一、概述
- 网络协议三要素:语义、语法、顺序。
- DHCP运行机制:Client使用0.0.0.0 向 255.255.255.255发送UDP请求(原先是BOOTP请求,UDP是更高级的封装),当DHCP服务器捕获到请求之后回复ACK表示成功接收请求。
- PXE协议解析过程:服务器启动的时候BIOS或者UEFI加载烧写在网卡ROM中的PXE程序,然后去DHCP服务器请求一个IP地址和一个pxelinux.0文件以及PXE服务器IP地址。然后PXE客户端使用TFTP协议下载pxelinux.cfg文件,该文件指示了Linux内核和initramfs的位置,接下来便会加载initramfs,当Linux内核启动后就可以根据ks文件实现自动化部署操作系统。
- 广播风暴:ARP广播的时候会将一个端口收到的数据包转发到其他所有端口,当交换机互联出现环路以后,就会形成广播风暴,导致循环发送数据包,硬件资源耗尽。
- Hub只有一个广播域和冲突域,Switch有一个广播域和多个冲突域,每一个端口在划分VLAN的情况下都是一个冲突域。
二、STP生成树
Switch支持STP生成树协议,并给予CAM表进行数据包转发,因此可以构建出物理有环,逻辑无环的逻辑拓扑避免广播风暴。
- 工作原理
- 根交换机是STP生成树中最顶层的交换机。
- 指定交换机将根交换机作为顶层交换机,并且其他交换机如果通过该交换机后,其他交换机的顶层交换机也是该指定交换机的顶层交换机。
- 网桥协议数据单元BPDU是由根交换机发出去的数据包,指定交换机只能都转发该数据包。
- 优先级向量是一组ID数字,[Root Bridge ID, Root Path Cost, Bridge ID, and Port ID],依次比较,值越小优先级越高。
- STP的工作过程应该考虑根交换机相遇,同一层次的交换机相遇,不同层次的交换金相遇的情况。
三、ICMP
-
ICMP报文封装在IP包里边。
- ICMP的报文结构
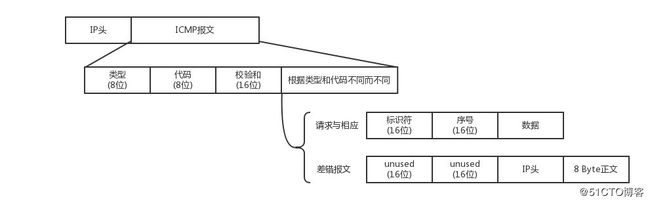
-
ICMP的报文分类
- 查询类型报文:通过ping命令发送,最常用的是主动请求为8,主动回复是0。
- 差错类型报文:通过traceroute命令发送,主机不可达是3,源抑制是4,重定向是5,超时是11。
- traceroute的工作机制:故意设置一个特殊的TTL,工作过程中不断的加1,由于只要通过一个路由器就会损失一个TTL,所以这样可以绘制出路由拓扑;故意设置不分片,从而确定路径的MTU,发送的数据包大小正好等于出口的MTU。
-
Tracerouter发UDP,为啥出错回ICMP?正常情况下,协议栈能正常走到UDP,当然正常返回UDP。但是,主机不可达,是IP层的(还没到UDP)。IP层只知道回ICMP。报文分片错误也是同理。
- 怎么知道UDP有没有到达目的主机呢?Traceroute程序会发送一份UDP数据报给目的主机,但它会选择一个不可能的值作为UDP端口号(大于30000)。当该数据报到达时,将使目的主机的 UDP模块产生一份“端口不可达”错误ICMP报文。如果数据报没有到达,则可能是超时。
四、Socket
- Socket可以通过进程或者线程进行维护,那么C10K问题就是讲的一台机器要维护1万个连接,就要创建1万个进程或者线程,那么操作系统是无法承受的。解决这个问题可以使用IO多路复用技术。一个线程维护多个Socket,使用事件通知的方式,epoll函数在内核中通过callback函数注册的方式实现通知,而不是轮询的方式。
- epoll被称为解决C10K问题的利器。epoll和IOCP是有本质区别的,IOCP是封装了IO操作,而epoll只是一个事件通知机制,这意味着IOCP的IO操作也可以由内核完成,因此IOCP是异步IO,而基于epoll的仍然是同步IO,于IOCP相对应的不是epoll而是AIO。
- select由文件描述fd_set限制,epoll 由文件描述符数量限制,文件描述符可以存在很多,但是fd_set不会太大。
- 由于Socket是文件描述符,因而某个线程盯的所有的Socket,都放在一个文件描述符集合fd_set中,这就是项目进度墙,然后调用select函数来监听文件描述符集合是否有变化。一旦有变化,就会依次查看每个文件描述符。那些发生变化的文件描述符在fd_set对应的位都设为1,表示Socket可读或者可写,从而可以进行读写操作,然后再调用select,接着盯着下一轮的变化。
- epoll的两种触发模式是什么?epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger)。
- LT 模式:当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
- ET 模式:与 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
- select、poll、epoll的应用场景是什么?
- select 应用场景:select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。select 可移植性更好,几乎被所有主流平台所支持。
- poll 应用场景:poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
- epoll 应用场景:只能运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
- Unix 的五种IO模型 是什么?
