HTTP的概述
HTTP最初是一个匿名,没有状态的请求/响应协议。服务器来处理来自客户端的请求,然后向客户端回送一条响应。但是现在的web站点提供一些个性化的接触,希望可以对链接的另一端有更加全面的认识,并且能在用户浏览界面的时候,对其进行跟踪,现在的网站是通过这样的方式进行个性化设置:
- a.个性化的问候
- b.有的放矢的推荐
- c.管理信息的存档
- d.记录会话
用户识别的几种机制:
- 承载用户信息的
HTTP首部 - 客户端IP地址跟踪,通过用户的
IP地址对其进行识别 - 用户登录,用认证的方式来识别用户
- 胖
URL,一种在URL嵌入识别信息的技术 -
cookie,一种强大且高效的持久的身份识别技术
HTTP的首部
现在的HTTP中有7种最常见的用来承载用户相关信息的HTTP的请求首部,它们分别是:

From:每一个用户都有不同的E-mail的地址,所以在理想的情况下,可以将这个地址作为源端来识别用户,但是由于担心一些不道德的服务器会进行收集相关信息,进行垃圾邮件的分发,所以浏览器很少会在HTTP首部发送From这个首部信息。
User-Agent:这个首部可以将用户浏览器的信息告知服务器,包括程序的名称和版本,通常还包含操作系统的相关信息,这个首部对于实现定制内容和特定的浏览器及其属性间的良好操作起到了很大的作用,但是对于识别特定的用户并没有提供太多有意义的帮助。
Referer:提供了用户源页面的URL。Referer首部自身并不能完全的标识用户,但是它确实说明了用户之前访问了哪些界面,通过这个首部可以更好地理解用户的浏览行为,以及用户的兴趣所在。
客户端IP地址
在早期web相关研究者尝试将客户端的IP地址作为一种标识形式进行使用,如果每一个用户都有不同的IP地址,IP地址是很少发生改变的。但是通常HTTP的首部都不提供客户端的IP地址,但是web服务器可以找到承载HTTP请求的TCP链接的另一端的IP地址。
但是这样使用客户端IP地址来标识用户有很多的缺点,限制了将其作为用户识别技术的效能。
-
ip地址描述的是所使用的机器,多个用户共享一台计算机的时候,就不能对其进行区分了。 - 很多的因特网服务器在用户登录的时候,对其进行动态的
ip分配,所以用户的每一次登录都有是一个不同的地址。 - 为了提高网络安全,并对稀缺的地址资源进行管理,很多的用户都通过网络转换地址(NAT)防火墙来浏览网络内容,这些NAT设备隐藏了实际客户端的ip地址,将实际的IP地址转换成一个共享的防火墙ip地址。
- HTTP代理和网关通常会打开一些新的、到原始服务器的TCP链接。web服务器将会看到代理服务器的IP地址,而不是客户端的。
用户登录
web服务器不用再被动的根据用户的IP地址来猜测他的身份,它可以要求用户通过密码和用户名进行身份的验证来显示的确认用户是谁。
为了使web站点的登录更加的减半,HTTP中包含了一种内建机制,可以用www-Authenticate首部和Authenticate首部向web站点传送用户的相关信息,如果服务器希望为用户提供站点的访问之前,先进性登录,可以向浏览器回送一跳HTTP响应代码401。

