 志学Python订阅号
志学Python订阅号
爬虫(九十四)PyQuery的使用方法
2020-04-02
志学Python
志学Python

春季,四季之一。春,代表着温暖、生长。春季,阴阳之气开始转变,万物随阳气上升而萌牙生长,大地呈现春和景明之象。

pyQuery简介
如果你是一个前端开发人员,我相信你会熟悉jQuery.js的时代,那可是大大简化了直接操作DOM方式,十分方便,从官网我们可以知道pyQuery,就是类似于jQuery,或者说是jQuery的python版本的实现,所以说有了这个jQuery的基础,我感觉都可以抛弃BeautifulSoup了,BeautifulSoup语法太难搞了,所以以后就用pyQuery进行爬虫爬取页面吧
快速入门
其实你可以使用pyQueryclasspq去加载一个HTML,XML文档结构,也可以通过加载网站链接,或者一个文件等

from pyquery import PyQuery as pqfrom lxml import etreeimport urllibd = pq("")d = pq(etree.fromstring(""))d = pq(url=your_url)d = pq(url=your_url,opener=lambda url, **kw: urlopen(url).read())d = pq(filename=path_to_html_file)初始化一段HTML
html = ''' - python3
- 牛逼
- python3 牛逼
- python3 大法好
- 人生苦短,我用python
'''
打印DOM文档
from pyquery import PyQuery as jqdoc = jq(html)print(doc)
初始化URL
doc = jq(url='http://www.baidu.com')#程序会自动请求urlprint(doc('body'))#返回body标签
初始化文件
我们新建一个test.html文件,里面输入如下代码
Document 我们再新建一个文件test.py文件,代码如下
from pyquery import PyQuery as jqdoc = jq(filename="test.html")print(doc)接下来运行test.py

CSS基础选择器
id选择器
html = ''' - python3
- 牛逼
- python3 牛逼
- python3 大法好
- 人生苦短,我用python
'''from pyquery import PyQuery as pqjq = pq(html)print(jq('#item-wrap'))
class类名选择器
from pyquery import PyQuery as pqjq = pq(html)print(jq('.container'))
标签选择器
from pyquery import PyQuery as pqjq = pq(html)print(jq('div'))
父子选择器
from pyquery import PyQuery as pqjq = pq(html)print(jq('.container ul li'))
还有其他很多各种各样的选择,属性选择器,伪类选择器,等等,可以学习前端的HTML,CSS,JavaScript,以及jQuery,这个非常相似的,就不过多的讲述了
查找元素
查找所有li标签子元素
html = ''' - python3
- 牛逼
- python3 牛逼
- python3 大法好
- 人生苦短,我用python
'''from pyquery import PyQuery as pqjq = pq(html)print(jq('#item-wrap li'))
查找li.active子元素
from pyquery import PyQuery as pqjq = pq(html)print(jq('#item-wrap li.active'))
查找li.activea子元素
from pyquery import PyQuery as pqjq = pq(html)doc = jq('#item-wrap li.active')a = doc.find('a')print(a)![]()
也可以直接使用children()方法查找子元素
from pyquery import PyQuery as pqjq = pq(html)doc = jq('#item-wrap li.active')a = doc.children()print(a)查找父级元素parent()
from pyquery import PyQuery as pqjq = pq(html)doc = jq('#item-wrap')parent = doc.parent()print(parent)
查找#item-wrap.item-first.active的兄弟元素
from pyquery import PyQuery as pqjq = pq(html)doc = jq('#item-wrap .item-first.active')siblings = doc.siblings()print(siblings)
遍历文档对象
from pyquery import PyQuery as pqjq = pq(html)lis = jq('li').items()#.items会是一个生成器print(type(lis))for li in lis: print(li)
获取属性
获取a标签的href属性
from pyquery import PyQuery as pqjq = pq(html)a = jq('.item-first.active a')print(a)print(a.attr('href'))#定义a标签的href属性用于指定超链接目标的URL。如果用户选择了a标签中的内容,那么浏览器会尝试检索并显示href属性指定的URL所表示的文档,或者执行JavaScript表达式、方法和函数的列表。print(a.attr.href)
获取文本
获取a标签的文本
from pyquery import PyQuery as pqjq = pq(html)a = jq('.item-first.active a')print(a)print(a.text())
获取html
from pyquery import PyQuery as pqjq = pq(html)li = jq('.item-first.active')print(li)print(li.html())
pyQueryDOM操作
删除,增加active类型
from pyquery import PyQuery as pqjq = pq(html)li = jq('.item-zore.active')print(li)li.removeClass('active')#删除 active 类名print(li)li.addClass('active')#增加 active 类名print(li)
attr、css 属性,样式设置
from pyquery import PyQuery as pqjq = pq(html)li = jq('.item-zore.active')print(li)li.attr('name', 'link')#增加一个属性print(li)li.css('font-size', '14px')#增加一个cssprint(li)
移除DOM元素
from pyquery import PyQuery as pqjq = pq(html)wrap = jq('.container')print(wrap.text())wrap.find('#item-wrap').remove()#找到p标签然后删除print(wrap.text())print(wrap)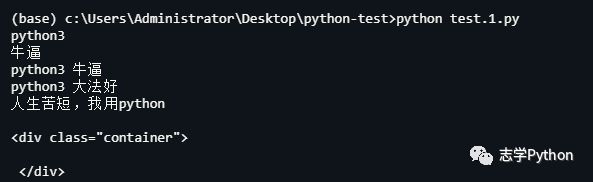
其他DOM方法
http://pyquery.readthedocs.io...
伪类选择器
from pyquery import PyQuery as pqjq = pq(html)li = jq('li:first-child')print(li)li = jq('li:last-child')print(li)li = jq('li:nth-child(2)')print(li)li = jq('li:gt(2)')print(li)li = jq('li:nth-child(2n)')print(li)li = jq('li:contains(second)')print(li)
更多CSS选择器可以查看
http://www.w3school.com.cn/cs...
官方文档
http://pyquery.readthedocs.io/
