-
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
- 简介
- scikit-learn 估计器
- 加载数据集
- 进行fit训练
- 设置参数
- 预处理
- 流水线
- 结尾
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html
项目地址:GitHub
在上一篇博客中,我们使用了简单的OneR算法对Iris进行分类,在这篇博客中,我将介绍数据挖掘通用框架的搭建以及使用(以scikit-learn框架为例子),并以K近邻算法为例展示过程。
简介
在介绍框架之前,有几个重要的概念如下所示:
- 估计器(Estimator):用于分类,聚类和回归分析。
- 转换器(Transformer):用于数据的预处理和数据转换。
- 流水线(Pipeline):组合数据挖掘流程,便于再次使用。
至于这几个具体是怎么回事,下面将以具体的例子来进行展示。
scikit-learn 估计器
估计器,根据上面概念的解释,我们也知道估计器的作用是什么了,它主要是为了训练模型,用于分类任务。主要有两个主要的函数:
- fit():训练算法,里面接受训练集和类别两个参数。
- predict():里面的参数为测试集,预测测试集的类别,返回预测后的类别数组。
大多数的scikit-learn估计器接收和输出的数据格式均为numpy数组或者类似的格式。
下面将介绍使用scikit-learn实现KNN算法,关于KNN算法的一些介绍,可以去参考一下我上一篇的博客。
加载数据集
其中,在这里使用的数据集是叫做电离层(Ionosphere)。简单点来说,通过采集的数据来判断是否存在自由电子,存在则为"g",不存在则为'b'。下图是一些数据的展示。

我们目标就是建立分类器,自动判断数据的好坏。
数据集在这里:GitHub,该数据是CSV格式的。每一行数据有35个值,前34个为采集数据,最后一个表示该数据是否能够判断自由电子的存在。
接下来展示数据的导入。
import numpy as np
# 采集数据
x = np.zeros((351,34),dtype = "float")
# 类别数据
y = np.zeros((351),dtype = "byte")
# 数据文件名
file_name = "ionosphere.data"
with open(file_name,"r") as input_file:
reader = csv.reader(input_file)
for i,row in enumerate(reader):
# 只遍历前34个数据
datas = [float(data) for data in row[:-1]]
x[i] = datas
y[i] = row[-1] == 'g'此时我们就分别得到了采集的数据和类别数据。接下来就是创建训练集和测试集。这一步在前面的博客有详细说明,就不再解释了。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state = 14)
进行fit训练
在前面我们说过,我们使用KNN算法实现数据的分类,但是需要我们实现KNN的函数吗?尽管KNN的实现并不是很难,但是scikit-learn帮我们实现了。
通过下面的代码,我们导入了一个K近邻的分类器,其中里面默认$K = 5$,我们可以自己进行调整K的取值。
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier()前面我们说过estimator有两个重要的函数fit和predict,这里就让我们来进行训练吧!
estimator.fit(x_train,y_train)在上面我们通过fit函数导入训练集和训练类别就完成了KNN算法的训练,然后我们就可以进行预测了。其中使用predict函数,使用测试数据集作为参数,返回预测的类别。
y_predict = estimator.predict(x_test)
accuracy = np.mean(y_predict == y_test) * 100
print("精准度{0:.2f}%".format(accuracy))最后的结果如下图:
上面的结果与train_test_split的随机数和测试集的大小有关。
抛开测试集的大小不谈,通过改变随机数,我们发现,精准度会随着随机数的改变而发生较大的变化。下图是随机种子为2的时候的精准度。
这个时候就会有一个疑问,如果我的运气不好,随机分割的训练集没有给好,即使再好的分类算法岂不是会得到一个不好的分类结果?对,脸黑的话的确会有这种情况。

那怎么解决呢?如果我们多进行几次切分,并在在切分训练集和测试集的时候每一次都与上一次不一样就好了,并且每一条数据都被用来测试一次就更好了。算法描述如下。
- 将整个大数据集分为几个部分。
- 循环执行以下操作:
- 将其中一部分作为当前测试集
- 用剩余部分训练算法
- 在当前测试集上测试算法
- 记录每次得分,然后得到平均分。
- 每条数据只在训练集出现一次。
以上的说法叫做交叉验证。emm,梦想是好的,现实中更是好的,scikit-learn提供了一些交叉验证的方法。我们导入即可:
# 进行交叉验证
from sklearn.model_selection import cross_val_scorecross_val_score默认使用Stratified K Fold方法切分数据集,它大体上保
证切分后得到的子数据集中类别分布相同,以避免某些子数据集出现类别分布失衡的情况。这个默认做法很不错,现阶段就不再把它搞复杂了。
cross_val_score里面传入估计器,数据集,类别集以及scoring。
这里简单的说一下scoring的作用。简单来说他是一个计分器,来决定计分的规则。而传入accuracy代表预测的结果要完全的匹配测试集中的类别。官方的解释如下图。

