卡顿是非常直观的用户体验,它的特点是:产生原因错综复杂,线上问题难以复现。基于这个特点,卡顿优化主要是三方面工作:
- 卡顿的有效信息收集:线上线下监控方案。
- 卡顿分析与定位:通过工具和日志定位卡顿问题。
- 具体卡顿问题的解决:细化为内存、CPU、绘制、稳定性(ANR、Crash、Watchdog)等具体问题,再通过内存优化、调度优化、绘制优化、稳定性问题处理去解决具体问题。
那么老规矩,写文章之前先列个大纲:

一、知识储备
1.1 CPU与GPU

图出处:网上找的,出处未知,知道的可以告诉我。
- CPU:ALU设计复杂但是数量少,擅长在短时间内完成复杂的逻辑运算,响应快,但是吞吐性有限。
- GPU:ALU设计简单但是数量多,擅长高密度、单一无依赖的简单逻辑运算,帮CPU分担此类任务的吞吐要求。
1.2 软件绘制与硬件绘制
最早的Android版本用的是软件绘制,也就是视图的绘制计算和栅格化渲染都由CPU来处理,而视图的渲染工作属于高密度、单一无依赖的简单逻辑运算交给CPU处理显然不是高效的做法,因此在Android4.0之后默认使用硬件绘制,让GPU负责栅格化渲染,提升整体效率。
1.3 绘制框架与相关机制
在Android系统中,CPU负责计算显示内容,GPU负责栅格化渲染,Display负责消费显示内容。
他俩三者之前有两个同步机制来关联:
1)vsync: Android4.1引入,解决刷新同步问题。

引入vsync前:第二帧CPU和GPU去干别的了没有及时参与绘制任务,所以引入一个vsync来通知CPU和GPU这个时间段先把手头其他非绘制相关的任务放一放先来处理绘制任务。
引入vsync后:加入vsync之后,UIThread有视图更新会由Choreographer主动去请求vsync,收到信号后CPU和GPU开始工作,而SurfaceFlinger同样是需要自己主动去请求vsync来完成layer合成任务。这样整个视图刷新流程就同步了,且是按需触发。
2)fence:Android4.4引入,解决跨硬件资源同步问题。
Android整个绘制渲染过程是一个生产者消费者模型,内容通过buffer进行传递,buffer具有拥有权和使用权。拥有权通过向BufferQueue申请和释放buffer来切换,而使用权通过fence来保证。
fence类型:每一个layer都有一个acquireFence和releaseFence,每一个系列layes都有一个retirefence。
- acquireFence: 禁止显示一个buffer的内容直到该fence被触发。
- releaseFence: 一个buffer不再被读取的时候将会触发。
- retirefence:整个一帧显示完了。

注:图中橙色为release fence,绿色为acquire fence。图出处: https://blog.csdn.net/lewif/article/details/51007148
这里有两对生产者消费者模式:

1.4 绘制流程
这里整理从UI更新到SurfaceFlinger合成整个流程,一图胜千言:
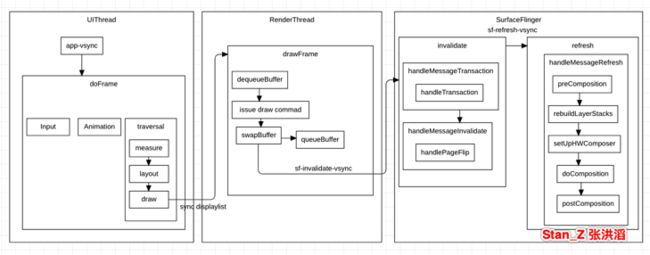
1.5 卡顿原理
1帧绘制耗时在systrace上表示:
- 绿色:< 1* vsync
- 黄色:1 * vsync - 2 * vsync之间
- 红色:> 2 * vsync
1个vsync最低要求是60fps,也就是需要在16.67ms内完成一帧的绘制,在这个时间内,重点关注红色丢帧点,黄色看情况,绿色是流畅。另外我们经常用平均帧率来衡量界面流畅度,在没有明显连续丢帧情况下,平均帧率40还是50用户并不一定能感觉到不流畅,而真正的卡顿感在于连续丢帧(尤其出现较多的红色帧)和更严重的冻帧(连续丢42帧以上)情况。