- 阻塞式IO
- 非阻塞式IO
- 信号驱动式IO
- IO多路复用
- 异步AIO
五、路由算法
(1)距离向量算法RIP
它是基于Bellman-Ford算法的。这种算法的基本思路是,每个路由器都保存一个路由表,包含多行,每行对应网络中的一个路由器,每一行包含两部分信息,一个是要到目标路由器,从那条线出去,另一个是到目标路由器的距离。那这个信息如何更新呢?每个路由器都知道自己和邻居之间的距离,每过几秒,每个路由器都将自己所知的到达所有的路由器的距离告知邻居,每个路由器也能从邻居那里得到相似的信息。每个路由器根据新收集的信息,计算和其他路由器的距离,比如自己的一个邻居距离目标路由器的距离是M,而自己距离邻居是x,则自己距离目标路由器是x+M。加入路由器宣告速度快,但是移除路由器要等到每个路由器认为这个路由器挂掉的时候才会认为是真的挂掉,而且每次需要发送完整的路由表。
(2)链路状态算法OSPF
开放式最短路径优先。广泛应用在数据中心中的协议。由于主要用在数据中心内部,用于路由决策,因而称为内部网关协议(Interior Gateway Protocol,简称IGP)。内部网关协议的重点就是找到最短的路径。在一个组织内部,路径最短往往最优。当然有时候OSPF可以发现多个最短的路径,可以在这多个路径中进行负载均衡,这常常被称为等价路由。
(3)路径向量算法的BGP
外网路由协议。每个数据中心为一个自制系统AS,AS有以下分类:
- Stub AS:对外只有一个连接。这类AS不会传输其他AS的包。例如,个人或者小公司的网络。
- Multihomed AS:可能有多个连接连到其他的AS。但是大多拒绝帮其他的AS传输包。例如一些大公司的网络。
-
Transit AS:有多个连接连到其他的AS。并且可以帮助其他的AS传输包。例如主干网。
- BGP分为eBGP和iBGP。自治系统间,边界路由器之间使用eBGP广播路由。边界路由器通过iBGP将学习到的路由信息导入到内部网络。BGP协议的其中一个缺点是收敛过程慢。
- 路由分静态路由和动态路由,静态路由可以配置复杂的策略路由,控制转发策略。
六、流媒体
(1)视频编码的三大流派
- ITU(International Telecommunications Union)的VCEG(Video Coding Experts Group),这个称为国际电联下的VCEG。既然是电信,可想而知,他们最初做视频编码,主要侧重传输。
- ISO(International Standards Organization)的MPEG(Moving Picture Experts Group),这个是ISO旗下的MPEG,本来是做视频存储的。例如,编码后保存在VCD和DVD中。当然后来也慢慢侧重视频传输了。
- ITU-T(国际电信联盟电信标准化部门,ITU Telecommunication Standardization Sector)与MPEG联合制定了H.264/MPEG-4 AVC。
(2)音视频直播
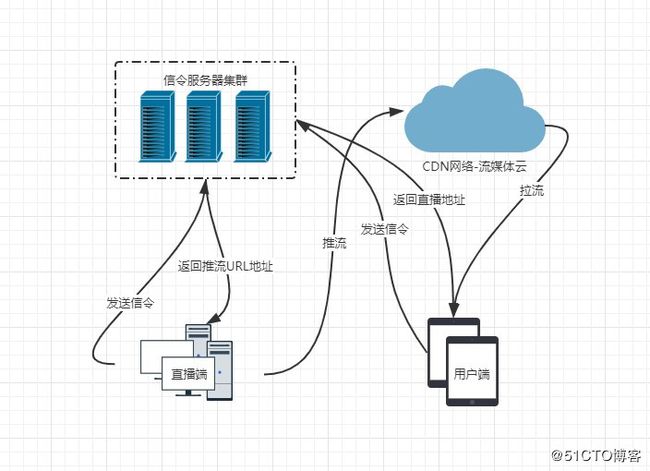
- 泛娱乐化直播:花椒、映客、斗鱼、YY。有信令服务器集群来负责创建房间、聊天、赠送礼物…,当直播端需要直播时直接向信令服务器发送请求,信令服务器向请求端返回推流的地址,然后直播端开始向CDN网络推送数据流(流媒体CDN与传统CDN有些不同),然后当观众需要观看直播时,使用同样的方式请求直播地址,然后在流媒体客户端拉取CDN数据流。
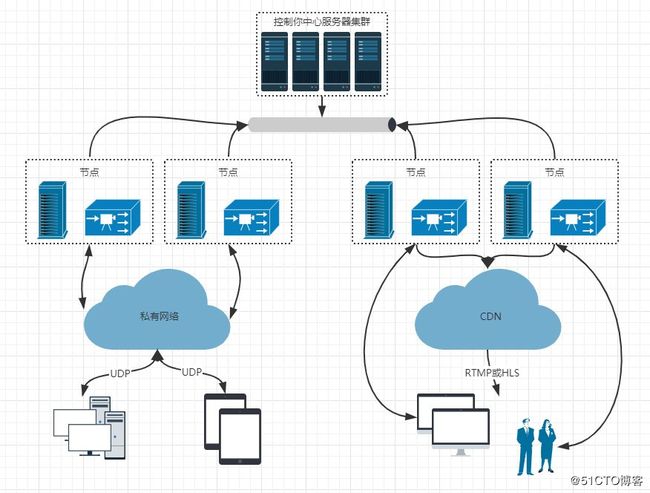
实时互动直播:思科、声网,一般情况下实时互动直播会与PSTN网络相连,所以实时互动直播必须达到电话级别的传输要求,一般不超过400ms。实时互动直播架构对传输效率要求高,因此客户端使用UDP协议向媒体服务器推流,由于要保证服务器7x24小时的服务,所以通过私有网络建立了服务器集群,直播端向媒体服务器推流。由于使用了多个直播服务节点,所以需要控制中心来控制这些节点以达到负载均衡、健康评估等的目的。每个节点通过内总线向控制中心发送心跳包,控制中心通过心跳包来分析服务节点的健康状况来做出相应的决策。使用内总线的原因一是为了数据的安全性,二是为了数据的时效性。那么有时候实时互动也需要多人观看,所以上面讲解的泛娱乐化直播架构与实时互动直播架构进行融合。在CDN流媒体网络与内总线之间有一层服务节点最重要的作用是将直播端的RTP转换为RTMP数据向CDN推流,由此得知内总线的主要作用就是提高数据吞吐量和保证数据实时安全。
-
流媒体CDN网络与传统CDN网络的区别?
- 一般情况下,内容提供商有多个服务器来负载均衡,并且CDN提供区域的CDN边缘节点来提供服务,众多的边缘节点和源节点之间通过主干节点连接,主干节点之间一般通过光纤直接互联。
- 传统CDN网络是客户端请求某一站点的数据,首先请求源站点的数据,如果源站点有数据就直接返回,如果没有就会直接通过主干节点请求源站点直接返回,并且边缘节点缓存该数据以便下一次客户端去请求加速,也就是说传统CDN网络有热点数据这一说。
- 流媒体CDN网络采用的推送+拉取的数据分发策略,也就是内容提供商将数据推送到主干节点,然后边缘节点在主干节点拉取数据,用户请求边缘节点的数据拉取数据流。
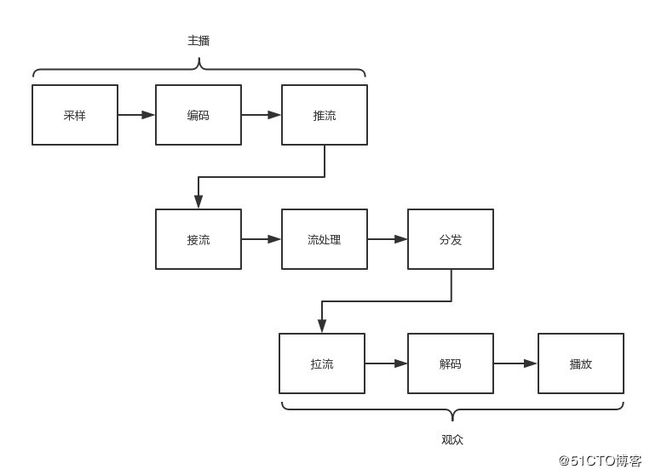
- 直播流程是怎样的?
RTMP为什么需要建立一个单独的连接呢?
