微信公众号:岭南见闻
关注可了解更多的数据处理技巧。问题或建议,请公众号留言;
如果你觉得文章对你有帮助,欢迎赞赏
导入数据,进行聚类
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
import pandas as pd
iris = load_iris()
iris_data = iris['data'] ##提取数据集中的特征
kmeans聚类
iris_target = iris['target'] ## 提取数据集中的标签
iris_names = iris['feature_names'] ### 提取特征名
scale = MinMaxScaler().fit(iris_data)## 训练规则
iris_dataScale = scale.transform(iris_data) ## 应用规则
kmeans = KMeans(n_clusters = 3,
random_state=123).fit(iris_dataScale) ##构建并训练模型
print('构建的K-Means模型为:\n',kmeans)
result = kmeans.predict([[1.5,1.5,1.5,1.5]])
print('花瓣花萼长度宽度全为1.5的鸢尾花预测类别为:', result[0])
print('聚类结果为:', kmeans.labels_)
降维后可视化
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
##使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2,init='random',
random_state=177).fit(iris_data)
df=pd.DataFrame(tsne.embedding_) ##将原始数据转换为DataFrame
df['labels'] = kmeans.labels_ ##将聚类结果存储进df数据表
##提取不同标签的数据
df1 = df[df['labels']==0]
df2 = df[df['labels']==1]
df3 = df[df['labels']==2]
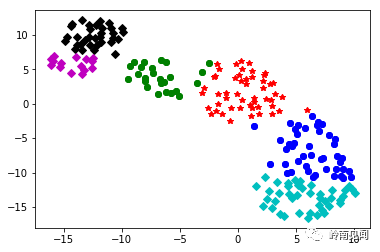
## 绘制图形
fig = plt.figure(figsize=(9,6)) ##设定空白画布,并制定大小
##用不同的颜色表示不同数据
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*',
df3[0],df3[1],'gD')
plt.show() ##显示图片
结果为:
FMI评价分值
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = fowlkes_mallows_score(iris_target,kmeans.labels_)
print('iris数据聚%d类FMI评价分值为:%f' %(i,score))
silhouette_score评分值
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore = []
for i in range(2,15):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = silhouette_score(iris_data,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettteScore,linewidth=1.5, linestyle="-")
plt.show()
calinski_harabaz指数
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = calinski_harabaz_score(iris_data,kmeans.labels_)
print('iris数据聚%d类calinski_harabaz指数为:%f'%(i,score))
#读取数据,进行标准化
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
seeds = pd.read_csv('D:/seeds_dataset.txt',sep = '\t')
print('数据集形状为:', seeds.shape)
## 处理数据
seeds_data = seeds.iloc[:,:7].values
seeds_target = seeds.iloc[:,7].values
sees_names = seeds.columns[:7]
stdScale = StandardScaler().fit(seeds_data)
seeds_dataScale = stdScale.transform(seeds_data)
构建并训练模型
kmeans = KMeans(n_clusters = 3,random_state=42).fit(seeds_data)
print('构建的KM-eans模型为:\n',kmeans)
kmeans.labels_
结果为:
聚类结果为: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 0 2 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0 2 0 0 0 0 2 0 0 0 0
0 0 2 0 0 0 0 0 2 0 2 0 2 0 0 2 2 0 0 0 0 0 2 2 0 0 0 2 0 0 0 2 0 0 0 2 0
0 2]
calinski_harabaz指数
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=12).fit(seeds_data)
score = calinski_harabaz_score(seeds_data,kmeans.labels_)
print('seeds数据聚%d类calinski_harabaz指数为:%f'%(i,score))
进行可视化
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
##使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2,init='random',
random_state=177).fit(seeds_data)
df=pd.DataFrame(tsne.embedding_) ##将原始数据转换为DataFrame
df['labels'] = kmeans.labels_ ##将聚类结果存储进df数据表
df['labels'].value_counts()
df0 = df[df['labels']==0]
df1 = df[df['labels']==1]
df2 = df[df['labels']==2]
df3 = df[df['labels']==3]
df4 = df[df['labels']==4]
df5 = df[df['labels']==5]
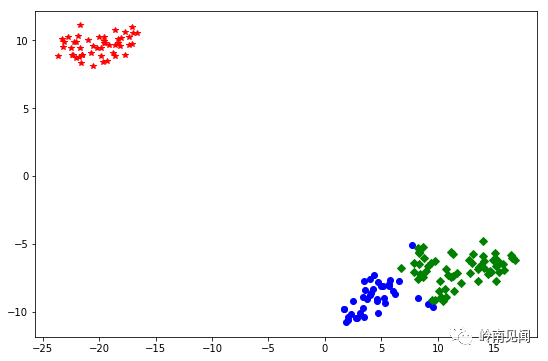
plt.plot(df0[0],df0[1],'go',df1[0],df1[1],'bo',df2[0],df2[1],'r*',
df3[0],df3[1],'kD', df4[0],df4[1],'cD', df5[0],df5[1],'mD')
plt.plot(df0[0],df0[1],'go',df1[0],df1[1],'bo',df2[0],df2[1],'r*')#,
#df3[0],df3[1],'kD', df4[0],df4[1],'cD', df5[0],df5[1],'mD')
结果为: