Redis事务
redis中的事务是一组命令的集合,事务中的命令要么全部执行,要么都不执行,Redis 通过 MULTI 、DISCARD 、EXEC 和 WATCH
四个命令来实现事务功能,multi表示事物的开启,exec表示事物的执行,exec执行后返回事务执行的结果,discard表示放弃事务执行,清空事务队列中已有的所有命令并退出队列,watch用于监视给定的键,如果键被其他客户端修改,将不会执行事务。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key 1
QUEUED
127.0.0.1:6379> get key
QUEUED
127.0.0.1:6379> exec
1) OK
2) "1"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key1 1
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get key1
(nil)这里我在另一个客户端修改了被监视的key,导致在这个客户端事务没有执行
127.0.0.1:6379> set key 1
OK
127.0.0.1:6379> watch key
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr key
QUEUED
127.0.0.1:6379> incr key #客户端2
(integer) 2
127.0.0.1:6379> exec
(nil)
127.0.0.1:6379> get key
"2"由于事务在执行时会独占服务器,所以尽量避免在事务中执行过多命令,以免服务器阻塞
Redis Pipline
redis是一个cs模式的tcp server,使用和http类似的请求响应协议。一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。如果网络延迟较大,那将会花费太多的时间,redis提供了pipline可以解决这个问题,redis可以在pipline中发送多个消息而无需等待每个消息的答复的过程。
这里我使用python的redis库写了个demo来演示使用pipline的效果
from redis import Redis
import time
conn=Redis(host="60.205.177.100",port="6379")
def usepipline():
start_time=time.time()
pipline=conn.pipeline()
for i in range(300):
pipline.incr("key")
pipline.execute()
print("usepipline:",time.time()-start_time)
def withoutpipline():
start_time=time.time()
for i in range(300):
conn.incr("key1")
print("withoutpipline:",time.time()-start_time)
usepipline()
withoutpipline()响应结果
usepipline: 1.2412519454956055
withoutpipline: 7.2261717319488525可以看到使用pipline效果是很明显的
Redis发布订阅模式