-
RTMP是基于TCP的,因而肯定需要双方建立一个TCP的连接。在有TCP的连接的基础上,还需要建立一个RTMP的连接,也即在程序里面,你需要调用RTMP类库的Connect函数,显示创建一个连接。
-
因为它们需要商量一些事情,保证以后的传输能正常进行。主要就是两个事情,一个是版本号,如果客户端、服务器的版本号不一致,则不能工作。另一个就是时间戳,视频播放中,时间是很重要的,后面的数据流互通的时候,经常要带上时间戳的差值,因而一开始双方就要知道对方的时间戳。
- RTMP建立连接的过程:

-
如何将丰富多彩的图片变成二进制流?
- I帧,也称关键帧。里面是完整的图片,只需要本帧数据,就可以完成解码。
- P帧,前向预测编码帧。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面,叠加上和本帧定义的差别,生成最终画面。
- B帧,双向预测内插编码帧。B帧记录的是本帧与前后帧的差别。要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的数据与本帧数据的叠加,取得最终的画面。
- I帧最完整,B帧压缩率最高,而压缩后帧的序列,应该是在IBBP的间隔出现的。这就是通过时序进行编码。在一帧中,分成多个片,每个片中分成多个宏块,每个宏块分成多个子块,这样将一张大的图分解成一个个小块,可以方便进行空间上的编码。还要将这个序列压缩成为二进制流,这个流是有结构的,是一个个的网络提取层单元(NALU,Network Abstraction Layer Unit)。
- IBBP --> 帧 --> 片 --> 宏块 --> 子块 --> 序列压缩 --> 二进制流 --> NALU。
七、P2P和P2SP
(1) 概述
- 种子(.torrent)文件的内容。
- Tracker URL
- 文件信息:INFO区、Name字段(指定顶层目录名字)、每个段的大小(把一个文件分成很多个小段,然后分段下载)和段Hash值(将整个种子中,每个段的SHA-1哈希值拼在一起)。
(2)P2P下载过程
- 解析.torrent文件,获取Tracker地址,连接至Tracker。
- Tracker返回文件服务器的IP地址。
- 客户端连接文件服务器。
- 根据.torrent文件,客户端与文件服务器互相告知已经有的数据块。
- 互相交换数据块就是下载的过程。
- 每下载一个块就计算校验Hash值与.torrent文件中的Hash值对比。
- 不一样则需要重新下载这个块。
(3)去中心化网络(DHT)
-
加入这个网络的每一个节点都需要承担存储任务。
-
Kademlia协议
- Peer角色,监听TCP端口,用来上传下载文件。
- Node角色,监听UDP端口,表明已经加入一个DHT网络。
- 每一个DHT node都有一个ID。
- 每个DHT Node都有责任掌握一些知识,也就是文件索引。
- 当下载一个文件的时候需要先计算文件的ID,在众多DHT Node ID中找到与该ID相等或相近的Node下载。
- 节点ID是一个随机选择的160bits空间,文件的哈希也使用这样的160bits空间。在Kademlia网络中,距离是通过异或计算的。
-
为什么P2P下载会到99%就卡住?
P2P开宗明义说的,把压力转嫁给client,当client流量压力过大而下线了,其他人就无法找到这个文件了,顶多DHT网络告诉每个client,漏失的文件在某个下线的人手上。你们就乖乖等他上线,并且把手上的99.99%分享给其他新来的新Node吧。为了解决这个问题,最早应该是迅雷,提供了P2SP,长效种子,让Server也有义务承担一些压力。
八、数据中心
(1)概述
- 机架(Rack):数据中心里面是服务器。服务器被放在一个个叫作机架(Rack)的架子上面
- 边界路由器(Border Router):数据中心的入口和出口也是路由器,由于在数据中心的边界,就像在一个国家的边境,称为边界路由器(Border Router)
- 自治区域(AS):为了高可用,边界路由器会有多个。既然是路由器,就需要跑路由协议,数据中心往往就是路由协议中的自治区域(AS)。
- 多线BGP:数据中心里面的机器要想访问外面的网站,数据中心里面也是有对外提供服务的机器,都可以通过BGP协议,获取内外互通的路由信息。这就是我们常听到的多线BGP的概念。
- TOR(Top Of Rack)交换机:交换机往往是放在机架顶端的,所以经常称为TOR(Top Of Rack)交换机。
- 接入层交换机:TOR交换机所在的层经常称作接入层。
- 汇聚层交换机:当一个机架放不下的时候,就需要多个机架,还需要有交换机将多个机架连接在一起。这些交换机对性能的要求更高,带宽也更大。这些交换机称为汇聚层交换机。
- 网卡绑定(Bond):数据中心里面的每一个连接都是需要考虑高可用的。这里首先要考虑的是,如果一台机器只有一个网卡,上面连着一个网线,接入到TOR交换机上。如果网卡坏了,或者不小心网线掉了,机器就上不去了。所以,需要至少两个网卡、两个网线插到TOR交换机上,但是两个网卡要工作得像一张网卡一样,这就是常说的网卡绑定(bond)。
- LACP(Link Aggregation Control Protocol):它们互相通信,将多个网卡聚合称为一个网卡,多个网线聚合成一个网线,在网线之间可以进行负载均衡,也可以为了高可用作准备,这就需要服务器和交换机都支持一种协议LACP。
- 主备交换机:交换机高可用最传统的方法,部署两个接入交换机、两个汇聚交换机。服务器和两个接入交换机都连接,接入交换机和两个汇聚都连接,当然这样会形成环,所以需要启用STP协议,去除环,但是这样两个汇聚就只能一主一备了。STP协议里我们学过,只有一条路会起作用。
- 堆叠交换机:交换机有一种技术叫作堆叠,所以另一种方法是,将多个交换机形成一个逻辑的交换机,服务器通过多根线分配连到多个接入层交换机上,而接入层交换机多根线分别连接到多个交换机上,并且通过堆叠的私有协议,形成双活的连接方式。
