接上两篇:
- 《KubeSphere排错实战》
- 《KubeSphere排错实战二》
在之后使用kubesphere中也记录了一些使用问题,希望可以对其他人有帮助,一块体验如丝般顺滑的容器管理平台。
十四 异常容器删除
之前利用helm部署过consul,后面删除consul
[root@master ~]# helm delete consul --purge经查看consul的一个pod状态一直为Terminating
[root@master ~]# kubectl get pods -n common-service
NAME READY STATUS RESTARTS AGE
consul-1 1/2 Terminating 1 24d
redis-master-0 1/1 Running 1 17d
redis-slave-0 1/1 Running 1 8d
redis-slave-1 1/1 Running 1 17d查看状态
[root@master ~]# kubectl describe pods consul-1 -n common-service
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedSync 3m41s (x4861 over 22h) kubelet, node02 error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded处置建议:
- 升级到docker 18. 该版本使用了新的 containerd,针对很多bug进行了修复。
- 如果出现terminating状态的话,可以提供让容器专家进行排查,不建议直接强行删除,会可能导致一些业务上问题。
怀疑是17版本dockerd的BUG。可通过 kubectl -n cn-staging delete pod apigateway-6dc48bf8b6-clcwk --force --grace-period=0 强制删除pod,但 docker ps 仍看得到这个容器
[root@master ~]# kubectl -n common-service delete pod consul-1 --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "consul-1" force deleted
[root@master ~]# kubectl get pods -n common-service
NAME READY STATUS RESTARTS AGE
redis-master-0 1/1 Running 1 17d
redis-slave-0 1/1 Running 1 8d
redis-slave-1 1/1 Running 1 17d在node2上查看
[root@node02 ~]# docker ps -a |grep consul
b5ea9ace7779 fc6c0a74553d "/entrypoint.sh /run…" 3 weeks ago Up 3 weeks k8s_consul_consul-1_common-service_5eb39c90-8503-4125-a2f0-63f177e36293_1
13192855eb6f mirrorgooglecontainers/pause-amd64:3.1 "/pause" 3 weeks ago Exited (0) 23 hours ago k8s_POD_consul-1_common-service_5eb39c90-8503-4125-a2f0-63f177e36293_0使用便捷资源状态来释放,存在 Finalizers,k8s 资源的 metadata 里如果存在 finalizers,那么该资源一般是由某程序创建的,并且在其创建的资源的 metadata 里的 finalizers 加了一个它的标识,这意味着这个资源被删除时需要由创建资源的程序来做删除前的清理,清理完了它需要将标识从该资源的 finalizers 中移除,然后才会最终彻底删除资源。比如 Rancher 创建的一些资源就会写入 finalizers 标识。
处理建议:kubectl edit 手动编辑资源定义,删掉 finalizers,这时再看下资源,就会发现已经删掉了。
十五 k8s日志异常排除
经过从v2.0升级到v2.1后面经过查看kubesphere没有了日志
首先排除负责日志收集的相关pods是否正常,Fluent Bit + ElasticSearch
[root@master ~]# kubectl get po -n kubesphere-logging-system
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-curator-elasticsearch-curator-158086m9zv5 0/1 Completed 0 2d13h
elasticsearch-logging-curator-elasticsearch-curator-158095fmdlz 0/1 Completed 0 37h
elasticsearch-logging-curator-elasticsearch-curator-158103bwf8f 0/1 Completed 0 13h
elasticsearch-logging-data-0 1/1 Running 1 8d
elasticsearch-logging-data-1 1/1 Running 774 69d
elasticsearch-logging-discovery-0 1/1 Running 478 56d
elasticsearch-logging-kibana-94594c5f-q7sht 1/1 Running 1 22d
fluent-bit-2b9kj 2/2 Running 2 23h
fluent-bit-bf52m 2/2 Running 2 23h
fluent-bit-pkb9f 2/2 Running 2 22h
fluent-bit-twd98 2/2 Running 2 23h
logging-fluentbit-operator-56c6b84b94-4nzzn 1/1 Running 1 23h
logsidecar-injector-5cbf7bd868-cr2kh 1/1 Running 1 11d
logsidecar-injector-5cbf7bd868-mp46g 1/1 Running 1 22d之前知道日志通过es存储,将kubesphere-logging-system的将es的service映射为NodePort模式,查看索引,发现只有jaeger的
curl elasticsearch-logging-data.kubesphere-logging-system.svc:9200/_cat/indices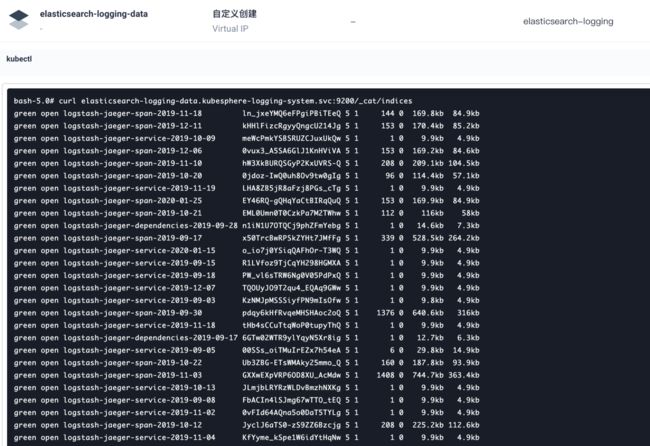
经过查看索引正常
查看Fluent bit 的日志

[root@master ~]# kubectl -n kubesphere-logging-system logs -f fluent-bit-2b9kj -c fluent-bit
I0207 13:53:25.667667 1 fluentbitdaemon.go:135] Start Fluent-Bit daemon...