Redis通过PUBLISH 、SUBSCRIBE 等命令实现了订阅与发布模式,发布者可以向多个频道发布消息,订阅者可以订阅多个频道,当然一个频道也可以有多个订阅者,发布者和订阅者的这种分离可以允许更大的可伸缩性和更动态的网络拓扑。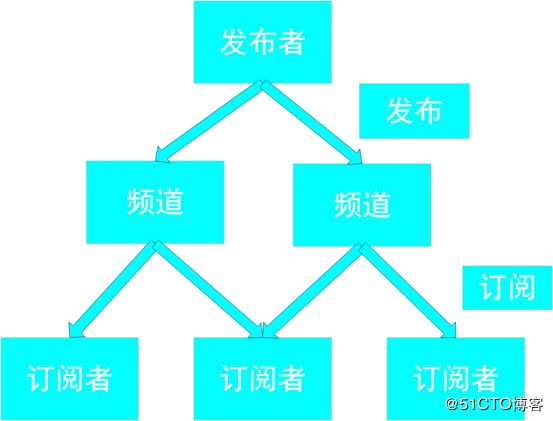
命令
向频道发送消息
publish channel message例如
返回的是接收到消息的订阅者数量
127.0.0.1:6379> publish CCTV1 worldnews
(integer) 0
127.0.0.1:6379> publish CCTV1 chinanews
(integer) 0订阅频道
subscribe channel [channel ...]例如
127.0.0.1:6379> subscribe CCTV1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "CCTV1"
3) (integer) 1
1) "message"
2) "CCTV1"
3) "chinanews"退订频道
UNSUBSCRIBE [channel [channel ...]]例如
127.0.0.1:6379> UNSUBSCRIBE CCTV1 CCTV2
1) "unsubscribe"
2) "CCTV1"
3) (integer) 0
4) "unsubscribe"
5) "CCTV2"
6) (integer) 0订阅模式
redis支持使用glob的方式来一次订阅多个频道
PSUBSCRIBE pattern [pattern ...]例如
127.0.0.1:6379> publish CCTV2 chinanew
(integer) 1
127.0.0.1:6379> publish CCTV1 worldnews
(integer) 1
127.0.0.1:6379> PSUBSCRIBE CCTV*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "CCTV*"
3) (integer) 1
1) "pmessage"
2) "CCTV*"
3) "CCTV2"
4) "chinanews"
1) "pmessage"
2) "CCTV*"
3) "CCTV2"
4) "chinanew"退订模式
PUNSUBSCRIBE [pattern [pattern ...]]例如
127.0.0.1:6379> PUNSUBSCRIBE CCTV*
1) "punsubscribe"
2) "CCTV*"
3) (integer) 0python demo
redis_pub.py
from redis import Redis
import time
conn=Redis(host="60.205.177.100",port="6379")
def publish():
while True:
conn.publish("CCTV3","test")redis_sub.py
from redis import Redis
import time
conn=Redis(host="60.205.177.100",port="6379")
def subscribe():
subscribe=conn.pubsub()
subscribe.subscribe('CCTV3')
message=subscribe.parse_response()
print(message)Redis复制
虽然已经有了aof和rdb做持久化了,但是为了防止单点故障,这就需要复制多个数据副本来保证数据安全
redis复制的基本特征
- Redis使用异步复制,并以每秒一次的频率向主服务器确认复制进度。