- Pod、可用区:在这个集群里面,服务器之间通过二层互通,这个区域常称为一个Pod(Point Of Delivery),时候也称为一个可用区(Available Zone)
- 集群:聚层将大量的计算节点相互连接在一起,形成一个集群。
- 核心交换机:当节点数目再多的时候,一个可用区放不下,需要将多个可用区连在一起,连接多个可用区的交换机称为核心交换机。
(2)普通数据中心架构图
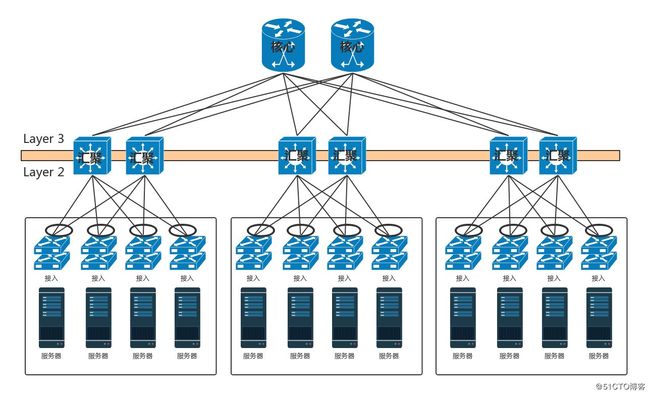
-
全互联模式:核心交换机吞吐量更大,高可用要求更高,肯定需要堆叠,但是往往仅仅堆叠,不足以满足吞吐量,因而还是需要部署多组核心交换机。核心和汇聚交换机之间为了高可用,也是全互连模式的。
-
对于全互联模式出现环路怎么办?不同的可用区都处于不同的二层网络,分配不同的网段,汇聚层交换机和核心层交换机通过三层互联。这样二层都不在一个广播域,三层出现环路通过OSPF路由协议选择最佳路径,通过ECMP等价路由协议进行负载均衡。
-
大二层:随着数据中心里面的机器越来越多,尤其是有了云计算、大数据,集群规模非常大,而且都要求在一个二层网络里面。这就需要二层互连从汇聚层上升为核心层,也即在核心以下,全部是二层互连,全部在一个广播域里面。
-
TRILL多链接透明互联协议:把三层的路由能力模拟在二层实现。运行TRILL协议的交换机称为RBridge,是具有路由转发特性的网桥设备,只不过这个路由是根据MAC地址来的,不是根据IP来的。Rbridage之间通过链路状态协议运作。
-
TRILL多链接透明互联协议:把三层的路由能力模拟在二层实现。运行TRILL协议的交换机称为RBridge,是具有路由转发特性的网桥设备,只不过这个路由是根据MAC地址来的,不是根据IP来的。Rbridage之间通过链路状态协议运作。
- Egress RBridge和Ingress RBridge封装在TRILL Header中:

(3)典型的三层网络结构
对于大二层的广播包,也需要通过分发树的技术来实现。我们知道STP是将一个有环的图,通过去掉边形成一棵树,而分发树是一个有环的图形成多棵树,不同的树有不同的VLAN,有的广播包从VLAN A广播,有的从VLAN B广播,实现负载均衡和高可用。在核心交换上面,往往会挂一些安全设备,例如***检测、DDoS防护等等。这是整个数据中心的屏障,防止来自外来的***。
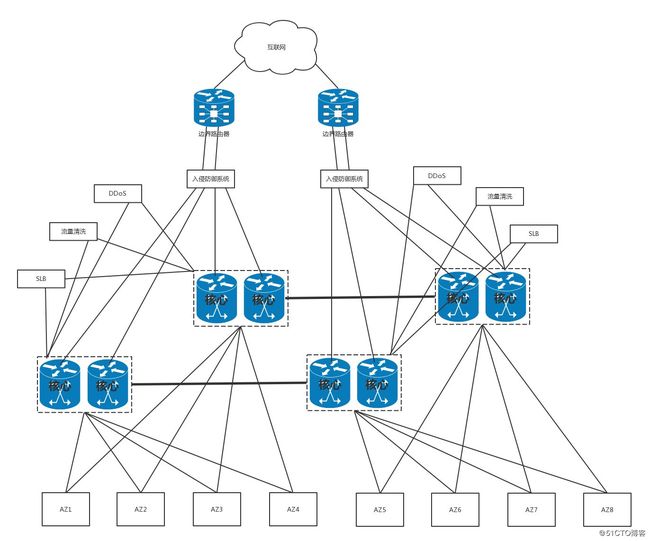
(4)叶脊网络
扁平的结构,应对数据中心的东西流量

- 叶子交换机:直接连接物理服务器。L2/L3网络的分界点在叶子交换机上,叶子交换机之上是三层网络。
- 脊交换机:相当于核心交换机。叶脊之间通过ECMP动态选择多条路径。脊交换机现在只是为叶子交换机提供一个弹性的L3路由网络。南北流量可以不用直接从脊交换机发出,而是通过与leaf交换机并行的交换机,再接到边界路由器出去。
- 运维人员通过***连入机房网络,再通过堡垒机访问服务器或网络设备。当服务器系统不能启动时,远程访问需要用IPKVM(KVM over IP)。扁平的网络结构少了汇聚层,基本没有性能瓶颈。
九、***(IPsec ***协议簇)
(1)概述
- 乘客协议、隧道协议和承载协议。
- 基于IP协议的安全隧道协议。
- AH协议:只能进行数据摘要。
- ESP协议:数据加密和数据摘要都支持。
- IKE组件:用于***的双方要进行对称密钥的交换。
- SA组件:***的双方要对连接进行维护。
- MPLS多协议标签交换:在原始的IP头之外,多了MPLS的标签头,里面可以打标签,这种能够转发标签的路由器称为标签交换路由器(LSR,Label Switching Router)。
- MPLS中的标签生成:
- LDP,标签动态生成协议。
- 标签分发,通过LSR的交互,互相告知去哪里应该打哪个标签,往往是从下游开始的。
(2)通信过程
- 第一阶段:建立IKE自己的SA
- 用来维护一个通过身份认证和安全保护的通道,为第二个阶段提供服务。
- 在这个阶段,通过DH(Diffie-Hellman)算法计算出一个对称密钥K 。
- 第二阶段:建立IPsec SA
- 双方会生成一个随机的对称密钥M。
- 由K加密传给对方,然后使用M进行双方接下来通信的数据。
- 对称密钥M是有过期时间的,会过一段时间,重新生成一次,从而防止被破解。
- 当IPsec建立好,接下来就可以开始打包封装传输了。
- IPsec ***的数据都是会被加上ESP头和IP头。
- 速度往往比较慢,要依赖上层的TCP保证可靠性。
- 与IP相对应的是ATM协议,面向连接,好处是一旦第一次连接就会建立虚拟路径。
(3)MPLS ***路由器分类

- PE(Provider Edge):运营商网络与客户网络相连的边缘网络设备。
- CE(Customer Edge):客户网络与PE相连接的边缘设备。
- P(Provider):这里特指运营商网络中除PE之外的其他运营商网络设备。
- 为什么MPLS-***中将路由器分类?
- 客户地址重复:私有网络地址可能会重复,传统BGP无法正确处理地址空间重叠的***的路由,PE路由器之间使用特殊的MP-BGP来发布***路由,在一般32位IPv4的地址之前加上一个客户标示的区分符用于客户地址的区分,这种称为***-IPv4地址簇。
- 路由表:在PE上,可以通过VRF(*** Routing&Forwarding Instance)建立每个客户一个路由表,与其它***客户路由和普通路由相互区分。可以理解为专属于客户的小路由器。远端PE通过MP-BGP协议把业务路由放到近端PE,近端PE根据不同的客户选择出相关客户的业务路由放到相应的VRF路由表中。
- ***报文转发采用两层标签方式
- 第一层(外层)标签在骨干网内部进行交换,指示从PE到对端PE的一条LSP。***报文利用这层标签,可以沿LSP到达对端PE。
- 第二层(内层)标签在从对端PE到达CE时使用,在PE上,通过查找VRF表项,指示报文应被送到哪个***用户,或者更具体一些,到达哪一个CE。这样,对端PE根据内层标签可以找到转发报文的接口。
- 公有云和私有云如何打通?