卡顿优化就是监控和分析由于哪些因素的影响导致绘制渲染任务没有在一个vsync的时间内完成。尤其关注连续丢帧点。
二、卡顿监控
线下:这里主要是借用一些性能检测工具
- StrictMode: 帮助开发者发现代码中的一些不规范的问题,以达到提升应用响应能力的目的。
检测线程策略和虚拟机策略:
1)线程策略 :UI线程中自定义方法、磁盘IO、网络操作等耗时。
2)虚拟机策略:Activity泄漏、Sqlite对象泄漏、检测实例数量等排查。
BlockCanary: 动态检测消息执行耗时。
基于消息机制,向Looper中设置Printer,监控dispatcher到finish之间的操作,满足耗时阀值dump堆栈、设备信息,以通知形式弹出卡顿信息以供分析。TraceView:追踪一段时间的方法调用栈,弥补耗时盲区监控。
可以配合Systrace一起使用,Systrace宏观定位卡顿区域,TraceView细化该区域调用栈,以此来找出耗时方法。
线上:数据打点收集
帧率统计
使用Choreographer postFrameCallback监控应用帧率,注意只在界面存在绘制时统计。dispatchMessage耗时监控
与BlockCanary原理一致,区别是dump信息做本地持久化,考虑到如果dump的时候,耗时方法已经执行完毕了,那么最终抓取的信息只是表象并不是现场,为了提升数据有效性,在监控开始和结束之间高频采集堆栈,同时为了减少服务器压力,可以做信息去重。单点问题监控
应用侧:
非one way的binder IPC调用耗时统计 (hook BinderProxy.transact)
setContentView耗时统计
页面从onCreate到onWindowFocusChanged耗时统计
Activity/Fragement 生命周期耗时统计
…
这类统计可以采用AOP方式进行非侵入式打点。
hook art:Epic
hook 自己代码:AspectJ
系统侧:
系统本身就包含了非常多的日志信息,这部分会到后面的卡顿分析来介绍。
三、卡顿分析
卡顿分析这部分是基于系统角度来分析,因为系统角度更加全面,能涵盖到应用问题和系统问题,盲区比应用视角少。
卡顿问题主要分为稳定复现和不能稳定复现两类,尤其是后者是占绝大多数的。两类情况都能通过bugreport来分析,如果能稳定复现那还能通过systrace来分析。
3.1 bugreport
特点:用户抓取成本低,可以存储较久的日志,有价值信息少,且不一定有现场。
bugreport抓取:adb bugreport > bugreport.txt
预判日志:
日志有效性判断:Uptime
Uptime: up 0 weeks , 3 days , 4hours , 15minutes
如果Uptime过小,比如几分钟,可初步判断次日志为用户重启手机后抓的,为无效日志
日志dump时间判断:dumpsite: begin
一般用户主动抓取bugreport,基本上是忍受不了dump之前不久的某个非常明显的卡顿,因此这个时间点往前推容易找到案发现场,缩小分析范围。
是否刚OTA升级:Upgrading
可判断是否是用户升级后立刻用手机造成的卡顿。Android OTA升级后有之前应用的主apk和插件的编译文件均失效,都需要重新编译,一方面dex2oat或多或少的占用了CPU,另一方面走解释模式也会慢很多。
原生日志:
- 内存
cat proc/meminfo
MemTotal: 2914764 kB
MemFree: 78008 kB 系统空闲内存(系统尚未被使用的,total-free = used)
MemAvailable: 440972 kB 可用内存(memfree + 可回收内存(部分buffer/cached,slab也能回收一部分))
...
