耗时8小时左右
总体设计
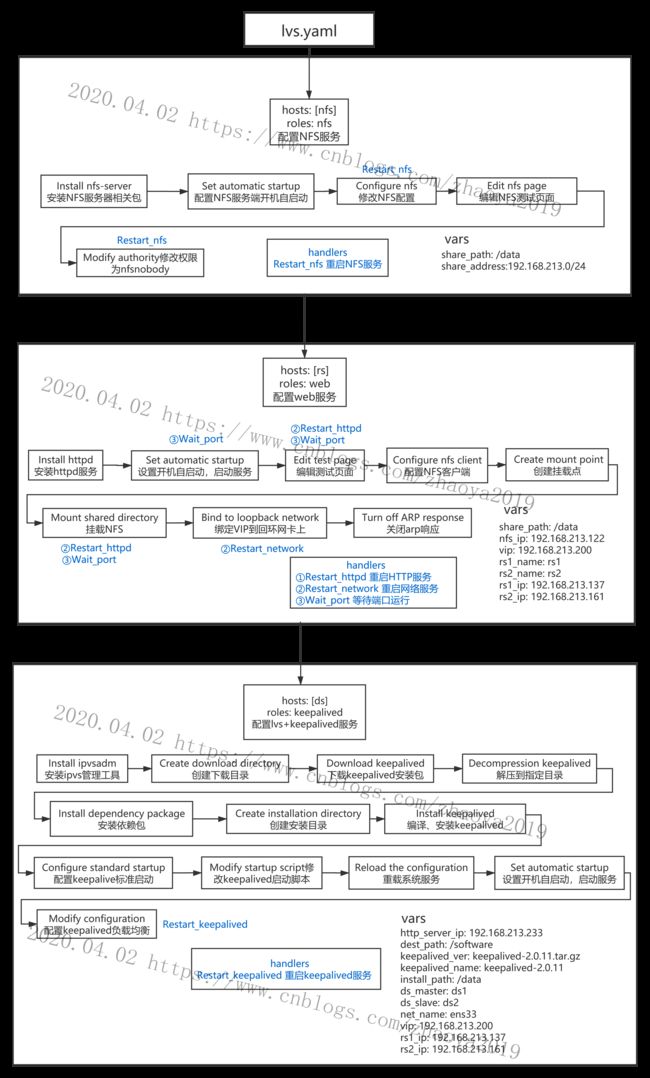
ansible-playbook目录结构
入口文件
因为不同的主机配置不同,所以按主机分类设置了3个role
[root@ansible ~]# cat /etc/ansible/work_dir/lvs.yaml
- hosts: [nfs]
roles:
- nfs
- hosts: [rs]
roles:
- web
- hosts: [ds]
roles:
- keepalived
NFS服务playbook结构
[root@ansible ~]# tree /etc/ansible/roles/nfs
/etc/ansible/roles/nfs
├── files
├── handlers
│ └── main.yaml
├── tasks
│ └── main.yaml
├── templates
└── vars
└── main.yaml
WEB服务playbook结构
[root@ansible ~]# tree /etc/ansible/roles/web
/etc/ansible/roles/web
├── files
├── handlers
│ └── main.yaml
├── tasks
│ └── main.yaml
├── templates
│ ├── ifcfg-lo.j2
│ └── rs_test.j2
└── vars
└── main.yaml
Keepalived+LVS服务playbook结构
[root@ansible ~]# tree /etc/ansible/roles/keepalived
/etc/ansible/roles/keepalived
├── files
├── handlers
├── tasks
│ └── main.yaml
├── templates
│ ├── keepalived_conf.j2
│ └── keepalived_service.j2
└── vars
└── main.yaml
执行过程
[root@ansible work_dir]# pwd
[root@ansible work_dir]# ansible-playbook lvs.yaml
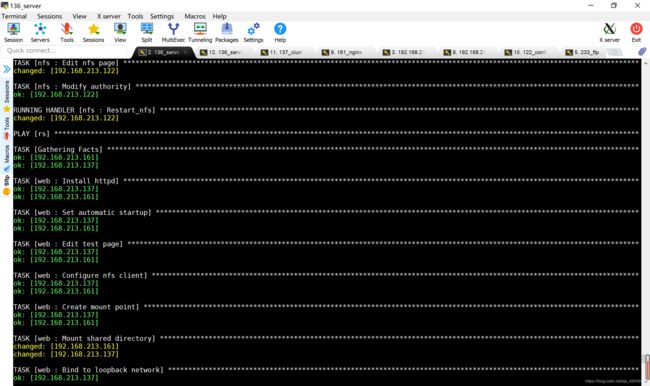

结果测试
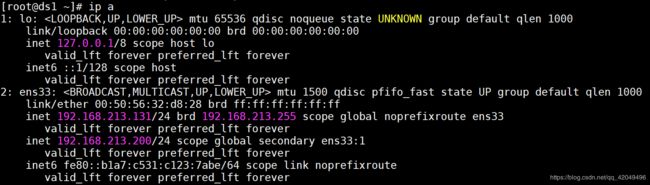
1.查看浮动ip
在ds1 (主) 上查看IP信息
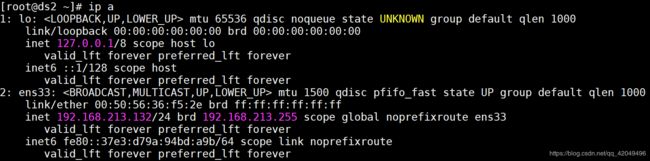
 在ds2(备) 上查看IP信息
在ds2(备) 上查看IP信息
 浮动IP在负载均衡主节点上
浮动IP在负载均衡主节点上
在网页上访问测试
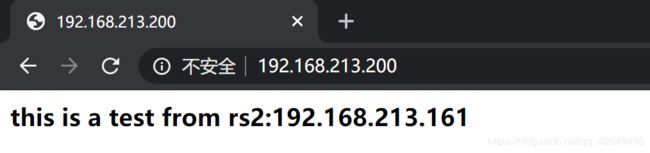
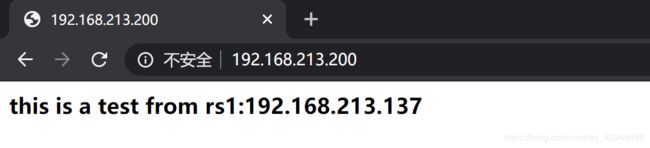 通过LVS访问NFS(把NFS挂载到了/var/www/html/nfs)