Fluent Bit v1.0.5
Copyright (C) Treasure Data
[2020/02/07 13:53:26] [ info] [storage] initializing...
[2020/02/07 13:53:26] [ info] [storage] in-memory
[2020/02/07 13:53:26] [ info] [storage] normal synchronization mode, checksum disabled
[2020/02/07 13:53:26] [ info] [engine] started (pid=15)
[2020/02/07 13:53:26] [ info] [filter_kube] https=1 host=kubernetes.default.svc port=443
[2020/02/07 13:53:26] [ info] [filter_kube] local POD info OK
[2020/02/07 13:53:26] [ info] [filter_kube] testing connectivity with API server...
[2020/02/07 13:53:36] [ warn] net_tcp_fd_connect: getaddrinfo(host='kubernetes.default.svc'): Name or service not known
[2020/02/07 13:53:36] [error] [filter_kube] upstream connection error
[2020/02/07 13:53:36] [ warn] [filter_kube] could not get meta for POD fluent-bit-2b9kj之前由于系统盘磁盘原因,将docker容器数据迁移至数据盘,由于是链接形式,导致收集日志异常。
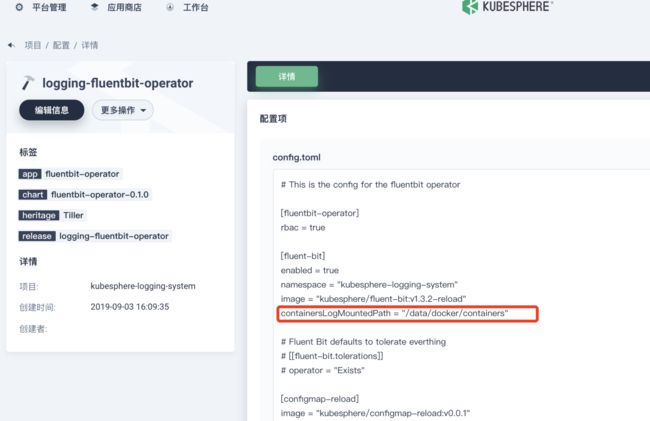
Step 1. 添加 containersLogMountedPath 到 ConfigMap ks-installer。具体路径根据实际环境填充
[root@master docker]# docker info -f '{{.DockerRootDir}}'
/data/docker
[root@master docker]# ll /var/lib/docker
lrwxrwxrwx. 1 root root 12 Oct 10 19:01 /var/lib/docker -> /data/docker
Step 2. 等待 installer 自动更新 fluent-bit operator 的 ConfigMap,大概几分钟。直到 containersLogMountedPath 更新到 ConfigMap(尽量不要直接修改这个 ConfigMap,以免影响以后升级)。
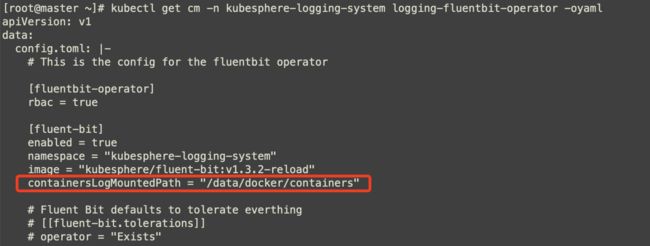
Step 3. 重启 Flunet Bit
# 删除 fluent-bit Daemonset
[root@master ~]# kubectl scale -n kubesphere-logging-system deployment logging-fluentbit-operator --replicas=0
deployment.extensions/logging-fluentbit-operator scaled
[root@master ~]# kubectl delete -n kubesphere-logging-system daemonsets fluent-bit
daemonset.extensions "fluent-bit" deleted