SwapTotal: 1048572 kB 交换空间的总大小(设置的zram交换空间大小)
SwapFree: 471124 kB 未被使用交换空间的大小
...
Slab: 176044 kB 内核中slab分配的内存大小(slab = SReclaimable+SUnreclaim)
SReclaimable: 55528 kB 可收回Slab的内存大小
SUnreclaim: 120516 kB 不可收回Slab的内存大小
MemFree偏低、SwapFree偏低 、lowmemoryKiller打印频繁、kswapd0 cpu占用率偏高 能体现出系统内存偏低。如果能配合现场的systrace,出现明显的Uninterruptible sleep状态,能更一步确认卡顿点是否由内存不足造成。
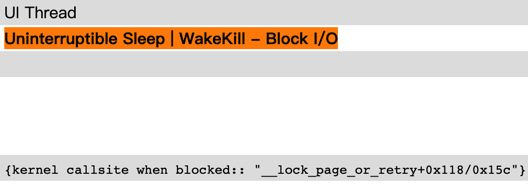
app:有频繁的gc: Background concurrent copying GC; block GC,虽然每次单独gc pasue时间不长,但是短时间有大量gc的话会有内存抖动造成卡顿。
- CPU
dumpsys cpuinfo
CPU usage from 7324ms to 1913ms ago:
272% 8611/dex2oat: 131% user + 140% kernel / faults: 3470 minor
...
85% TOTAL: 44% user + 41% kernel + 0.2% iowait + 0% softirq
关注下当前是否有cpu 占用率非常高的进程,常见的比如:dex2oat、kswapd0、logd等。另外可以关注下iowait的百分比。另外cpu部分还需要注意的是:低电拔核和高温限频的问题,这个策略各厂商会有差异,这部分可配合BatteryHistorian来分析。
常用的获取cpu相关信息的操作:
获取手机cpu架构相关信息:
$ cat /sys/devices/system/cpu/possible 获取CPU核心数
$ cat /sys/devices/system/cpu/ 路径下有cpu0 - cpuN 每个节点保存对应核的信息
$ sys/devices/system/cpu/cpu0/cpufreq # ls -al 以cpu0为例,分别获取当前频率、最大频率、最小频率信息。
-r-------- 1 root root 4096 2020-03-03 15:23 cpuinfo_cur_freq
-r--r--r-- 1 root root 4096 2020-03-03 15:23 cpuinfo_max_freq
-r--r--r-- 1 root root 4096 2020-03-03 15:23 cpuinfo_min_freq
如何确认CPU架构?哪几个核是大核哪几个是小核?
如果知道平台的话,去查下平台架构就好了,如果不知道那就用傻办法一个个核去记录max_freq,对比下就知道了。
cat proc/self/sched 获取进程调度相关信息
...
//主动上下文切换次数,因为线程无法获取所需资源导致上下文切换,最普遍的是IO。
nr_voluntary_switches : 0
//被动上下文切换次数,线程被系统强制调度导致上下文切换,例如大量线程在抢占CPU。
nr_involuntary_switches : 3
...
//IO 等待的次数
se.statistics.iowait_sum : 0.000000
//IO 等待的时间
se.statistics.iowait_count : 0
...
