前言:之前介绍过一个语义分割中的注意力机制模块-scSE模块,效果很不错。今天讲的也是语义分割中使用到注意力机制的网络BiSeNet,这个网络有两个模块,分别是FFM模块和ARM模块。其实现也很简单,不过作者对注意力机制模块理解比较深入,提出的FFM模块进行的特征融合方式也很新颖。
1. 简介
语义分割需要丰富的空间信息和相关大的感受野,目前很多语义分割方法为了达到实时推理的速度选择牺牲空间分辨率,这可能会导致比较差的模型表现。
BiSeNet(Bilateral Segmentation Network)中提出了空间路径和上下文路径:
- 空间路径用于保留语义信息生成较高分辨率的feature map(减少下采样的次数)
- 上下文路径使用了快速下采样的策略,用于获取充足的感受野。
- 提出了一个FFM模块,结合了注意力机制进行特征融合。
本文主要关注的是速度和精度的权衡,对于分辨率为2048×1024的输入,BiSeNet能够在NVIDIA Titan XP显卡上达到105FPS的速度,做到了实时语义分割。
2. 分析
提升语义分割速度主要有三种方法,如下图所示:

- 通过resize的方式限定输入大小,降低计算复杂度。缺点是空间细节有损失,尤其是边界部分。
- 通过减少网络通道的个数来加快处理速度。缺点是会弱化空间信息。
- 放弃最后阶段的下采样(如ENet)。缺点是模型感受野不足以覆盖大物体,判别能力差。
语义分割中,U型结构也被广泛使用,如下图所示:
这种U型网络通过融合backbone不同层次的特征,在U型结构中逐渐增加空间分辨率,保留更多的细节特征。不过有两个缺点:
- 高分辨率特征图计算量非常大,影响计算速度。
- 由于resize或者减少网络通道而丢失的空间信息无法通过引入浅层而轻易复原。
3. 细节
下图是BiSeNet的架构图,从图中可看到主要包括两个部分:空间路径和上下文路径。
代码实现来自:https://github.com/ooooverflow/BiSeNet,其CP部分没有使用Xception39而使用的ResNet18。
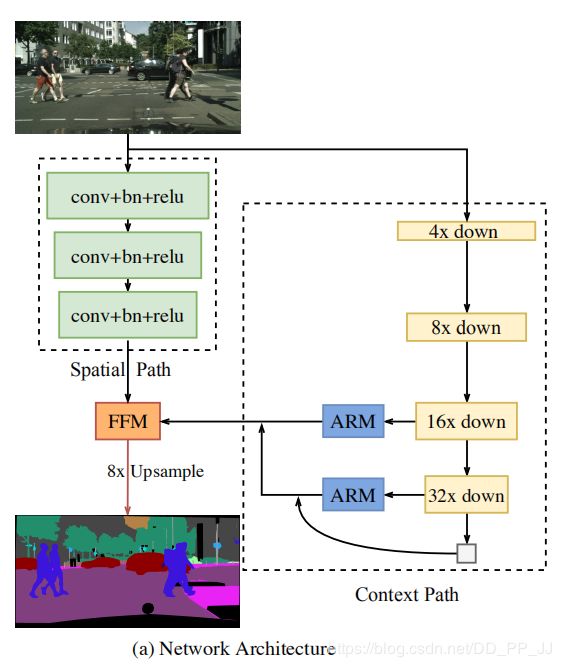
空间路径SP
减少下采样次数,只使用三个卷积层(stride=2)获得1/8的特征图,由于它利用了较大尺度的特征图,所以可以编码比较丰富的空间信息。
class ConvBlock(torch.nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=2,
padding=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, input):
x = self.conv1(input)
return self.relu(self.bn(x))
class Spatial_path(torch.nn.Module):
def __init__(self):
super().__init__()
self.convblock1 = ConvBlock(in_channels=3, out_channels=64)
self.convblock2 = ConvBlock(in_channels=64, out_channels=128)
self.convblock3 = ConvBlock(in_channels=128, out_channels=256)
def forward(self, input):
x = self.convblock1(input)
x = self.convblock2(x)
x = self.convblock3(x)
return x
上下文路径CP
为了增大感受野,论文提出上下文路径,在Xception尾部添加全局平均池化层,从而提供更大的感受野。可以看出CP中进行了32倍的下采样。(示例中CP部分使用的是ResNet18,不是论文中的xception39)
class resnet18(torch.nn.Module):
def __init__(self, pretrained=True):
super().__init__()
self.features = models.resnet18(pretrained=pretrained)
self.conv1 = self.features.conv1
self.bn1 = self.features.bn1
self.relu = self.features.relu
self.maxpool1 = self.features.maxpool
self.layer1 = self.features.layer1
self.layer2 = self.features.layer2
self.layer3 = self.features.layer3
self.layer4 = self.features.layer4
def forward(self, input):
x = self.conv1(input)
x = self.relu(self.bn1(x))
x = self.maxpool1(x)
feature1 = self.layer1(x) # 1 / 4
feature2 = self.layer2(feature1) # 1 / 8
feature3 = self.layer3(feature2) # 1 / 16
feature4 = self.layer4(feature3) # 1 / 32
# global average pooling to build tail
tail = torch.mean(feature4, 3, keepdim=True)
tail = torch.mean(tail, 2, keepdim=True)
return feature3, feature4, tail
组件融合
为了SP和CP更好的融合,提出了特征融合模块FFM还有注意力优化模块ARM。
ARM:

