- 行的union
- pd.concat
- df.append
- 列的join
- pd.concat
- pd.merge
- df.join
- 行列转置
- pivot
- stack & unstack
- melt
本文示例数据下载,密码:vwy3
import pandas as pd
# 数据是之前在cnblog上抓取的部分文章信息
df = pd.read_csv('./data/SQL测试用数据_20200325.csv',encoding='utf-8')
# 为了后续演示,抽样生成两个数据集
df1 = df.sample(n=500,random_state=123)
df2 = df.sample(n=600,random_state=234)
# 保证有较多的交集
# 比例抽样是有顺序的,不加random_state,那么两个数据集是一样的
行的union
pandas 官方教程
pd.concat
pd.concat主要参数说明:
- 要合并的dataframe,可以用
[]进行包裹,e.g.[df1,df2,df3]; - axis=0,axis是拼接的方向,0代表行,1代表列,不过很少用pd.concat来做列的join
- join='outer'
- ignore_index: bool = False,看是否需要重置index
如果要达到union all的效果,那么要拼接的多个dataframe,必须:
- 列名名称及顺序都需要保持一致
- 每列的数据类型要对应
如果列名不一致就会产生新的列
如果数据类型不一致,不一定报错,要看具体的兼容场景
df2.columns
输出:
Index(['href', 'title', 'create_time', 'read_cnt', 'blog_name', 'date', 'weekday', 'hour'], dtype='object')
# 这里故意修改下第2列的名称
df2.columns = ['href', 'title_2', 'create_time', 'read_cnt', 'blog_name', 'date','weekday', 'hour']
print(df1.shape,df2.shape)
# inner方法将无法配对的列删除
# 拼接的方向,默认是就行(axis=0)
df_m = pd.concat([df1,df2],axis=0,join='inner')
print(df_m.shape)
输出:
(500, 8) (600, 8)
(1100, 7)
# 查看去重后的数据集大小
df_m.drop_duplicates(subset='href').shape
输出:
(849, 7)
df.append
和pd.concat方法的区别:
- append只能做行的union
- append方法是outer join
相同点:
- append可以支持多个dataframe的union
- append大致等同于
pd.concat([df1,df2],axis=0,join='outer')
df1.append(df2).shape
输出:
(1100, 9)
df1.append([df2,df2]).shape
输出:
(1700, 9)
列的join
pd.concat
pd.concat也可以做join,不过关联的字段不是列的值,而是index
也因为是基于index的关联,所以pd.concat可以对超过2个以上的dataframe做join操作
# 按列拼接,设置axis=1
# inner join
print(df1.shape,df2.shape)
df_m_c = pd.concat([df1,df2], axis=1, join='inner')
print(df_m_c.shape)
输出:
(500, 8) (600, 8)
(251, 16)
这里是251行,可以取两个dataframe的index然后求交集看下
set1 = set(df1.index)
set2 = set(df2.index)
set_join = set1.intersection(set2)
print(len(set1), len(set2), len(set_join))
输出:
500 600 251
pd.merge
pd.merge主要参数说明:
- left, join操作左侧的那一个dataframe
- right, join操作左侧的那一个dataframe, merge方法只能对2个dataframe做join
- how: join方式,默认是inner,str = 'inner'
- on=None 关联的字段,如果两个dataframe关联字段一样时,设置on就行,不用管left_on,right_on
- left_on=None 左表的关联字段
- right_on=None 右表的关联字段,如果两个dataframe关联字段名称不一样的时候就设置左右字段
- suffixes=('_x', '_y'), join后给左右表字段加的前缀,除关联字段外
print(df1.shape,df2.shape)
df_m = pd.merge(left=df1, right=df2\
,how='inner'\
,on=['href','blog_name']
)
print(df_m.shape)
输出:
(500, 8) (600, 8)
(251, 14)
print(df1.shape,df2.shape)
df_m = pd.merge(left=df1, right=df2\
,how='inner'\
,left_on = 'href',right_on='href'
)
print(df_m.shape)
输出:
(500, 8) (600, 8)
(251, 15)
# 对比下不同join模式的区别
print(df1.shape,df2.shape)