胖URL
有一些网站会为每一个用户生成特定版本的URL来追踪用户的信息。通常会对真正的URL进行扩展,在URL开始或是结束的地方添加一些状态信息。用户浏览站点的时候,web服务器会生成一些超链,继续维护URL中的状态信息。
可以通过胖URL服务器上若干个HTTP事务捆绑成一个‘会话’或‘访问’。用户首次访问这个web站点的时候,会生成一个唯一的ID添加到URL中,然后服务器会将客户端重新导向这个胖URL中,方便维护用户的ID。但是会带来一些严重的问题:
- 丑陋的
URL:浏览器中显示胖URL会给新用户带来困扰。 - 无法共享
URL:如果将这个URL发送给其他人,可能就在无意中将自己的个人信息分享出去了。 - 破坏缓存:为每个
URL生成特有的版本意味着不再有可供公共访问的URL需要缓存了。 - 额外的服务器负载:服务器需要重写
HTML页面使URL变胖。 - 逃逸口:用户跳转到其他的网站或是请求一个特定的
URL时,就很容易无意间‘逃离’胖URL会话,如果用户逃离此链接,就会丢失他的进展信息,必须重新开始。 - 会话间是非持久的:除了用户收藏了特定的
胖URL,否则用户登录时,所有的信息都会丢失。
cookie
cookie是当前识别用户,实现持久会话的最好的方式
cookie的类型
cookie主要分为两类:会话cookie和持久cookie,其中会话cookie是一种临时的cookie,它记录了用户访问网站时候的设置和偏好,但是用户退出浏览器的时候,会话的cookie就会马上被删除。持久的cookie会长久一点,它们存储到硬盘上,浏览器退出的时候,计算机重启时仍然存在,通常会用持久cookie维护某个用户会周期性访问的站点的配置文件或是登录名。这两类的cookie唯一的差别就是它们的过期时间。
cookie如何工作
用户首次访问web站点的时候,web服务器对用户是一无所知的,web服务器希望这个用户会再次回来,所以像个这个用户‘拍上’一个独有的cookie,这样以后他就可以识别这个用户了,cookie中包含了一个由(name = value)这样的信息构成的任意列表,并通过Set-Cookie或是Set-Cookie2的HTTP响应首部,将其贴到用户身上。
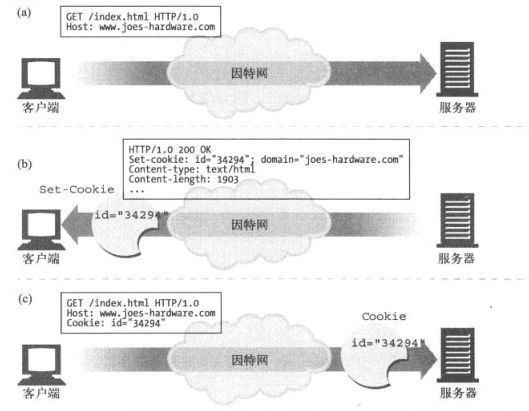
cookie中可以包含任何的信息,但是他们通常只包含一个服务器为了进行跟踪而产生的独特的识别码。很多的web服务器都会之间将信息保存在cookie中。
cookie罐:客户端的状态
cookie的基本思想就是让浏览器积累一组服务器特有的信息,每一次访问服务器的时候都会将这些信息返回给它。因为浏览器要负责存储cookie信息,所以此系统被称为客户端侧状态。这个cookie规范的正式名称为HTTP状态管理机制。
不同站点使用不同的cookie
浏览器内部的cookie罐中可以有成千上万的cookie,但是浏览器是不会将每一个cookie都发送给所有的网站点,实际上,它们通常向每一个站点发送2~3个cookie,原因如下:
- 对所有的
cookie都进行传输会严重的影响传输的性能。浏览器实际进行传输的cookie的字节要比实际的内容字节多。 - cookie中包含服务器特有的名值对,所以对于大部分的站点来说,大部分的
cookie是没有办法被识别的无用数据。 - 将所有的
cookie的信息都进行无差别发送的话,会有一定的安全隐患,对于一些不信任的网站也会收集到信息。
cookie的域属性:产生cookie的服务器可以向set-Cookie响应首部添加一个Domain属性来控制哪些站点可以看到那个cookie
cookie路径属性:cookie规范甚至允许用户将cookie与部分web站点联系起来,可以通过path属性来实现这一功能,在这个属性列出的URL路径前缀下所有的cookie都是有效的。
cookie成分
最初的cookie规范是由网景公司定义的,这些‘版本0’的cookie定义了Set-Cookie的响应首部、cookie请求首部以及控制cookie的字段`。
版本0的Set-Cookie首部
Set-Cookie首部有一个强制性的cookie名和cookie值。后面跟着一些可选的cookie属性,中间用分号进行分割。