查看当前top应用的CPU消耗情况
top
Tasks: 782 total, 2 running, 780 sleeping, 0 stopped, 0 zombie
Mem: 7.4G total, 5.4G used, 2.0G free, 1.8M buffers
Swap: 2.0G total, 438M used, 1.5G free, 1.8G cached
800%cpu 6%user 4%nice 8%sys 780%idle 0%iow 2%irq 0%sirq 0%host
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
11586 u0_a213 20 0 8.5G 200M 166M S 9.0 2.6 0:48.06 com.xiaomi.smarthome
13703 root 20 0 38M 4.6M 3.2M R 2.6 0.0 0:00.21 top
965 system 12 -8 2.4G 25M 15M S 2.0 0.3 36:54.33 surfaceflinger
1676 system 10 -10 9.1G 285M 285M S 1.6 3.7 73:41.29 system_server
查看进程状态以及CPU占用情况
ps -p 11586
用户名 进程ID 父进程ID 虚拟内存大小 常驻内存大小 内存运行状态 进程状态
USER PID PPID VSZ RSS WCHAN ADDR S NAME
u0_a213 11586 704 8953760 204316 do_epoll_+ 0 S com.xiaomi.smarthome
进程状态:
R (running) S (sleeping) D (device I/O) T (stopped) t (traced)
Z (zombie) X (deader) x (dead) K (wakekill) W (waking)
ps -o PCPU -p 11586
%CPU
7.0
更多操作参考:Linux环境下进程的CPU占用率
- 持锁
dvm_lock_sample 当某个线程等待lock的时间blocked超过阈值(比如:500ms),则输出当前的持锁状态。
dvm_lock_sample: [system_server,1,Binder_9,1500,ActivityManagerService.java,6403,-,1448,0]
说明:
等锁的线程:system_server: Binder_9,
它执行到ActivityManagerService.java的6403行代码,一直在等待AMS锁, "-"代表持锁的是同一个文件,
即该锁被同一文件的1448行代码所持有, 从而导致Binder_9线程被阻塞1500ms.
binder_sample 监控每个进程的主线程的binder transaction的耗时情况, 当超过阈值(比如:500ms)时,则输出相应的目标调用信息。
2754 2754 I binder_sample: [android.app.IActivityManager,35,2900,android.process.media,5]
主线程2754,执行android.app.IActivityManager接口,所对应方法code =35(即STOP_SERVICE_TRANSACTION),所花费时间为2900ms,该block所在package为 android.process.media.最后一个参数是sample比例(没有太大价值)
am_lifecycle_sample 当app在主线程的生命周期回调方法执行时间超过阈值(比如:3000ms),则输出相应信息。
02-23 11:02:35.876 8203 8203 I am_lifecycle_sample: [0,com.android.systemui,114,3837]
说明: pid=8203, processName=com.android.systemui, MessageCode=114(CREATE_SERVICE), 耗时3.827s
注意: MessageCode=200 (并行广播onReceive耗时), 其他Code见 ActivityThread.H类。
例举两类情况:
应用主线程等子线程的锁:子线程持锁做耗时任务,子线程出现优先级倒挂。
应用主线程binder call等系统服务的大锁,比如系统在做dump。
- 编译
02-28 10:02:36.794 10162 8025 8025 I dex2oat : /system/bin/dex2oat -j6 --dex-
file=/data/user/0/com.baidu.searchbox/app_megapp/com.baidu.raphael.apk
--output-vdex-fd=61 --oat-fd=62 --oat-location=/data/user/0/com.baidu.searchbox/app_megapp/oat/arm/com.baidu.raphael.odex
--compiler-filter=quicken --class-loader-context=&
02-28 10:02:56.485 10162 8025 8025 I dex2oat : dex2oat took 19.705s (1.258s cpu) (threads: 6) arena alloc=18KB (19000B)
java alloc=1148KB (1175712B) native alloc=2MB (2189680B) free=1957KB (2004624B)
filter参考:
[pm.dexopt.bg-dexopt]: [speed-profile] 后台
[pm.dexopt.boot]: [verify] ota升级
[pm.dexopt.first-boot]: [quicken] 首次启动
[pm.dexopt.install]: [speed-profile] 应用安装
- 系统事件分发
InputDispatcher findFocusWindow是否有问题?
*窗口暂停 Waiting because the %s window is paused.
*窗口未连接 Waiting because the %s window's input channel is not registered with the input dispatcher. The window may be in the process of being removed.
*窗口连接死亡 Waiting because the %s window's input connection is %s The window may be in the process of being removed.