# inner join
df_inner = pd.merge(left=df1, right=df2\
,how='inner'\
,on=['href','blog_name']
)
# full outer join
df_full_outer = pd.merge(left=df1, right=df2\
,how='outer'\
,on=['href','blog_name']
)
# left outer join
df_left_outer = pd.merge(left=df1, right=df2\
,how='left'\
,on=['href','blog_name']
)
# right outer join
df_right_outer = pd.merge(left=df1, right=df2\
,how='right'\
,on=['href','blog_name']
)
print('inner join 左表∩右表:' + str(df_inner.shape))
print('full outer join 左表∪右表:' + str(df_full_outer.shape))
print('left outer join 左表包含右表:' + str(df_left_outer.shape))
print('right outer join 右表包含左表:' + str(df_right_outer.shape))
输出:
(500, 8) (600, 8)
inner join 左表∩右表:(251, 14)
full outer join 左表∪右表:(849, 14)
left outer join 左表包含右表:(500, 14)
right outer join 右表包含左表:(600, 14)
df.join
df.join主要参数说明:
- other 右表
- on 关联字段,这个和pd.concat做列join一样,是关联index的
- how='left'
- lsuffix='' 左表后缀
- rsuffix='' 右表后缀
print(df1.shape,df2.shape)
df_m = df1.join(df2, how='inner',lsuffix='1',rsuffix='2')
df_m.shape
输出:
(500, 8) (600, 8)
(251, 16)
行列转置
pandas 官方教程
# 数据准备
import math
df['time_mark'] = df['hour'].apply(lambda x:math.ceil(int(x)/8))
df_stat_raw = df.pivot_table(values= ['read_cnt','href']\
,index=['weekday','time_mark']\
,aggfunc={'read_cnt':'sum','href':'count'})
df_stat = df_stat_raw.reset_index()
df_stat.head(3)
如上所示,df_stat是两个维度weekday,time_mark
以及两个计量指标 href, read_cnt
pivot

# pivot操作中,index和columns都是维度
res = df_stat.pivot(index='weekday',columns='time_mark',values='href').reset_index(drop=True)
res
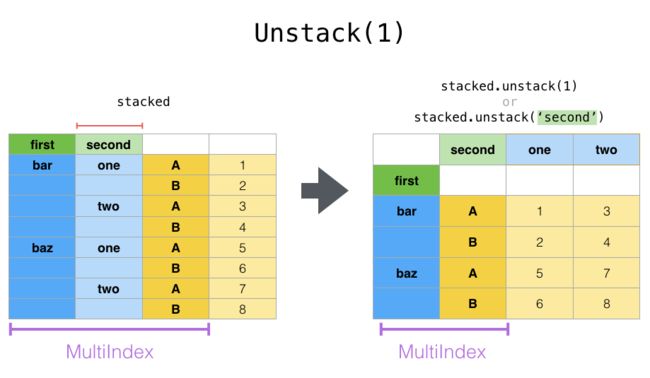
stack & unstack
- stack则是将层级最低(默认)的column转化为index
- unstack默认是将排位最靠后的index转成column(column放到下面)
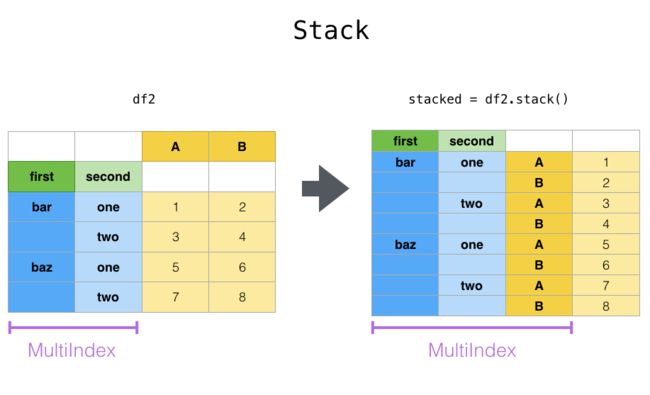

# pandas.pivot_table生成的结果如下
df_stat_raw
# unstack默认是将排位最靠后的index转成column(column放到下面)
df_stat_raw.unstack()
# unstack也可以指定index,然后转成最底层的column
df_stat_raw.unstack('weekday')
# 这个语句的效果是一样的,可以指定`index`的位置
# stat_raw.unstack(0)
# stack则是将层级醉倒的column转化为index
df_stat_raw.unstack().stack().head(5)
# 经过两次stack后就成为多维表了
# 每次stack都会像洋葱一样将column放到左侧的index来(放到index序列最后)
df_stat_raw.unstack().stack().stack().head(5)
输出:
weekday time_mark
1 0 href 4
read_cnt 2386
1 href 32
read_cnt 31888
2 href 94
dtype: int64
pd.DataFrame(df_stat_raw.unstack().stack().stack()).reset_index().head(5)
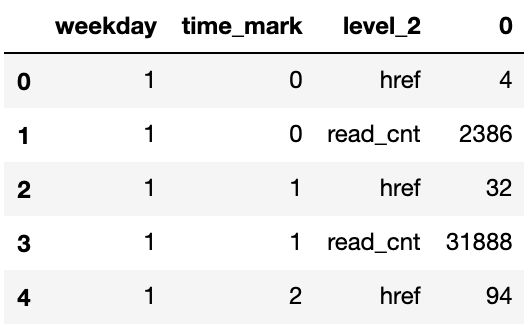
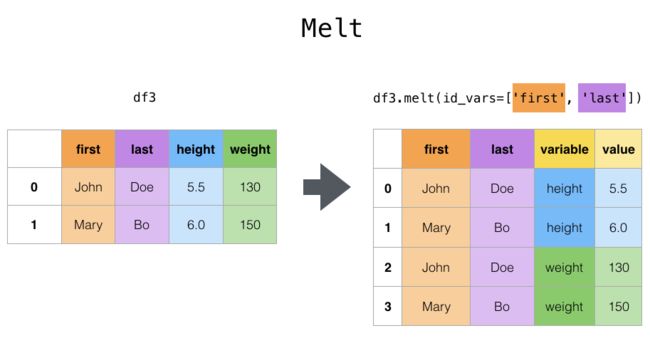
melt
melt方法中id_vals是指保留哪些作为维度(index),剩下的都看做是数值(value)
除此之外,会另外生成一个维度叫variable,列转行后记录被转的的变量名称
print(df_stat.head(5))
df_stat.melt(id_vars=['weekday']).head(5)
df_stat.melt(id_vars=['weekday','time_mark']).head(5)