scores = cross_val_score(estimator, x, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("平均的精准度为{0:.2f}%".format(average_accuracy)) 最终的结果如下图:
设置参数
前面我们说过,默认的KNN估计器中$K = 5$,那么他是不是最好的呢?不一定!!K过小时,分类结果容易收到干扰,过大时,又会减弱近邻的影响。因此我们希望设置一个合理的K,这个时候,我们可以使用一个for循环,遍历K的取值,来选择一个比较好的取值。
# 保存每一次的平均分数
avg_scores = []
# 遍历k的取值从1到25
for i in range(1,25):
estimator = KNeighborsClassifier(i)
scores = cross_val_score(estimator, x, y, scoring='accuracy') * 100
avg_scores.append(np.mean(scores))为了更加的形象化,选择使用matplotlib 进行画图。
from matplotlib import pyplot as plt
x_len = list(range(1,len(avg_scores)+1))
plt.plot(x_len,avg_scores, '-x',color = "r") 最后的结果如下图所示:
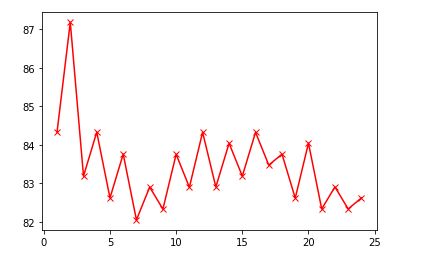
总的来说,随着$K$值的增加,准确度逐渐降低。
预处理
数据挖掘的路不可能一帆风顺,很可能我们就被第一波数据集的浪潮给拍死在岸边上。因为我们的数据集很可能中间的某一些数据有问题,或者说有可能特征的取值千差万别,也有可能某些特征没有区分度等等原因。这个时候我们就需要对数据集进行预处理。
选择具有区分度,创建新的特征,对数据进行清洗……这些都属于预处理的范畴。在scikit-learn中,预处理工具叫做转换器(Transformer),它接受原始数据集,返回转换后的数据集。转换器主要有以下三个函数:
- fit():训练算法,设置内部参数。
- transform():数据转换。
- fit_transform():合并fit和transform两个方法。
任然以上面的Ionosphere为例子,让我们来对数据集进行一些破坏,然后进行训练。
x_broken = np.array(x)
# 对numpy数组进行切片,对于每一列,每隔2个单位除以10
x_broken[:,::2] /= 10
estimator = KNeighborsClassifier()
scores = cross_val_score(estimator, x_broken, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("平均的精准度{0:.2f}%".format(average_accuracy)) 预处理有很多种方式,其中有一个方式称之为归一化,也就是说将特征值规范到01之间,最小值为0,最大值为1,其余值介于01之间。
接下来让我们对x_broken进行归一化预处理。在scikit-learn中提供了一系列的预处理器,通过调用预处理器的转换函数,可以完成数据集的转换。
-
sklearn.preprocessing.MinMaxScaler:使数据归一化
-
sklearn.preprocessing.Normalizer:使每条数据各特征值的和为1
-
sklearn.preprocessing.StandardScaler:使各特征的均值为0,方差为1
-
sklearn.preprocessing.Binarizer:使数值型特征的二值化,大于阈值的为1,反之为0
# 归一化
from sklearn.preprocessing import MinMaxScaler
x_formed = MinMaxScaler().fit_transform(x_broken)
# 然后进行训练
estimator = KNeighborsClassifier()
scores = cross_val_score(estimator, x_formed, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("平均的精准度{0:.2f}%".format(average_accuracy)) 归一化之后的精准度如下图:
流水线
在上面我们看到,进行数据挖掘有很多步骤需要去做:
- 预处理数据集
- 对数据集进行切割
- 寻找最好的参数
- ……
而随着数据集的增加以及精准度的要求,实验的操作复杂度越来越大,如果中间某一个步骤出现问题,比如说数据转换错误,拉下一个步骤……
流水线结构可以解决这个问题。让我们来导入它吧:
from sklearn.pipeline import Pipeline我们可以将Pipeline比喻成生产车间的流水线,原材料按顺序一个一个的通过步骤加工,然后才能够形成一个完整的产品。当然此pipeline非此流水线,但是哲学思想却是差不多的。
首先,让我们来看一看Pipeline对象一部分的介绍信:
Pipeline of transforms with a final estimator.
Sequentially apply a list of transforms and a final estimator.Intermediate steps of the pipeline must be
transforms, that is, they must implement fit and transform methods.The final estimator only needs to implementfit.The transformers in the pipeline can be cached usingmemoryargument.The purpose of the pipeline is to assemble several steps that can be cross-validated together while setting different parameters.For this, it enables setting parameters of the various steps using their names and the parameter name separated by a '__', as in the example below. A step's estimator may be replaced entirely by setting the parameter with its name to another estimator, or a transformer removed by setting it to 'passthrough' or
None.
简单点来说,在这条流水线中,前面的步骤是一系列的transform,最后一个步骤必须是estimator。在transform中必须实现fit和transform函数,而最后的estimator中必须实现fit函数。具体怎么使用,让我们来看一看吧。
from sklearn.pipeline import Pipeline
mining_pipe = Pipeline(
[
('预处理',MinMaxScaler()),
('估计器',KNeighborsClassifier())
],
verbose=True
)在pipeline中,步骤使用的是元组来表示:(“名称”,步骤)。名称只是一个称呼,all is ok!后面的步骤则就是estimator或者transfrom。verbose代表是否查看每一个步骤的使用时间。
运行流水线很简单:
# 传入pipeline参数
scores = cross_val_score(mining_pipe, x_broken, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("平均的精准度{0:.2f}%".format(average_accuracy)) 结果如下图:

时间为0s,这就很尴尬了。估计是数据集太小了,数据还没反应过来就被处理了。结果是82.90%,与上一步的结果一样。
结尾
这篇博客主要是介绍scikit-learn的使用流程和使用方法。
GitHub地址:GitHub
参考书籍:Python数据挖掘入门与实践