通过LVS访问NFS(把NFS挂载到了/var/www/html/nfs)
 实际页面应该只有一个
实际页面应该只有一个 Welcome to NFS! ,这是多次测试ansible-playbook导致的
2.测试故障切换
[root@ftp ~]# while :; do curl 192.168.213.200;sleep 2;done
停止rs1的httpd服务,业务没有中断
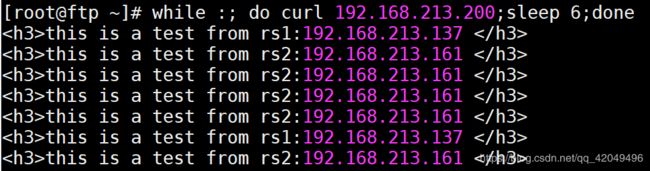 当rsl
当rsl systemctl start httpd 停止httpd服务后,所有的访问请求都分配到rs2上;当rsl启动httpd服务,所有的访问请求都平均分配到两个rs节点上(wrr算法,weight都为1)
在sleep 2的时候会出现2次访问不到的情况
curl: (7) Failed connect to 192.168.213.200:80; Connection refused
在sleep 3/4/5的时候会出现1次访问不到的情况
在sleep 6的时候访问正常
可见,这个节点移除是需要时间的
停止ds1(主)的keepalived服务,服务不受影响,vip漂移到了ds2(备)上
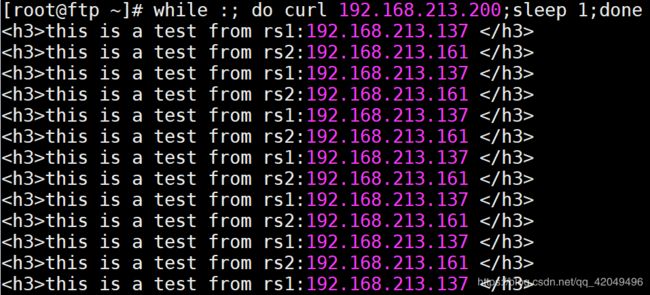 当dsl重启keepalived服务后,vip会漂移回来
当dsl重启keepalived服务后,vip会漂移回来
实现过程问题记录
1.在rs1,rs2上绑定VIP到回环网卡
2.调整内核参数,关闭arp响应要 sysctl -p
3.keepalived首次启动失败
通过日志文件/var/log/messages查看错误
(Line 12) WARNING - interface eth0 for vrrp_instance VI_1 doesn’t exist
问题: keepalived新版本会检查/etc/keepalived/keepalived.conf配置文件,配置有误会导致程序启动失败(如默认的配置文件中网卡为eth0,而实际网卡为ens33)
解决方法: 修改配置文件后再启动进程(用以下方法可以方便的修改网卡名称)
#/etc/ansible/roles/keepalived/templates/keepalived_conf.j2
interface {{ net_name }}
4.systemctl无法彻底停掉keepalived
现象描述: 无法正常stop掉keepalived进程,再次启动时虽然可以启动,但进程状态里面会提示:Can’t open PID file /var/run/keepalived.pid (yet?) after start
问题: systemd的启动脚本有问题,无法创建PID文件
解决方法: 注释掉启动脚本中的如下行,重载 systemctl daemon-reload