*窗口连接已满 Waiting because the %s window's input channel is full. Outbound queue length: %d. Wait queue length: %d.
*按键事件,输出队列或事件等待队列不为空 Waiting to send key event because the %s window has not finished processing all of the input events that were previously delivered to it. Outbound queue length: %d. Wait queue length: %d.
*非按键事件,事件等待队列不为空且头事件分发超时500ms Waiting to send non-key event because the %s window has not finished processing certain input events that were delivered to it over %0.1fms ago. Wait queue length: %d. Wait queue head age: %0.1fms.
- Slow Operation
系统加了很多操作耗时日志,例如:
02-27 15:59:29.983 1000 2846 2846 W Activity: Slow Operation: Activity com.android.settings/.wifi.WifiConfigActivity onResume took 318ms
- doFrame Late
反映doFrame消息被delay执行
11-12 16:33:38.900 10222 26115 26115 I Choreographer: Skipped 245 frames! The application may be doing too much work on its main thread.
这里记录接收到vsync之后,doFrame消息发送到执行之间的时间。这里只能反映当前应用主线程looper因为执行之前的消息耗时导致了当前doFrame执行delay了。
这里简单提一嘴同步屏障:
ViewRootImpl.scheduleTraversals() postSyncBarrier设置了同步屏障,然后post了TRAVERSAL类型的callback,接下来在TraversalRunnable中执行的doTraversal() removeSyncBarrier取消了同步屏障,在performTraversals(measure、layout、draw)之前。也就是说,同步屏障保护的是Choreographer的vsync信号请求和doFrame回调。在开启同步屏障的时间范围内,优先执行异步消息,保证doFrame的及时回调,但是同步屏障开启之前MessageQueue中就已经存在的Msg则依然在当前异步消息之前执行。那么由此可见,当前同步屏障开启后被delay的同步消息会在下一个同步屏障开启后的异步消息之前执行,所以个人感觉同步屏障的优化效果肯定是有,但是在某些情况下也没特别明显。
另外做个对比:
- Looper设置Printer 监控的是 dispatchMessage 耗时,即消息本身回调之后的执行耗时监控。
- Choreographer中doFrame Skipped XXX frames! 监控的是doFrame消息enqueue入MessageQueue到得到next的耗时,也就是doFrame被delay执行的监控。
- 稳定性
ANR :ANR in ,am_anr
Crash:FATAL EXCEPTION
WatchDog:Watchdog: *** WATCHDOGKILLING …
稳定性问题单独到稳定性部分再分析。
如果是小米手机,还有如下类型日志可提供分析:
- perfevents卡顿日志
09-27 16:49:10.034 5517 5551 W MiuiPerfServiceClient: interceptAndQueuing:4772|com.android.systemui|360|92|unknown|null|StatusBar|276169323224|Slow issue draw commands|14
说明:
4772 卡顿进程pid
com.android.systemui 卡顿进程名
360 卡顿总时长 (这里将相近的几次卡顿算作一起)
92 最长单次卡顿
unknown 卡顿原因(系统)
null 结论
StatusBar window 名
276169323224 时间戳
Slow issue draw commands
- Slow main thread: 主线程执行慢导致vsync处理延迟
- Slow handle input:处理输入事件处理慢
- Slow handle animation: 处理动画慢
- Slow handle traversal: 遍历View树慢。遍历时会执行layout和draw,View层次过深或者过度复杂的View结构会引起该问题
- Slow bitmap uploads: 渲染线程与UI线程间同步交换信息的时间过长。界面过度复杂、界面上使用的Bitmap过大、或者界面上使用的Bitmap过多会引起该问题
- Slow issue draw commands: 渲染线程执行draw时间过长。界面过度复杂过多会引起该问题
- Slow swap buffers:与sufaceflinger交换buffer时间过长,非应用问题
14 总帧数
- doFrame late 增强
对doFrame消息android.view.Choreographer$FrameHandler delay执行的补充,Choreographer: Skipped XXX frames! 我们只知道主线程丢了多少帧,没有更多信息。