# 重启 Fluent-bit Operator Deployment
[root@master ~]# kubectl scale -n kubesphere-logging-system deployment logging-fluentbit-operator --replicas=1
deployment.extensions/logging-fluentbit-operator scaled
# 检查 fluent-bit 是否起来
[root@master ~]# kubectl get po -n kubesphere-logging-system
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-curator-elasticsearch-curator-158086m9zv5 0/1 Completed 0 2d13h
elasticsearch-logging-curator-elasticsearch-curator-158095fmdlz 0/1 Completed 0 37h
elasticsearch-logging-curator-elasticsearch-curator-158103bwf8f 0/1 Completed 0 13h
elasticsearch-logging-data-0 1/1 Running 1 8d
elasticsearch-logging-data-1 1/1 Running 774 69d
elasticsearch-logging-discovery-0 1/1 Running 478 56d
elasticsearch-logging-kibana-94594c5f-q7sht 1/1 Running 1 22d
fluent-bit-5rzpv 0/2 ContainerCreating 0 3s
fluent-bit-nkzdv 0/2 ContainerCreating 0 3s
fluent-bit-pwhw7 0/2 ContainerCreating 0 3s
fluent-bit-w5t8k 0/2 ContainerCreating 0 3s
logging-fluentbit-operator-56c6b84b94-d7vgn 1/1 Running 0 5s
logsidecar-injector-5cbf7bd868-cr2kh 1/1 Running 1 11d
logsidecar-injector-5cbf7bd868-mp46g 1/1 Running 1 22d当所有nodes的fluent-bit启动后,可以查看日志已经恢复
参考:https://github.com/kubesphere/kubesphere/issues/1476
参考:https://github.com/kubesphere/kubesphere/issues/680
十六 k8s存储
有pod运行异常,查看事件为存储异常,查看ceph状态为异常
[root@master test]# ceph -s
cluster 774df8bf-d591-4824-949c-b53826d1b24a
health HEALTH_WARN
mon.master low disk space
monmap e1: 1 mons at {master=10.234.2.204:6789/0}
election epoch 14, quorum 0 master
osdmap e3064: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v9076023: 192 pgs, 2 pools, 26341 MB data, 8231 objects
64888 MB used, 127 GB / 190 GB avail
192 active+clean
client io 17245 B/s wr, 0 op/s rd, 4 op/s wr
kubelet默认有gc,在此进行手动清理docker文件