#/lib/systemd/system/keepalived.service
KillMode=process #只杀掉程序的主进程,不管打开的子进程
这个问题可能和keepalived的版本有关,不一定都需要处理这个问题
5.keepalived开启顺序影响部分配置
当2台服务器都设置为BACKUP模式时,先开启keepalived进程的会先绑定VIP,后开启的即使优先级高也不会去抢占,除非先开启的挂掉,即双BACKUP模式下,要先开启优先级高的服务器的keepalived进程(个人验证的是这样的)
6.keepalived中的两种模式
(1)master->backup模式
一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。
(2)backup->backup模式
当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
在数据库的应用场景中,不建议数据库的频繁切换,可配置为keepalived的VIP不抢占模式
7.在Linux中,挂载到目录后,文件夹原来的数据会被隐藏,无法看到测试结果(只能看到NFS上的文件),所以新建了目录 /var/www/html/nfs 进行挂载,既能看到测试结果,又能访问到NFS服务器
8.ds1和ds2的keepalived.conf文件除了一些参数不同,其余都一样,可以应用templates处理
vrrp_instance VI_1 {
{% if ds_master == ansible_hostname%}
state MASTER
priority 150
{% elif ds_slave == ansible_hostname%}
state BACKUP
priority 100
{% endif %}
}
vars变量有部分重复定义,但只写一个role中对集群不同主机的配置会有影响,暂时未想到解决办法
执行有些慢,可能是因为开了7台虚拟机的原因,也可能是网络原因
调整
1.调整了keepalived的playbook顺序:将 Modify configuration 最后执行,并添加handler
- name: Modify configuration
template: src=keepalived_conf.j2 dest=/etc/keepalived/keepalived.conf
notify:
- Restart_keepalived
2.静态文件 keepalived.service 放到了files
3.准备优化rs数量,但语法未通过 待更新
{% for i in range(1,{{ rs_num }}+1) %}
real_server {{ rs{{ i }}_ip }} 80 {
weight 1
TCP_CHECK {
connect_timeout 8
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
{% endfor %}