ARM使用在上下文路径中,用于优化每一阶段的特征,使用全局平均池化指导特征学习,计算成本可以忽略。其具体实现方式与SE模块很类似,属于通道注意力机制。
class AttentionRefinementModule(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.bn = nn.BatchNorm2d(out_channels)
self.sigmoid = nn.Sigmoid()
self.in_channels = in_channels
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def forward(self, input):
# global average pooling
x = self.avgpool(input)
assert self.in_channels == x.size(
1), 'in_channels and out_channels should all be {}'.format(
x.size(1))
x = self.conv(x)
# x = self.sigmoid(self.bn(x))
x = self.sigmoid(x)
# channels of input and x should be same
x = torch.mul(input, x)
return x
FFM:

特征融合模块用于融合CP和SP提供的输出特征,由于两路特征并不相同,所以不能对这两部分特征进行简单的加权。SP提供的特征是低层次的(8×down),CP提供的特征是高层语义的(32×down)。
将两个部分特征图通过concate方式叠加,然后使用类似SE模块的方式计算加权特征,起到特征选择和结合的作用。(这种特征融合方式值得学习)
class FeatureFusionModule(torch.nn.Module):
def __init__(self, num_classes, in_channels):
super().__init__()
self.in_channels = in_channels
self.convblock = ConvBlock(in_channels=self.in_channels,
out_channels=num_classes,
stride=1)
self.conv1 = nn.Conv2d(num_classes, num_classes, kernel_size=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(num_classes, num_classes, kernel_size=1)
self.sigmoid = nn.Sigmoid()
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def forward(self, input_1, input_2):
x = torch.cat((input_1, input_2), dim=1)
assert self.in_channels == x.size(
1), 'in_channels of ConvBlock should be {}'.format(x.size(1))
feature = self.convblock(x)
x = self.avgpool(feature)
x = self.relu(self.conv1(x))
x = self.sigmoid(self.conv2(x))
x = torch.mul(feature, x)
x = torch.add(x, feature)
return x
BiSeNet网络整个模型:
class BiSeNet(torch.nn.Module):
def __init__(self, num_classes, context_path):
super().__init__()
self.spatial_path = Spatial_path()
self.context_path = build_contextpath(name=context_path)
if context_path == 'resnet101':
self.attention_refinement_module1 = AttentionRefinementModule(
1024, 1024)
self.attention_refinement_module2 = AttentionRefinementModule(
2048, 2048)
self.supervision1 = nn.Conv2d(in_channels=1024,
out_channels=num_classes,
kernel_size=1)
self.supervision2 = nn.Conv2d(in_channels=2048,
out_channels=num_classes,
kernel_size=1)
self.feature_fusion_module = FeatureFusionModule(num_classes, 3328)
elif context_path == 'resnet18':
self.attention_refinement_module1 = AttentionRefinementModule(
256, 256)
self.attention_refinement_module2 = AttentionRefinementModule(
512, 512)
self.supervision1 = nn.Conv2d(in_channels=256,
out_channels=num_classes,
kernel_size=1)
self.supervision2 = nn.Conv2d(in_channels=512,
out_channels=num_classes,
kernel_size=1)
self.feature_fusion_module = FeatureFusionModule(num_classes, 1024)
else:
print('Error: unspport context_path network \n')
self.conv = nn.Conv2d(in_channels=num_classes,
out_channels=num_classes,
kernel_size=1)
def forward(self, input):
sx = self.spatial_path(input)
cx1, cx2, tail = self.context_path(input)
cx1 = self.attention_refinement_module1(cx1)
cx2 = self.attention_refinement_module2(cx2)
cx2 = torch.mul(cx2, tail)
cx1 = torch.nn.functional.interpolate(cx1,
size=sx.size()[-2:],
mode='bilinear')
cx2 = torch.nn.functional.interpolate(cx2,
size=sx.size()[-2:],
mode='bilinear')
cx = torch.cat((cx1, cx2), dim=1)
if self.training == True:
cx1_sup = self.supervision1(cx1)
cx2_sup = self.supervision2(cx2)
cx1_sup = torch.nn.functional.interpolate(cx1_sup,
size=input.size()[-2:],
mode='bilinear')
cx2_sup = torch.nn.functional.interpolate(cx2_sup,
size=input.size()[-2:],
mode='bilinear')
result = self.feature_fusion_module(sx, cx)
result = torch.nn.functional.interpolate(result,
scale_factor=8,
mode='bilinear')
result = self.conv(result)
if self.training == True:
return result, cx1_sup, cx2_sup
return result
4. 实验
使用了Xception39处理实时语义分割任务,在CityScapes, CamVid和COCO stuff三个数据集上进行评估。
消融实验:
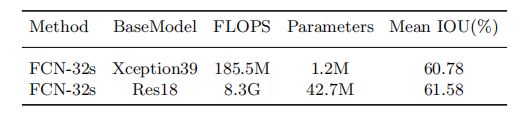
测试了basemodel xception39,参数量要比ResNet18小得多,同时MIOU只略低于与ResNet18。

以上是BiSeNet各个模块的消融实验,可以看出,每个模块都是有效的。

统一使用了640×360分辨率的图片进行对比参数量和FLOPS状态。

上表对BiSeNet网络和其他网络就MIOU和FPS上进行比较,可以看出该方法相比于其他方法在速度和精度方面有很大的优越性。
在使用ResNet101等比较深的网络作为backbone的情况下,效果也是超过了其他常见的网络,这证明了这个模型的有效性。

5. 结论
BiSeNet 旨在同时提升实时语义分割的速度与精度,它包含两路网络:Spatial Path 和 Context Path。Spatial Path 被设计用来保留原图像的空间信息,Context Path 利用轻量级模型和全局平均池化快速获取大感受野。由此,在 105 fps 的速度下,该方法在 Cityscapes 测试集上取得了 68.4% mIoU 的结果。