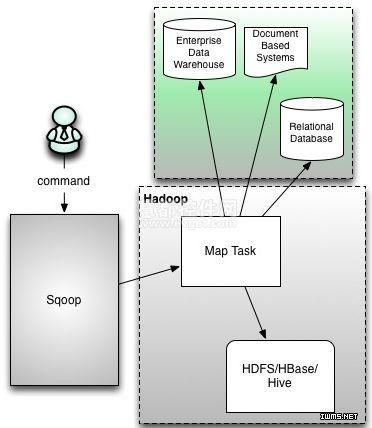
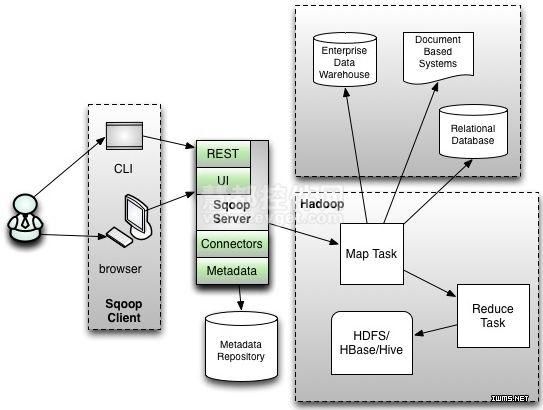
首先这两个版本是完全不兼容的,其具体的版本号区别为1.4.x为sqoop1,1.99x为sqoop2。sqoop1和sqoop2在架构和用法上已经完全不同。在架构上,sqoop1仅仅使用一个sqoop客户端,sqoop2引入了sqoopserver,对connector实现了集中的管理。其访问方式也变得多样化了,其可以通过RESTAPI、JAVAAPI、WEBUI以及CLI控制台方式进行访问。另外,其在安全性能方面也有一定的改善,在sqoop1中我们经常用脚本的方式将HDFS中的数据导入到mysql中,或者反过来将mysql数据导入到HDFS中,其中在脚本里边都要显示指定mysql数据库的用户名和密码的,安全性做的不是太完善。在sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到,同时Sqoop2引入基于角色的安全机制。下图是sqoop1和sqoop2简单架构对比:
Sqoop1架构图:
Sqoop2架构图:
sqoop1优点:架构部署简单
sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏, 安装需要root权限,connector必须符合JDBC模型
sqoop2优点:多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
sqoop2缺点:架构稍复杂,配置部署更繁琐