- ***
- 专线
(4)裸纤、专线、SDH、MSTP、MSTP+、OTN、PTN、IP-RAN是什么?
PS:感谢51CTO某位大牛博主的解答~
- 裸纤也叫裸光纤,运营商提供一条纯净光纤线路,中间不经过任何交换机或路由器,只经过配线架或配线箱做光纤跳纤,可以理解成运营商仅仅提供一条物理线路。实际项目中,裸光纤应用较多,比如某大学两个校区,相隔大概20KM,租用运营商裸光纤实现两个校区互联。租用运营商裸纤价格较高,一般按照公里收费。国家法律明文规定,只有运营商、军队、市政等几个部门可以在公共区域破土施工,学校/医院/政府这类单位,在自己单位园区内部(也就是围墙内)随便怎么挖,没人会管,但到公共区域施工就不允许了,犯法!交警前端电子警察一般采用裸纤回传,有钱就任性,而平安城市摄像头采用PON链路较多。
- 专线一般分三层专线和二层专线,三层专线一般是指MPLS V.P.N,基本只在金融、电子政务等行业应用。与裸纤的实质区别是: 裸纤中间不经过任何路由器交换机设备,运营商给你的是真实的一根线,而专线中间经过运营商的各类路由器交换机设备,只是运营商给你模拟出来了一根线。如果租用运营商裸纤,只要光纤不被挖断,运营商内部交换机路由器等设备故障,不会影响业务。如果你租用的光纤被挖断了,那就没办法了,业务肯定受影响。如果租用运营商专线,运营商设备出问题,可能影响用户业务,反而光纤被挖断,不一定会影响业务,因为运营商骨干网采用环形设计,传统SDH和新的OTN底层都会有环网,所以论可靠性而言,专线可靠性稍高。当然,使用裸纤也有别的优势,比如带宽自主可控,取决于插入的光模块。
- TDM是时分复用,就是将一个标准时长(1 秒)分成若干段小的时间段(8000),每一个小时间段(1/8000=125us)传输一路信号;SDH系统就是传统的电路调度,电路调度是以TDM为基础。早年的网络都是传输语音的,说白了电话网络的基础是TDM。在SDH大红大紫的时候,另一场战争以太网和ATM大战中,以太网取得全面胜利,从而以太网大行其道,其中又以IP最为强势,导致今天很多业务侧都IP化了。MSTP诞生,运营商骨干部分依旧使用SDH时分复用,但运营商甩给用户的链路接口采用园区网流行的以太网接口。
- 在信息爆炸的时代,带宽的需求急剧增加,所以出现了WDM波分复用。WDM波分技术优势是带宽大,大得惊人。当然也存在一些问题,最突出的是实时流量监测和重点业务保障没有很好的措施。因此诞生了OTN(OpticalTransportNetwork,光传送网)。
- 由于先前MSTP成立时,股权分配不均,有很多遗留问题,以太网仅占20%,导致现在以太网严重不满意,毕竟现在网络上IP流量占了90%以上,为了安抚这个“销量”占公司90%的“销售”,SDH 集团研究后推出MSTP+(也叫Hybrid MSTP),50/50股权分配,进一步提升以太网在公司的地位,也不为一种好的补偿措施。
- 以太网现在声势越来越大,再加上又有MPLS 助阵,逐渐有了可以抗衡SDH的实力,为了对抗SDH阵营,以太网大力发展自己的势力,走农村包围城市的策略,先将末端IP化。同时建立以IP+以太网主导的骨干网。所以IP为了不支持SDH推出了无时间同步的IP-RAN,但是为了吸引SDH用户还推出了PTN。IP-RAN/PTN战胜了SDH,也就是数字通信战胜了传统通信,运营商骨干网完全IP化。
十、移动通信
(1)2G网络
上网走模拟信号,专业名称叫做公共交换电话网PSTN
- MS:手机是通过收发无线信号来通信的,手机的别名,需要嵌入SIM
- BSS基站子系统:
- BTS基站收发台:对外提供无线通信,作为无线接入网
- BSC基站控制器:对内连接有线核心网
- MSC移动业务交换中心:最先处理基站传来的数据,进入核心网的入口,进行合法性认证
- AUC鉴权中心
- EIR设备识别寄存器,负责安全性,负责计费,
- VLR访问位置寄存器,获取接入点位置
- HLR归属位置寄存器,获取号码归属地
- GMSC网关移动交换中心:真正接入互联网
- 2.5G网络:加入分组交换业务,支持数据包转发,从支持IP网络
- PCU分组控制单元:新增,接入核心网,提供分组交换通道
- 连接至前置SGSN和后置GGSN。
(2)3G网络
增加了带宽,换了NodeB
- 将PCU和BSC换成了RNC无线网络控制器
(3)4G网络
换成了eNB,百兆级别,核心网实现数据面和控制面分离
-
数据面:大型流量
-
控制面:指令,都是小型数据包
-
eNodeB直连MME和SGW
-
HSS:用于存储用户签约信息的数据库,其实就是你这个号码归属地是哪里的,以及一些认证信息。
-
MME是核心控制网元:是控制面的核心,当手机通过eNodeB连上的时候,MME会根据HSS的信息,判断你是否合法。如果允许连上来,MME不负责具体的数据的流量,而是MME会选择数据面的SGW和PGW,然后告诉eNodeB允许连接。
-
于是手机直接通过eNodeB连接SGW,连上核心网,SGW相当于数据面的接待员,并通过PGW连到IP网络。PGW就是出口网关。在出口网关,有一个组件PCRF,称为策略和计费控制单元,用来控制上网策略和流量的计费。
-
手机使用4G网络上网的流程:
- 寻找eNodeB,eNodeB将请求发送至MME
- MME请求手机进行鉴权,然后看一下HSS费用情况,在什么地方上网
- MME通知SGW创建Session
- SGW请求PGW创建数据面和控制面隧道
- PGW回复SGW的Session创建成功
- SGW通知MME创建成功,MME再通知eNodeB

- 为什么要分SGW和PGW呢,一个GW不可以吗?SGW是你本地的运营商的设备,而PGW是你所属的运营商的设备。由于你的上网策略是由国内运营商在PCRF中控制的,因而你还是上不了脸谱。只要买一张国外的SIM卡,只要国内允许接入就可以上脸谱了。
(4)5G网络
负责管理无线部分的RAN换成了gNB
-
核心网叫做NG-Core,控制面与数据面彻底的分离,使得用户面可以灵活下沉,并与边缘计算一起分布式部署,更加接近用户侧,从而降低网络延时。
- 5G核心网采用基于服务的架构,其通过云原生,无状态的VNF(虚拟化网络功能)和共享数据层让5G核心网络更加具备弹性。