统计时间范围:dispatch - finish
01-21 12:07:01.255 21147 21147 W Looper : Slow Looper: doFrame is 321ms late because of 12 msg,
msg 1 took 90ms (cputime=6ms late=50ms h=com.android.systemui.statusbar.CommandQueue$H w=655360),
msg 10 took 217ms (cputime=4ms late=110ms h=com.android.systemui.statusbar.CommandQueue$H w=589824)
说明:
有一帧的绘制 (doFrame) 迟了 321ms
导致掉帧的 321ms 中, Looper 执行了 12 个消息
第 1 个消息执行耗时 90ms, cpu running time 占 6ms, handler=com.android.systemui.statusbar.CommandQueue$H what=655360
第 10 个消息执行耗时 217ms, cpu running time 占 4ms, hander=com.android.systemui.statusbar.CommandQueue$H what=589824
第 1 个和第 10 个消息是耗时的主要原因, 也是掉帧主要原因
- Activity late
Activity生命周期耗时,它的生命周期执行是通过android.app.ActivityThread$H消息驱动的。
统计数据范围:equeue - dispatch
01-21 12:07:49.169 7619 7619 W Looper : Slow Looper: Activity com.android.quicksearchbox/.SearchActivity
is 633ms late (process=+54ms cputime=+8ms ClientTransaction{ lifecycleRequest=android.app.servertransaction
.PauseActivityItem }) because of 33 msg, msg 1 took 543ms (cputime=157ms late=1ms h=android.os.Handler
c=com.android.quicksearchbox.SearchActivity$a), msg 7 took 82ms (cputime=3ms late=650ms h=android.view
.Choreographer$FrameHandler c=android.view.Choreographer$FrameDisplayEventReceiver), msg 22 took 72ms
(cputime=5ms late=585ms h=com.miui.org.chromium.base.SystemMessageHandler w=1)
说明:
com.android.quicksearchbox 的 SearchActivity 的 onPause (PauseActivityItem) 回调迟了 633ms
导致回调迟的 633ms 中, Looper 执行了 33 个消息
第 1 个消息执行耗时 543ms, cpu running time 占 157ms, handler=android.os.Handler callback=com.android.quicksearchbox.SearchActivit$a
第 7 个消息执行耗时 82ms, cpu running time 占 3ms, hander=android.view.Choreographer$FrameHandler callback=android.view.Choreographer$FrameDisplayEventReceiver
第 22 个消息执行耗时 72ms, cpu running time 占 5ms, hander=com.miui.org.chromium.base.SystemMessageHandler what=1
这 3 个消息是耗时的主要原因, 也是导致 Activity 回调迟的主要原因
- Input超时日志
InputTransport: Slow Input : 372ms so far.
事件读取到分发之前的耗时,system_server进程部分的耗时
InputEventReceiver: App Input: Dispatching InputEvent took 114ms in main thread!
应用主线程处理事件耗时
- bugreport中或者kill -3主动抓取具体进程trace信息
配合如上日志一起分析,看再卡顿发生时调用栈执行情况。
举例一个持锁耗时:
04-12 22:01:45.082 1000 2053 3432 I dvm_lock_sample: [system_server,1,Binder:2053_13,76974,NetworkPolicyManagerService.java,4825,
boolean com.android.server.net.NetworkPolicyManagerService.isUidNetworkingBlockedInternal(int, boolean),-,4454,
void com.android.server.net.NetworkPolicyManagerService.handleUidChanged(int, int, long),0]
NetworkPolicyManagerService.isUidNetworkingBlockedInternal 等待NetworkPolicyManagerService.handleUidChanged释放锁,阻塞时间4.8s.