# 查看文件
[root@master overlay2]# docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 34 12 8.463GB 5.225GB (61%)
Containers 46 21 836.6kB 836.5kB (99%)
Local Volumes 4 0 59.03MB 59.03MB (100%)
Build Cache 0 0 0B
# 清理文件
[root@master overlay2]# docker system prune
WARNING! This will remove:
- all stopped containers
- all networks not used by at least one container
- all dangling images
- all dangling build cache
Are you sure you want to continue? [y/N] y 十七 修改kube-proxy模式为iptables为ipvs
- 每个节点之间modeprobe
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
yum install -y ipset ipvsadm
kubectl get configmap kube-proxy -n kube-system -oyaml查看目前ipvsadm没有规则
[root@master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
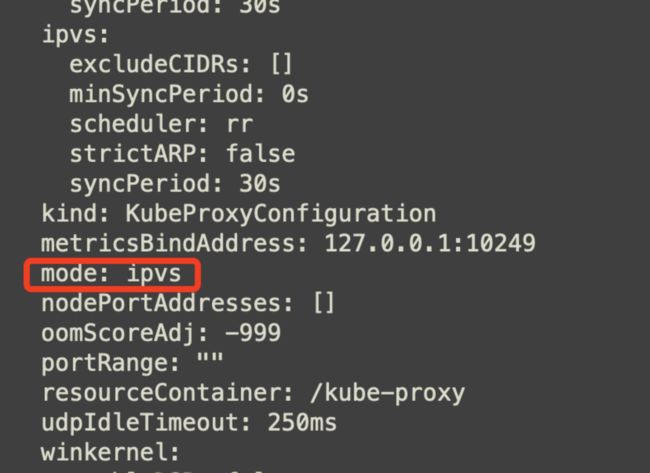
-> RemoteAddress:Port Forward Weight ActiveConn InActConn- 在master节点修改kube-proxy的configmap中的ipvs的mode为ipvs
进行之前kube-proxy pod的删除
[root@master ~]# kubectl get pod -n kube-system|grep kube-proxy|awk '{print "kubectl delete po "$1" -n kube-system"}'|sh
pod "kube-proxy-2wnst" deleted
pod "kube-proxy-bfrk9" deleted
pod "kube-proxy-kvslw" deleted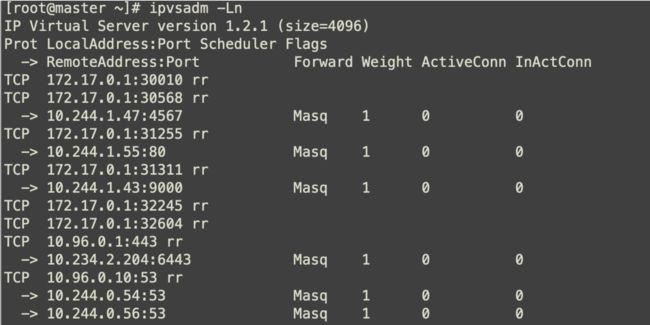
通过ipvsadm查看已经切换过来。
十八 应用安装
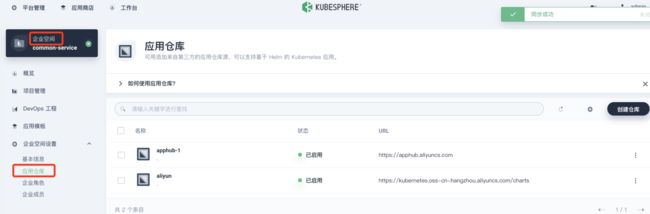
在排错实战二中记录了利用终端来安装应用,在kubesphere2.1中将可以利用web界面在企业空间下安装意见添加的应用仓库中的应用,再次记录下操作步骤
- 在企业空间的应用仓库中添加repo
- 在具体的项目中的应用安装选择来自应用模版
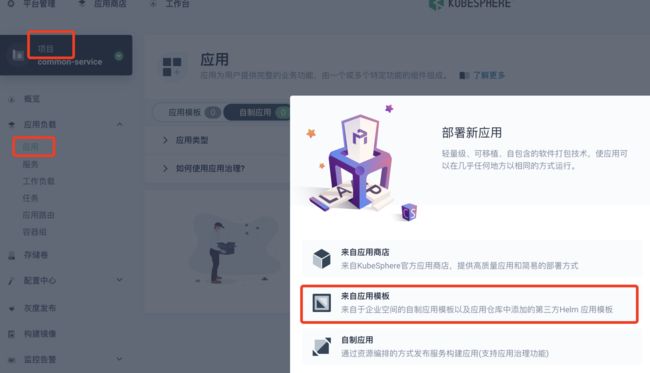
- 选择repo源,搜索需要的charts包
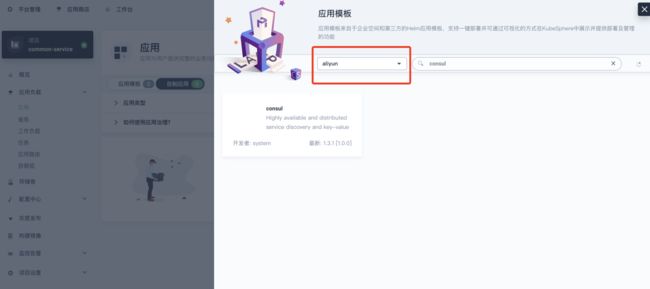
十九 服务治理
通过KubeSphere非常的将自己的应用赋能服务治理能力,利用istio的sidercar模式注入envoy来实现服务网格的一些列金丝雀发布,负载均衡,流量检测管控,限流熔断降级等。目前将自己的应用测试了微服务的治理,感觉非常好用,后期有机会记录下过程。

自己整理了k8s学习笔记,有兴起的可以一快学习交流:https://github.com/redhatxl/awesome-kubernetes-notes
支持国产容器管理平台KubeSphere,为社区尽自己的一份绵薄之力。