- 一个主服务器可以有多个从服务器。从服务器也可以有多个从服务器,从服务器还可以以类似级联的结构连接到其他从服务器。
- Redis复制在主服务器端无阻塞。这意味着当一个或多个副本执行初始同步或部分重新同步时,主服务器将继续处理查询。
- 复制在从服务器基本上也没有阻塞。当副本执行初始同步时,如果配置了replica-serve-stale-data参数为yes,则从服务器可以使用数据集的旧版本处理查询。或者配置replica-serve-stale-data参数为no,在复制连接断开时,向客户端发送一个错误,但是,在初始同步之后,从服务器删除旧版本数据集并载入新版本数据集的那段时间内, 连接请求会被阻塞。
- 复制功能可以单纯地用于数据冗余(data redundancy), 也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability)
- 可以使用复制来避免让主数据库执行持久化,而是复制到从服务器之后由从服务器进行持久化,但是最好还是开启主服务器的持久化,因为重新启动的主服务器将以空数据集开始,如果从服务器尝试与其同步,导致从服务器的数据也将被清空。
- 缺点也很明显,Redis主从模式仍具有单点风险,一旦主服务器挂掉将无法进行写数据操作
redis复制原理
完全同步
主服务器后台发送RDB文件给从服务器。从服务器接收rdb数据期间,主服务器会将新数据保存到复制客户端缓冲区,当从服务器接收完rdb文件后,将其保存在磁盘上,然后将其加载到内存中。加载完rdb文件后,如果开启aof,从服务器会进行重写操作。主服务器会把缓冲区的新数据发送给从服务器
部分同步
当主从连接中断后,从服务器使用psync命令向主服务器发送上次复制的偏移量,以及记录的masterID,如果上次复制的偏移量仍存在主服务器的缓冲区中,并且masterID与主服务器的masterID一致,将会从缓冲区中上次断开的位置开始增量复制,否则将会发生完全同步
psync命令
psync masterID offset当从服务器与主服务器建立连接时,会判断是不是初次复制,如果是的话,将会发送psync ? -1进行完全同步,如果不是的话,会发送psync masterID offset尝试部分同步,如果发送的masterID与主服务器一致且offset存在于主服务器的复制缓冲区中,将进行部分同步,否则将会进行完全同步
首先我们查看主服务器的masterID和offset
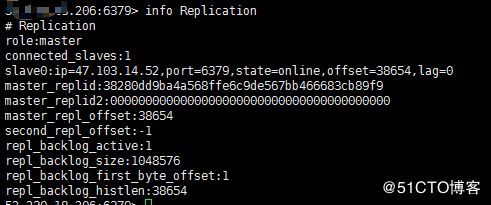
然后将masterID和offset复制到从服务器,期间我在主服务器写了两条数据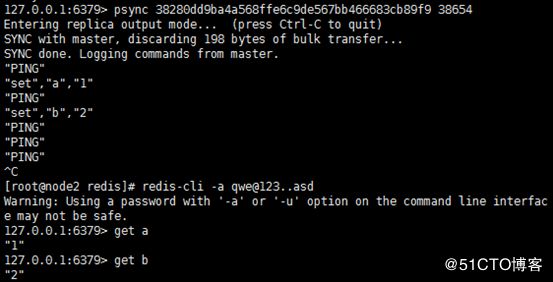
可以看到从服务器已经有了主服务器的数据
redis复制配置
由于主服务器设置了密码,需要在从服务器中指定注定主服务器的密码
vim /etc/redis/6379.conf
masterauth 123456由于我的redis版本是5.0,所以同步的命令较以前的命令不太一样,但也兼容以前的同步命令
第一种方法:
配置文件修改
vim /etc/redis/6379.conf
replicaof masterip port #5.0版本支持的命令
或者
slaveof masterip port第二种方法:
在redis客户端执行命令,在客户端执行的同步命令将在重启后失效
replicaof masterip port #5.0版本支持的命令
或者
slaveof masterip port配置好之后,主从的masterID信息是一样的,这是主服务器的信息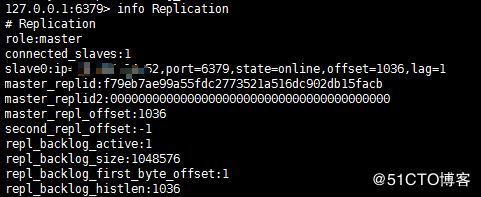