找到对应trace:
group="main" sCount=1 dsCount=0 flags=1 obj=0x13f373d8 self=0x700dc84c00
sysTid=2440 nice=-2 cgrp=default sched=0/0 handle=0x70030844f0
state=S schedstat=( 50991306302 53247097352 327406 ) utm=2739 stm=2360 core=4 HZ=100
stack=0x7002f81000-0x7002f83000 stackSize=1041KB
held mutexes=
at com.android.server.net.NetworkStatsService.setUidForeground(NetworkStatsService.java:837)
waiting to lock <0x07884b42> (a java.lang.Object) held by thread 48
at com.android.server.net.NetworkStatsService$NetworkStatsManagerInternalImpl.setUidForeground(NetworkStatsService.java:1427)
at com.android.server.net.NetworkPolicyManagerService.updateNetworkStats(NetworkPolicyManagerService.java:3546)
at com.android.server.net.NetworkPolicyManagerService.updateUidStateUL(NetworkPolicyManagerService.java:3512)
at com.android.server.net.NetworkPolicyManagerService.handleUidChanged(NetworkPolicyManagerService.java:4459)
locked <0x0843f32c> (a java.lang.Object)
at com.android.server.net.NetworkPolicyManagerService$18.handleMessage(NetworkPolicyManagerService.java:4435)
at android.os.Handler.dispatchMessage(Handler.java:102)
at android.os.Looper.loop(Looper.java:201)
at android.os.HandlerThread.run(HandlerThread.java:65)
at com.android.server.ServiceThread.run(ServiceThread.java:44)
NetworkPolicyManagerService.handleUidChanged持锁0x0843f32c之后又在等锁0x07884b42,而此锁被tid=48持有。
"NetworkStats" prio=5 tid=48 Native
group="main" sCount=1 dsCount=0 flags=1 obj=0x13f371b8 self=0x702181e400
sysTid=2438 nice=0 cgrp=default sched=0/0 handle=0x70037b64f0
state=D schedstat=( 4327126501422 339711898732 1487930 ) utm=320747 stm=111965 core=5 HZ=100
stack=0x70036b3000-0x70036b5000 stackSize=1041KB
held mutexes=
kernel: (couldn't read /proc/self/task/2438/stack)
native: #00 pc 000000000007b02c /system/lib64/libc.so (fsync+8)
native: #01 pc 0000000000003670 /system/lib64/libopenjdkjvm.so (JVM_Sync+20)
native: #02 pc 000000000001cd54 /system/lib64/libopenjdk.so (FileDescriptor_sync+40)
at java.io.FileDescriptor.sync(Native method)
at android.os.FileUtils.sync(FileUtils.java:197)
at com.android.server.DropBoxManagerService.add(DropBoxManagerService.java:280)
at com.android.server.DropBoxManagerService$2.add(DropBoxManagerService.java:139)
at android.os.DropBoxManager.addText(DropBoxManager.java:283)
at com.android.server.net.NetworkStatsService$DropBoxNonMonotonicObserver.foundNonMonotonic(NetworkStatsService.java:1734)
at com.android.server.net.NetworkStatsService$DropBoxNonMonotonicObserver.foundNonMonotonic(NetworkStatsService.java:1721)
at android.net.NetworkStats.subtract(NetworkStats.java:752)
at android.net.NetworkStats.subtract(NetworkStats.java:689)
at com.android.server.net.NetworkStatsRecorder.recordSnapshotLocked(NetworkStatsRecorder.java:230)
at com.android.server.net.NetworkStatsService.recordSnapshotLocked(NetworkStatsService.java:1229)
at com.android.server.net.NetworkStatsService.performPollLocked(NetworkStatsService.java:1285)
at com.android.server.net.NetworkStatsService.performPoll(NetworkStatsService.java:1260)
locked <0x07884b42> (a java.lang.Object)
at com.android.server.net.NetworkStatsService.access$800(NetworkStatsService.java:157)
at com.android.server.net.NetworkStatsService$HandlerCallback.handleMessage(NetworkStatsService.java:1679)
at android.os.Handler.dispatchMessage(Handler.java:102)
at android.os.Looper.loop(Looper.java:201)
at android.os.HandlerThread.run(HandlerThread.java:65)
tid=48 NetworkStats持有0x07884b42锁在做dump相关耗时操作。
3.2 systrace
特点:容易分析,但是抓取门槛高用户基本不会提供,依赖本地复现,存储信息时间有限,数秒信息就几十M。
因此systrace一般依赖于本地复现,当然它完全可以配合前面的bugreport一起来分析,相互印证结论。
systrace主要关注红色和黄色的丢帧点。
- 执行状态
- 目前跑在什么核上,对应核跑在什么频率上?如果当前CPU繁忙主要是被什么任务占据?