- AMF(接入和移动性管理功能):负责终端的移动性和接入管理,包括接入、连接、移动性管理、鉴权、位置服务。大致对应MME。
- SMF(会话管理功能):负责会话管理功能,包括IP地址分配、QoS控制、转发路由控制等。大致对应MME和PGW。
- PCF(策略控制功能):负责策略控制,大致对应PCRF。
- UDM(统一数据管理功能):管理用户数据,包括用户标识、用户签约数据、鉴权数据。大致对应HSS。
- AUSF(鉴权服务器功能):配合UDM专门负责鉴权。
- NEF(网络开放功能):类似于4G核心网络中的SCEF,通过API接口将业务能力开放给第三方服务商,与SCEF不同的是,NEF通过SBI总线的方式与NF相连。
- NRF(网络功能库):负责对网络功能服务注册登记、状态监测、实现网络功能服务自动化管理、选择和可扩展,并允许每个网络功能发现其他网络功能的服务。
- NSSF(网络切片选择功能):管理网络切片相关信息,比如负责为终端选择网络切片。
- UPF(用户面功能):负责无线接入网和Internet之间的流量转发、报告流量使用情况、QoS策略实施等,对应4G核心网络中的PGW用户面。

- RRC(无线资源控制):运行于无线接入网的控制面,作为无线资产控制层,RRC负责连接管理、接入控制、状态管理、系统信息广播等功能,但是不负责用户面上处理用户数据。
- PDCP(分组数据汇聚协议):负责压缩和解压缩IP头部信息,加密和完整性保护、在NSA组网模式下,PDCP层负责4G基站和5G基站之间的数据分流和聚合。
- RLC(无线链路控制):负责对数据分段、数据重组、ARQ纠错、重复包检测等。
- MAC(媒体访问控制):负责实时资源调度决策、复用、解复用、缓冲等功能。
- PHY(物理层):负责编码、调制、FEC等。
- 由于MAC层负责实时调度无线资源,因此DU和RU需要就近部署,针对校园、工厂、商城,一个DU可以部署多个RU。

十一、防火墙iptables
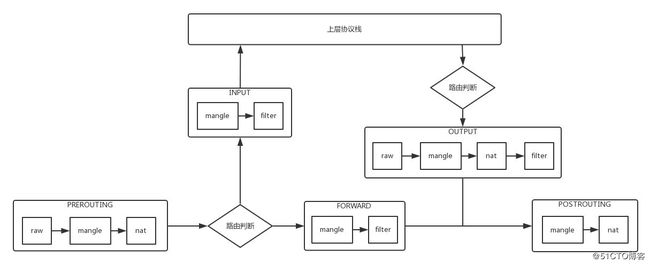
- 表格类型:raw–>mangle–>nat–>filter,优先级依次降低
- filter表处理过滤功能
- INPUT链:过滤所有目标地址是本机的数据包
- FORWARD链:过滤所有路过本机的数据包
- OUTPUT链:过滤所有由本机产生的数据包
- nat表主要是处理网络地址转换,可以进行Snat(改变数据包的源地址)、Dnat(改变数据包的目标地址)
- PREROUTING链:可以在数据包到达防火墙时改变目标地址
- OUTPUT链:可以改变本地产生的数据包的目标地址
- POSTROUTING链:在数据包离开防火墙时改变数据包的源地址
- mangle表主要是修改数据包
- PREROUTING链
- INPUT链
- FORWARD链
- OUTPUT链
- POSTROUTING链
- 在云平台上,一般允许一个或者多个虚拟机属于某个安全组,而属于不同安全组的虚拟机之间的访问以及外网访问虚拟机,都需要通过安全组进行过滤。
- 控制网络的QoS有哪些方式?在Linux下,可以通过TC控制网络的QoS,主要就是通过队列的方式。
- 无类别排队规则
- pfifo_fast:分为三个先入先出的队列,称为三个Band。其中Band 0优先级最高,发送完毕后才轮到Band 1发送,最后才是Band 2。
- 随机公平队列:会建立很多的FIFO的队列,TCP Session会计算hash值,通过hash值分配到某个队列。在队列的另一端,网络包会通过轮询策略从各个队列中取出发送。这样不会有一个Session占据所有的流量。当然如果两个Session的hash是一样的,会共享一个队列,也有可能互相影响。hash函数会经常改变,从而session不会总是相互影响。
- 令牌桶规则(TBF,Token Bucket Filte):所有的网络包排成队列进行发送,但不是到了队头就能发送,而是需要拿到令牌才能发送。令牌根据设定的速度生成,所以即便队列很长,也是按照一定的速度进行发送的。当没有包在队列中的时候,令牌还是以既定的速度生成,但是不是无限累积的,而是放满了桶为止。设置桶的大小为了避免下面的情况:当长时间没有网络包发送的时候,积累了大量的令牌,突然来了大量的网络包,每个都能得到令牌,造成瞬间流量大增。
- 有类别排队规则
- 分层令牌桶规则(HTB, Hierarchical Token Bucket):HTB往往是一棵树,使用TC可以为某个网卡eth0创建一个HTB的队列规则。
十二、GRE与VXLAN
- GRE隧道网络是一种IP over IP的隧道技术,将IP数据包封装到GRE数据包中,外边加上IP头。Tunnel是一个虚拟的点对点连接。GRE很好的解决了VLAN ID数量不足的问题(VLAN只有12位,共4096个,主要是因为二层数据帧结构的原因,根据IEEE802.1q协议定义vlan在数据帧中是通过VID字段信息来标识,VID是一个12位的二进制字段信息,也就是最多可以标识2的12次方(4096)个vlan)。由于Tunnel是点对点的,所以Tunnel的数量会指数型增长。其次GRE不支持组播。还有就是很多防火墙和三层网络设备不支持解析GRE数据。
- VXLAN只是在二层协议外边封装了一个VXLAN头,VXLAN是24位的。VXLAN作为VLAN的扩展性协议,实现解析VXLAN功能的点称作VTEP(VXLAN Tunnel EndPoint)。VXLAN不是点对点的,支持组播的方式定位机器。当一个VTEP启动的时候需要使用IGMP协议加入一个组播组,每当一个虚拟机启动的时候,VTEP就会知道。OpenvSwitch支持三类隧道:GRE、VXLAN、IPsec_GRE。在使用OpenvSwitch的时候,虚拟交换机就相当于GRE和VXLAN封装的端点。
十三、容器网络Flannel和Calico
一般会使用Flannel作为网络,Calico作为网络策略。或者直接使用canel,其他的组件还有buke-router。无论是哪种插件,无非是使用了虚拟网桥、多路复用(MAC VLAN,为物理网卡配置多个MAC地址实现VLAN)、网卡硬件交换SR-IOV(单根IO虚拟化,虚拟出很多硬件网卡,实现网卡级别的交换)。
-