这是从服务器的信息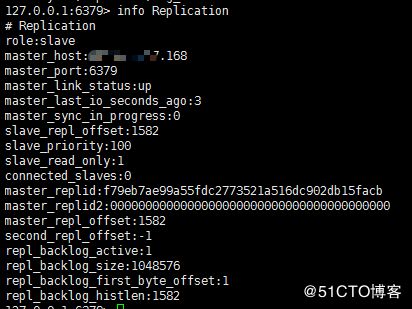
主从同步后,从服务器将不能写入数据
当我们断开当前数据库的连接,与另一台主服务器建立主从同步后,masterid也发生变化,将重新进行完全同步
Redis哨兵
在redis主从模式下,一旦主服务器宕机,需要人工进行干预将某个从服务器转换为主服务器,还需要去监视redis的状态,费事费力,还会造成一段时间内服务不可用,对于某些应用场景,这种处理方法并不可取,redis在2.8版本开始提供了RedisSentinel工具,通过心跳检测的方式监视多个主服务器以及它们属下的所有从服务器,并在某个主服务器下线时自动对其实施故障转移,Sentinel将选择一个从服务器并将其提升为主服务器,其他剩余的从服务器实例将自动重新配置为使用新的主服务器。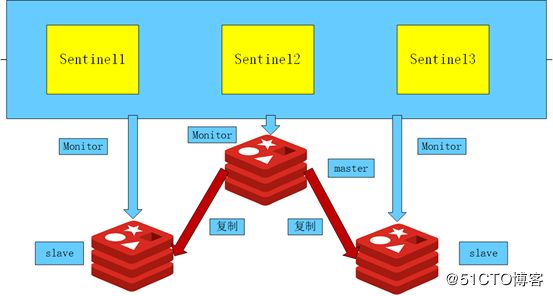
哨兵功能
- 监控。Sentinel会不断检查主从节点是否按预期工作。
- 通知。Sentinel通过API通知客户端出现问题的节点
- 自动故障转移。当主服务器不能正常工作时,Sentinel可以进行故障转移操作,在该操作中将从服务器升级为主服务器,将其他从服务器改为复制新主服务器。
- 配置提供程序。客户端在初始化时,通过连接到Sentinels,获取当前主服务器的节点地址。
哨兵搭建
环境准备
192.168.179.131:6379 master
192.168.179.132:6379 slave
192.168.179.134:6379 slave
192.168.179.131:26379 sentinel
192.168.179.132:26379 sentinel
192.168.179.134:26379 sentinel主从节点配置
#192.168.179.131
port 6379
daemonize yes
logfile /var/log/redis_6379.log
dbfilename dump.rdb
#192.168.179.132
port 6379
daemonize yes
logfile /var/log/redis_6379.log
dbfilename dump.rdb
replicaof 192.168.179.131 6379
#192.168.179.134
port 6379
daemonize yes
logfile /var/log/redis_6379.log
dbfilename dump.rdb
replicaof 192.168.179.131 6379测试主从复制是否配置成功
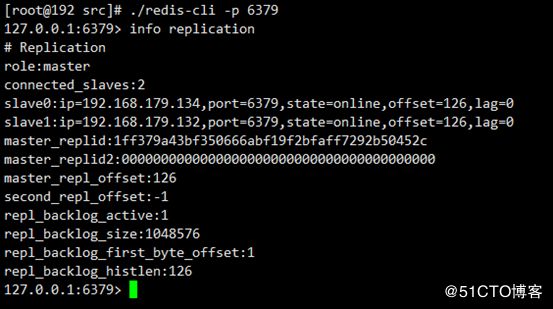
哨兵节点配置
三个哨兵节点相同配置,最后一句配置的意思是监控192.168.179.131这个主节点,节点名称是mymaster,并且至少需要两个哨兵节点同意才能判定主节点故障并进行自动迁移
port 26379
daemonize yes
sentinel monitor mymaster 192.168.179.131 6379 2启动哨兵节点
以下两条命令启动都可以,可以看到哨兵已经启动成功
./src/redis-sentinel sentinel.conf
./src/redis-server sentinel.conf --sentinel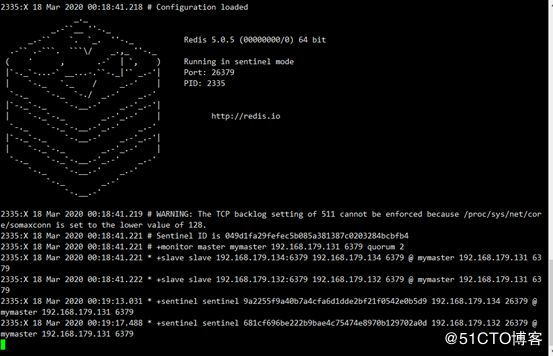
故障转移测试
这里我将192.168.179.131的redis给关掉,查看从节点的复制信息,可以看到redis的主节点已经切换为192.168.179.132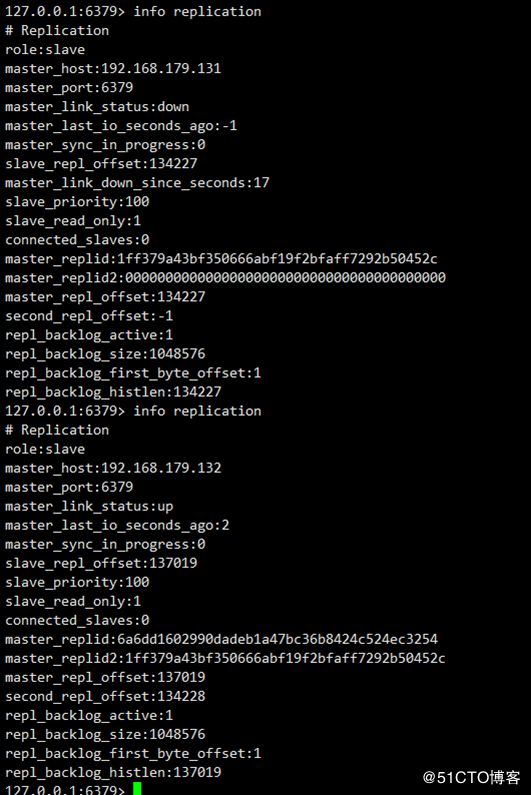