版本0的Cookie的首部
客户端发送请求的时候,会将所有与域、路径和安全过滤器相匹配的未过期cookie都会发送给这个站点。所有的cookie都被组合到一个Cookie的首部里面。
cookie版本1(RFC2965)
RFC2965相对于之前的网景公司定义的cookie有了一定的改变,但是现在这个版本还没有得到完全的支持,其中RFC2965cookie对于如下的信息进行修改。
- 为每一个
cookie关联上解释性的文办,对其目的进行解释 - 允许浏览器退出的时候,不考虑过期的时间,将
cookie进行强制销毁 - 用相对秒数,而不是绝对日期来标识
cookie的Max-age - 通过
URL端口号,而不仅仅是域和路径来控制cookie的能力 - 通过
cookie首部回送域、端口和路径过滤器(如果有的话) - 为实现互操作性使用了版本号
- 在
Cookie首部从名字中区分出附加关键字的$前缀
 (RFC2965)的set-Cookie2
(RFC2965)的set-Cookie2

版本1的Cookie首部
版本1的cookie会回带与传送的每一个cookie相关的附加信息,迎来描述每一个cookie途径的过滤器。每个的cookie都必须包含来自相应Set-Cookie2首部的所有Domain、port或Path属性。
举个栗子:假设客户端之前曾经受到下列5个来自web站点www.joes-hardware.com的Set-Cookie2响应。

如果客户端对路径为/tools/cordless/specials.html又发起了一次请求,就会同时发送一个很长的cookie的首部。

cookie与会话跟踪
以电子商务为例,当电子商务web站点用会话cookie在用户浏览时候记录下用户的购物车的信息,我们以主流的购物网站Amazon.com为例子。在浏览器输入网址的时候,重启了一个事务链。在这些事务中Web服务器会通过一系列的重定向、URL重写以及cookie设置附加的标识信息。
- 浏览器首次请求Amazon.com根页面
- 服务器将客户端重定向到一个电子商务软件的
URL上 - 客户端对重定向的
URL发送请求 - 服务器在响应上贴上2个会话
cookie,并将用户重定向到另外一个胖URL上,也就是说有一些状态被嵌入到URL上面去了。如果客户端禁止了cookie,只要用户一直随着网站产生的胖URL,不离开网站的,依然可以实现一些基本的标识功能。 - 客户端请求新的
URL,但是现在会传输2个附加的cookie - 服务器重定向到
home.html上,并附加另外2个cookie - 客户端获取
home.html的,并附加上另外2个cookie - 客户端获取
home.html页面并将4个cookie都传输出去。 -
服务器回送内容
 电商网站的cookie的跟踪用户
电商网站的cookie的跟踪用户
cookie与缓存
缓存那些与cookie事务相关的文档的时候要特别小心。你不会希望给用户分配一个过去用户的cookie,或是更加糟糕的是,向一个用户展示其他人的私人文档内容。
cookie和缓存的过着没有很好的建立起来,下面是处理缓存时的一些指导性的规则。
- 如果无法缓存的文档,要将其标识出来
Cache-Control:no-cache="Set-Cookie"标识不能缓存的文档,或是Cache-Control:public标识出可以缓存的文档。 - 缓存Set-Cookie首部时要小心
如果响应中有Set-Cookie首部,就可以对主体进行换船,但是特别注意对Set-Cookie首部的缓存。如果向多个用户发送了相同的Set-Cookie首部,会破坏用户的定位。
有些缓存在将响应缓存之前就会删除Set-Cookie首部,但是这样也会引起一定的问题,因为在没有缓存的时候,通常都会有cookie贴在客户端上,但是由于缓存提供服务的客户端就不会有cookie了。 - 小心的处理带有Cookie首部的请求
带有cookie的请求到达的时候,就在提醒我们,得到的结果可能使私有的。一定要把私有的内容设置为不可以缓存,但是服务器有的时候可能会犯错,没有将这些内容设为不可缓存。
有一些响应文档对于携带cookie首部的请求,保守的缓存可能会选择不去缓存这些响应文档。现在得到广泛的接受的策略是缓存带有cookie首部的图片,将过期时间设置为0,强制每一次进行再验证。