Calico网络:大概思路是即不走Overlay网络,不引入另外的网络性能损耗,而是将转发全部用三层网络的路由转发来实现。Calico推荐使用物理机作为路由器的模式,这种模式没有虚拟化开销,性能比较高。Calico的主要组件包括路由、iptables的配置组件Felix、路由广播组件BGP Speaker,以及大规模场景下的BGP Route Reflector。为解决跨网段的问题,Calico还有一种IPIP模式,也即通过打隧道的方式,从隧道端点来看,将本来不是邻居的两台机器,变成相邻的机器。所谓IPIP模式就是两个物理机建立连接,对数据进行封装,看起来就像是处于一个网络。
-
Flannel网络:是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单地说,它的功能是让集群中不同节点的主机创建Docker容器都具有全集群唯一的虚拟IP地址。而且Flannel还可以在这些IP地址之间建立一个覆盖网络,通过这个覆盖网络将数据包原封不动的传递到目标容器内。Flannel支持多种后端实现,包括VXLAN、HostGW、UDP。VXLAN有两种形式:原生的VXLAN和直接路由型VXLAN。
使用Flannel需要配置几个参数:Network是flannel使用的CIDR格式的网络,用于POD的网络配置。SubnetLen表示使用多长的子网掩码,默认是24位。SubnetMin和SubnetMax指定最大和最小的范围。
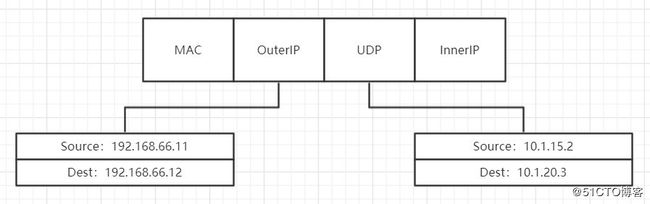
bukectl edit configmap kube-flannel-cfg -n kube-system- Flannel的跨主机通信机制:两个真实的主机,在同一个主机内的Docker容器互相通信通过Docker0网桥即可。但是跨主机通信通过Docker0网桥就无能为力了。当Docker容器启动的时候,Docker0网桥会为其分配一个IP地址,当在宿主机上安装Flanneld的时候会创建Flannel0网桥,Flannel0会监听Docker0的全部数据。当宿主机中的一个Docker向另一个宿主机的Docker容器发起网络请求的时候,数据包会被Flanneld截取,Flanneld将数据包进行封装,发送至另一台主机,另一台主机的Flanneld程序解封装数据包,通过Flannel0网桥和Docker0网桥分发数据到指定的容器。

- Flanneld封装的数据包
-
Canel网络:
- Ingress用于控制入站容器网络的策略,Egress用于控制出站容器网络的策略。
- 定义YAML的时候指定kind类型为NetworkPolicy,然后通过spec.PodSelector和spec.PolicyTypes来指定POD和策略。
- 策略一般是拒绝所有的出站和入站,然后放行所有的出站目标本名称空间内的所有POD。
十四、SDN与OVS
- 特点:
- 控制与转发分离
- 控制平面与转发平面之间的开放接口
- 逻辑上的集中控制
- OpenFlow和OpenvSwitch的关系:OpenFlow是SDN控制器和网络设备之间互通的南向接口协议,OpenvSwitch用于创建软件的虚拟交换机。OpenvSwitch是支持OpenFlow协议的,当然也有一些硬件交换机也支持OpenFlow协议。它们都可以被统一的SDN控制器管理,从而实现物理机和虚拟机的网络连通。
- SDN控制器是如何通过OpenFlow协议控制网络的呢?在OpenvSwitch里面,有一个流表规则,任何通过这个交换机的包,都会经过这些规则进行处理,从而接收、转发、放弃。流表就是一个个表格,每个表格好多行,每行都是一条规则。每条规则都有优先级,先看高优先级的规则,再看低优先级的规则。

十五、RIP与OSPF探究
(1)RIP
RIP协议是一种分布式的基于距离向量的路由选择协议,它的最大优点就是简单。RIP协议要求网络中的每一个路由器都必须维护一个它自己到其他目的网络的距离记录,也可以说是距离向量,什么是RIP协议中的距离?
RIP协议规定从路由器可以直接到达的网络的距离为1,从路由器到其他网络,没经过一个路由器,距离就加1,这跟TTL很相似,RIP协议还规定一条路径最多只能经过15个路由器,即距离为16的网络相当于不可到达,从这里可以看出,RIP协议只能在小型互联网中使用。
RIP不能在两个网络之间使用多个路由,即到某个网络只能存在一条路径,而且这条路径经过的路由器,最少,RIP协议是根据距离,来判断到某一个网络的距离,所以即使存在一条高速,但是“距离”长的路径,RIP协议也不会选择它。这也是RIP协议存在的缺点。
RIP协议的特点:
- 只和相邻的路由器交换信息,不相邻的路由器不交换信息。
- 路由器交换的信息指的是当前路由器所知道的全部的信息,即路由表,RIP协议的路由表项是:到某个网络的最短路径,以及下一跳地址,
- 路由器按固定的时间交换信息,如每隔30秒交换一次信息
那么一个路由器是如何知道整个网络的路由信息的呢?RIP协议刚开始工作时,和相邻的路由器交换信息,整个网络中的路由器都是如此,在经过许多次的信息交换之后,路由信息被逐渐传递出去,最终,任何一个路由器都会知道到某一个网络的最短路径,和下一跳地址。RIP协议最重要的就是它的距离向量算法。
对于某一个路由器来说,从它相邻的路由器X发过来的RIP报文(内容是:到某个网络N的最短路径,以及下一跳地址,),首先要做如下处理:
距离向量算法:对于某一个路由器来说,从它相邻的路由器X发过来的RIP报文(内容是:到某个网络N的最短路径,以及下一跳地址),首先要做如下处理:
- 修改报文中的所有项目,将路由表项中的下一跳地址都改为X,然后将距离加一
- 对于修改过的报文,进行如下步步骤:
- 若路由器的路由表中,不存在到N的路由,则将修改过的表项加入到自己的路由表中
- 若路由器的路由表中,存在到N的路由,再进行如下步骤:
- 若路由表中的下一跳地址就是X,那么将修改过的表项替换原来的路由(以最新的消息为准)。
- 若路由表中的下一跳地址不是X,则将自己的路由的距离,与修改过的表项中的距离相比,若修改过的表项中的距离比自己的小,那么替换路由,否则什么也不做。
- 若三分钟还没有收到相邻路由器发过来的RIP报文,则将此相邻路由标记为不可到达,即把距离设置为16.
