FP-growth算法概述
在上一章介绍了“关联分析”这种无监督学习的原理。其中提到了利用Apriori算法来发现频繁项集。本章节介绍的FP-growth算法也是一种发现频繁项集的方法,该算法只需要对源数据集进行两次遍历,因此会比Apriori算法快两个数量级以上。
优点:运行速度快于Apriori算法。
缺点:原理比较复杂,理解比较困难。
使用数据类型:标称型数据。
入门案例

通过一个简化版的数据集,我们来深入浅出的理解FP-growth算法。
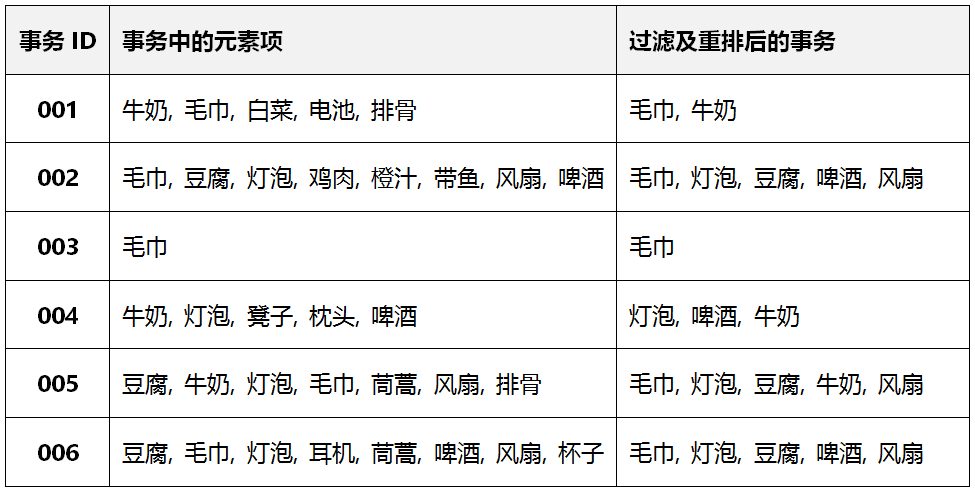
FP-growth算法第1遍对数据集扫描,是找出满足最小支持度的元素,本例中“支持度>=3”,所以“鸡肉、橙汁、带鱼、......”等元素因不满足支持度要求而被过滤了。为了更好的构建FP树,还对过滤后的结果进行了排序,如“毛巾”出现了5次,最多,所以“毛巾”在每一行都排在了第一。
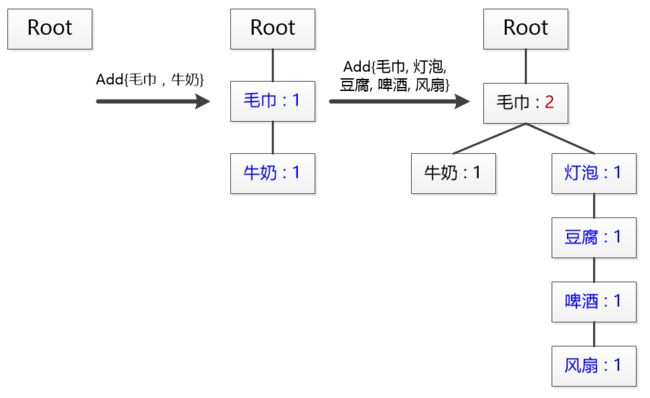
FP-growth算法的第2遍扫描,是构建FP树。以上图为例,用“事务001 毛巾, 牛奶”构建了两个节点,用“事务002 毛巾,灯泡,豆腐,啤酒,风扇”构建了另外的新节点,但注意“毛巾”节点只是把计数值从1更新为2。
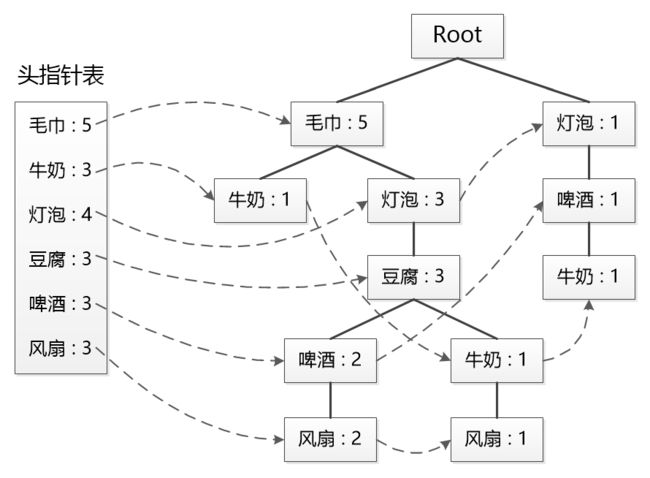
依次用所有的事务数据构建FP树,最终我们得到了如上图所示的FP树。左侧的“头指针表”也很有用,记录了所有单节点的总体计数值,并且还可以用来指向给定元素的第一个节点。
当FP树构建完成后,就可以抽取频繁项集了。由于涉及到比较复杂的数据结构,所以FP-growth算法的原理比较难懂,但好在原书中提供了通用的代码,因此我们可以更加关注如何使用该函数库完成我们自己的任务。但是请注意:FP-growth算法的目的只是找出频繁项集,它并不具备关联分析的能力,如果要做关联分析,还需要回顾上一节的内容。
工作原理
FP-growth算法是一种用于发现数据集中频繁模式的有效方法。由于只对数据集扫描2次,因此FP-growth算法执行更快。
在FP-growth算法中,数据集存储在一个成为FP树的结构中,首先产生候选集,然后扫描数据集来检查它们是否频繁。当FP树构建完成后,可以通过查找元素项的条件基及构建条件FP树来发现频繁项集(此段原理及代码都较复杂,请参考原书)。
一般流程
收集数据:使用任意方法。
准备数据:由于存储的是集合,所以需要离散数据。如果要处理连续数据,需要将它们量化为离散值。
分析数据:使用任意方法。
训练算法:构建一个FP树,并对树进行挖掘。
测试算法:不适用,因为是非监督学习。
使用算法:可用于识别经常出现的元素项,从而用于指定决策、推荐或进行预测。
可使用场景
1.搜索引擎的自动补全功能;
2.从社交媒体公布的数据源中发现高频词汇;
3.从大量的用户浏览行为数据中挖掘备受关注的内容;
......
同类笔记可点击这里查阅