
小麦穗粒数转录组分析(三)-----Fst的计算
本期作者:Neal
Hi,大家好!今天非常惊喜的看到两篇Pm21的文章以背靠背的形式发表在Molecular Plant上,去年的时候这两篇文章都在预印本biorxiv网站上在线了,当时我们也推送了两篇有关的内容,Pm21,掀起你的盖头来,Pm21的“盖头”被完全掀开——有着一张熟面孔。这种背靠背的形式发表文章一来大家互相验证,二来影响力要远远高于单独发表。我们在2017年的总结中也提到了Pm21的克隆,年度盘点:2017年小麦研究领域的重大事件。再次对这两个团队表示祝贺。那些做图位克隆的小伙伴也要加油哈!
好了,我们言归正传。这是本系列的第三集。这是前面的两集,小麦穗粒数转录组分析(一),小麦穗粒数转录组分析(二)——SNP的筛选。忘了的同学可以回顾一下。
我都不知道该如何开始这个话题。Fst是用来描述种群内和种群间差异的一种衡量指标,表示一个种群内两个亚群等位基因频率差异的某种标准化,是差异性的一种代表。当Fst较小时,表示两个群体间差异较小,反之亦然。基于Fst可以进行选择性消除分析。比方说,我们已知有两个小麦群体,一个是育成品种群体,它们的农艺性状普遍较好,也即是人工选择的结果;另外一个是地方品种群体,它们更多的是长期自然选择的结果。说到人工选择,不同时期人们的偏好会不一样,有一段时期会追求某一方面的性状,而过一段时期又会追求另外的性状。当我们收集了不同群体的基因型之后,我们就可以做一些群体进化方面的分析。比如,我想知道河南省最近10年推广的品种中哪些基因组区段受到了选择。再比如,我收集了100份千粒重很高的品种和100份千粒重比较低的材料,我们就可以比较这个群体里在某些区段等位基因频率的差异,那些等位基因频率差异很大的区域就是受到选择的区域。
大家可以参见徐洲更同学写的这一篇会算Fst还不够,还得知道它的用途,也可以参见这一篇文章,群体遗传进化必备小知识,我就不再搬砖了。
回到我们的话题。前面我们提到这90份微核心种质,包括两个群体,一个是包含16份育成品种群体,剩下的是地方品种群体。这一群体的信息,可以查阅文章“Transcriptome Association Identifies Regulators of Wheat Spike Architecture”。现在我们可以试着计算这两个群体之间的Fst。
使用的工具是vcftools, 这实在是一个犀利的工具,今天我们只谈一谈如何使用vcftools计算Fst。命令如下,
```
vcftools --vcf 90_mini_core_UG_first_third_filter_eff.vcf --weir-fst-pop EV_population.txt --weir-fst-pop L_population.txt --out pop1_vs_pop2 --fst-window-size 500000 --fst-window-step 50000
# 90_mini_core_UG_first_third_filter_eff.vcf是我们前面得到的vcf文件;
# EV_population.txt是一个包含品种名字的文件,每行一个品种。这里的品种名字要和vcf的名字对应
# L_population.txt 是另外一个包含品种名字的文件,即地方品种群体。
#计算的窗口是500kb,而步长是50kb。我们也可以只计算每个点的Fst,去掉参数(--fst-window-size 500000 --fst-window-step 50000)即可。
```
输出结果如下面的格式:
CHROMBIN_STARTBIN_ENDN_VARIANTSWEIGHTED_FSTMEAN_FST
chr1A700001120000010.24290.2429
chr1A750001125000030.3102950.300006
chr1A800001130000030.3102950.300006
chr1A8500011350000100.3114090.306106
chr1A9000011400000100.3114090.306106
chr1A9500011450000100.3114090.306106
chr1A10000011500000100.3114090.306106
chr1A10500011550000100.3114090.306106
chr1A11000011600000100.3114090.306106
根据上述表格我们就可以画图,或者查看我们关心的区域。
�dirpath=("/Users/Desktop/scripts/snpEff_latest_core/snpEff")
setwd(dirpath)
library(ggplot2)
data<-read.table("./pop1_vs_pop2_repeat.weir.fst",header=T)
chr6B = subset(data,CHROM=="chr6B")
#这里只选择了6B这条染色体来看。
p <- ggplot(chr6B,aes(x=POS/1000000,y=WEIR_AND_COCKERHAM_FST)) + geom_point(size=0.5, colour="blue") + xlab("Physical distance (Mb)")+ ylab("Fst") + ylim(-1,1)
p + theme_bw()�
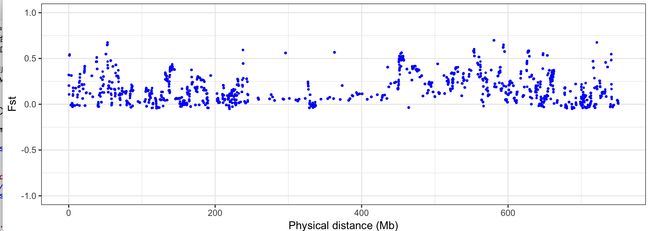
今天就到这里了,Fst结果的筛选和生物意义挖掘,大家可以参加这方面的文章。这方面我也是第一次做,没啥经验,大家有想法的话可以交流,加“wheatgenome”即可。
欢迎关注“小麦研究联盟”,了解小麦新进展

投稿、转载、合作以及信息分布等请联系:wheatgenome