- 完成
RIP报文使用UDP进行传输,即将整个报文封装成UDP数据报的数据部分,端口为520。RIP协议的缺点是坏消息传递的很慢,但是实现简单,开销较小。
(2)OSPF
开放最短路径优先协议,是由Internet工程任务组开发的路由选择协议,公用协议,任何厂家的设备。工作原理如下:
- 每台路由器通过使用Hello报文与它的邻居之间建立邻接关系
- 每台路由器向每个邻居发送链路状态通告(LSA),有时叫链路状态报文(LSP). 每个邻居在收到LSP之后要依次向它的邻居转发这些LSP(泛洪)
- 每台路由器要在数据库中保存一份它所收到的LSA的备份,所有路由器的数据库应该相同
- 依照拓扑数据库每台路由器使用Dijkstra算法(SPF算法)计算出到每个网络的最短路径,并将结果输出到路由选择表中
OSPF的简化原理:发Hello报文——建立邻接关系——形成链路状态数据库——SPF算法——形成路由表。
OSPF的特征:
- 快速适应网络变化
- 在网络发生变化时,发送触发更新
- 以较低的频率(每30分钟)发送定期更新,这被称为链路状态刷新
- 支持不连续子网和CIDR
- 支持手动路由汇总
- 收敛时间短
- 采用Cost作为度量值
- 使用区域概念,这可有效的减少协议对路由器的CPU和内存的占用
- 有路由验证功能,支持等价负载均衡
运行OSPF的路由器需要一个能够唯一标示自己的Router ID。
OSPF的网络类型:
- 广播型网络, 比如以太网,Token Ring和FDDI,这样的网络上会选举一个DR和BDR,DR/BDR的发送的OSPF包的目标地址为224.0.0.5,运载这些OSPF包的帧的目标MAC地址为0100.5E00.0005;而除了DR/BDR以外的OSPF包的目标地址为224.0.0.6,这个地址叫AllDRouters
- NBMA网络, 比如X.25,Frame Relay,和ATM,不具备广播的能力,在这样的网络上要选举DR和BDR,因此邻居要人工来指定
- 点到多点网络, 是NBMA网络的一个特殊配置,可以看成是点到点链路的集合. 在这样的网络上不选举DR和BDR
- 点到点网络, 比如T1线路,是连接单独的一对路由器的网络,点到点网络上的有效邻居总是可以形成邻接关系的,在这种网络上,OSPF包的目标地址使用的是224.0.0.5,这个组播地址称为AllSPFRouters
- 虚链接,它被认为是没有编号的点到点网络的一种特殊配置.OSPF报文以单播方式发送
OSPF的DR(指定路由)与BDR(备份路由):
-
通过组播发送Hello报文
-
具有最高OSPF优先级的路由器会被选为DR(255最高)
- 如果OSPF优先级相同具有最高路由器ID,路由器会被选为DR
DR与BDR的选举过程:
- 在和邻居建立双向通信之后,检查邻居的Hello包中Priority、DR和BDR字段,列出所有可以参与DR/BDR选举的邻居。所有的路由器声明它们自己就是DR/BDR(Hello包中DR字段的值就是它们自己的接口地址;BDR字段的值就是它们自己的接口地址)
- 从这个有参与选举DR/BDR权的列表中,创建一组没有声明自己就是DR的路由器的子集(声明自己是DR的路由器将不会被选举为BDR)
- 如果在这个子集里,不管有没有宣称自己就是BDR,只要在Hello包中BDR字段就等于自己接口的地址,优先级最高的就被选举为BDR;如果优先级都一样,RID最高的选举为BDR
- 如果在Hello包中DR字段就等于自己接口的地址,优先级最高的就被选举为DR;如果优先级都一样,RID最高的选举为DR;如果没有路由器宣称自己就是DR,那么新选举的BDR就成为DR
-
当网络中已经选举了DR/BDR后,又出现了1台新的优先级更高的路由器,DR/BDR是不会重新选举的
- DR/BDR选举完成后,其他Rother只和DR/BDR形成邻接关系.所有的路由器将组播Hello包到224.0.0.5,以便它们能跟踪其他邻居的信息.其他Rother只组播update packet到224.0.0.6,只有DR/BDR监听这个地址 .一旦出问题,反过来,DR将使用224.0.0.5泛洪更新到其他路由器
OSPF路由器在完全邻接之前,所经过的几个状态:
- Down: 初始化状态
- Attempt: 只适于NBMA网络,在NBMA网络中邻居是手动指定的,在该状态下,路由器将使用HelloInterval取代PollInterval来发送Hello包
- Init: 表明在DeadInterval里收到了Hello包,但是2-Way通信仍然没有建立起来
- two-way: 双向会话建立
- ExStart: 信息交换初始状态,在这个状态下,本地路由器和邻居将建立Master/Slave关系,并确定DD Sequence Number,接口等级高的成为Master
- Exchange: 信息交换状态,本地路由器向邻居发送数据库描述包,并且会发送LSR用于 请求新的LSA
- Loading: 信息加载状态,本地路由器向邻居发送LSR用于请求新的LSA
- Full: 完全邻接状态,这种邻接出现在Router LSA和Network LSA中
在OSPF协议的环境下,区域(Area)是一组逻辑上的OSPF路由器和链路,区域是通过一个32位的区域ID(Area ID)来识别的。
OSPF的区域:
在一个区域内的路由器将不需要了解它们所在区域外部的拓扑细节。在这种环境下,路由器仅仅需要和它所在区域的其他路由器具有相同的链路状态数据库,链路状态数据库的减小也就意味着处理较少的LSA通告,大量的LSA泛洪被限制在一个区域里面。
对于和区域相关的通信量定义了下面3种通信量的类型:
-
域内通信量(Intra-Area Traffic)
-
域间通信量(Inter-Area Traffic)
- 外部通信量(External Traffic)
OSPF的路由器类型:
-
内部路由器(Internal Router)
-
区域边界路由器(Area Border Routers,ABR)
-
骨干路由器(Back bone Router)
- 自主系统边界路由器(Autonomous System Boundary Router,ASBR)
分段区域(Partitioned Area)是指一个区域由于链路的失效而使这个区域的一个部分和其他部分隔离开来的情形。
虚链路(Virtual Link)是指一条通过一个非骨干区域连接到骨干区域的链路。
在配置虚链路的时候,有几条相关的规则,虚链路必须配置在两台ABR路由器之间,配置了虚链路所经过的区域必须拥有全部的路由选择信息,这样的区域又被称为传送区域(Transit Area) 传送区域不能是一个末梢区域。配置一个基本的OSPF的过程含有以下3个必要的步骤:
- 确定和每一个路由器接口相连的区域
- 使用router ospf process-id命令来启动一个OSPF进程
- 使用network area命令来指定运行OSPF协议的接口和它们所在的区域