- 是否有频繁的runnable切换?首先判断是不是有频繁的非one way binder call,是否自身多线程竞争cpu?
- 是否有长时间sleep? 持锁耗时?层层追踪后续的runnable,看看当前的sleep是阻塞在哪。
- running时间过长?是否有具体方法耗时,或者走的解释模式。
- 频繁出现D状态?考虑内存问题 or IO问题。
- 具体方法耗时
增加systrace label,细化耗时方法,或者使用traceView来定位,如果牵涉到native层,则使用simplePerf。
常见原因:
- bindApplication:verfiyClass耗时、IO block等。
- Activity create:inflater视图耗时等。
- doFrame:视图复杂或者不合理requestLayout刷新导致measure、layout、draw耗时、ListView obtainView耗时、大图加载耗时等。
- 系统问题实战参考:启动耗时分析(四)-具体方法耗时分析
- 系统模块
- 跟手性/Input
adb shell getevent -ltr 滑动报点是否正常?看相关日志,
看systrace中system_server 的
iq:描述system_server中 InputReader读取事件
aq: 描述应用端获取事件
报点异常主要看iq,看一次down move(N) up 的流程是否顺畅。
事件传递是否有问题?
event是否在system_server中被drop掉?查找相关日志
中InputReader读出来的事件是否马上唤醒InputDispatcher进行分发?看个异常的systrace:
RenderThread block
这里主要是系统层面的问题了,例如gpu driver出问题,绘制没完成,会导致app queueBuffer阻塞,而如果display driver出问题无法释放buffer,如果此时triple buffer没有空闲的buffer,那么app dequeueBuffer也有可能被阻塞,当然 dequeueBuffer如果有buffer重新分配,分配内存出现问题,那也可能阻塞。这里需要结合日志具体问题具体分析。SurfaceFlinger 问题
SurfaceFlinger自身出问题基本很少,自身问题要么就是改buffer改出来的问题,要么是vsync出了问题。
四、卡顿常见问题梳理
这是我之前做的卡顿原因梳理,主要从绘制、调度、编译、内存几个方面进行分析。当然卡顿问题错综复杂,包含但不限于以上几个方面,并且有时候卡顿问题也可能是多个方面问题综合在一起出现的而非单一情况。因此个人认为卡顿优化的核心在于定位问题,定位到问题之后会细化成绘制、调度、编译、内存或者具体代码模块等问题去具体问题具体分析。
卡顿优化重点工作都是在打点监控以及分析定位问题上,这里具体问题分析处理就不详细介绍了,如果一个点一个点铺开分析,那篇幅也太长了,并且那也是属于垂直优化范畴了,具体就是稳定性优化、内存优化、绘制优化、CPU优化、线程优化等等。看看后续还有没有时间继续做盘点吧。
好文推荐
android graphic(16)-fence(简化)
Android中的GraphicBuffer同步机制-Fence
卡顿优化(上):你要掌握的卡顿分析方法
卡顿优化(下):如何监控应用卡顿?
Android中的卡顿丢帧原因概述-方法论
Android中的卡顿丢帧原因概述-系统篇
Android中的卡顿丢帧原因概述-应用篇
深入探索Android卡顿优化(上)
深入探索Android卡顿优化(下)