将192.168.179.131上面的redis再次启动,查看节点状态已经变为从节点了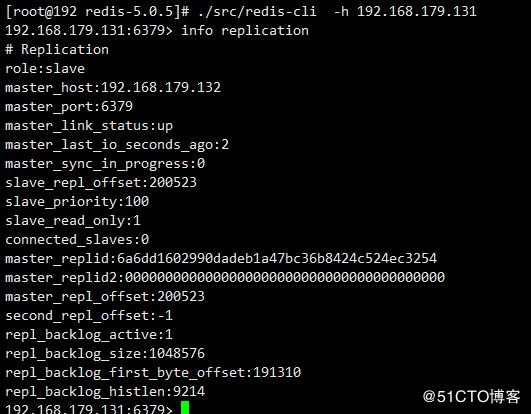
哨兵管理命令
- info sentinel:获取监控的所有主节点的基本信息
- sentinel masters:获取所有被监视主节点的信息
- sentinel master
:获取指定主节点的详细信息 - sentinel slaves
:获取指定主节点的从节点的详细信息 - sentinel sentinels
:获取指定主节点的哨兵节点的详细信息 - sentinel get-master-addr-by-name mymaster:获取主节点的IP地址和端口
- sentinel is-master-down-by-addr:哨兵节点之间可以通过该命令询问主节点是否下线,从而对是否客观下线做出判断
- sentinel failover
: 强制对主节点进行故障转移 - sentinel ckquorum: 检查可用的哨兵数量
- sentinel flushconfig: 强制写入配置文件
- sentinel remove
:取消对指定主节点的监视
Redis集群模式
上面也说到,Redis主从模式中如果主服务器宕掉将无法进行写操作,即使哨兵模式提供了Redis的高可用,但面对数据量比较大的场景,Redis单点就不太能满足这个要求了
Redis 集群是一个分布式、容错的 Redis 实现, 集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集。
Redis 集群是Redis的分布式实现,集群中不存在中心节点或者代理节点, 集群的其中一个主要设计目标是达到线性可扩展性。集群的容错功能是通过使用主节点和从节点两种角色的节点来实现的:主节点和从节点使用完全相同的服务器实现, 它们的功能也完全一样, 但从节点通常仅用于替换失效的主节点。如果不需要保证“先写入,后读取”操作的一致性, 那么可以使用从节点来执行只读查询。
Redis 集群不像单机 Redis 那样支持多数据库功能, 集群只使用默认的 0 号数据库, 并且不能使用 SELECT index 命令。
Redis集群中节点的工作内容
- 保存键值对数据。
- 记录集群的状态,包括键到正确节点的映射。
- 自动发现其他节点,识别工作不正常的节点,并从节点中选举出新的主节点。
键分布模型
Redis 集群的键空间被分割为 16384 个槽(slot), 集群的最大节点数量也是 16384 个。当一个集群处于“稳定”状态时, 集群每个哈希槽都不会进行移动,当需要添加一个节点的时候,只需要将其他节点的某些哈希槽转移到新节点上,当需要删除一个节点的时候,就把此节点的哈希槽转移到其他节点上就可以了。一个主节点可以有任意多个从节点, 这些从节点用于在主节点发生网络断线或者节点失效时, 对主节点进行替换。
集群节点属性
每个节点在集群中都有一个独一无二的 ID , 该 ID 是一个十六进制表示的 160 位随机数, 在节点第一次启动时由 /dev/urandom 生成。
节点会将它的 ID 保存到配置文件, 只要这个配置文件不被删除, 节点就会一直沿用这个 ID 。
节点 ID 用于标识集群中的每个节点。 一个节点可以改变它的 IP 和端口号, 而不改变节点 ID 。 集群可以自动识别出 IP/端口号的变化, 并将这一信息通过 Gossip 协议广播给其他节点知道。
以下是每个节点都有的关联信息, 并且节点会将这些信息发送给其他节点:
- 节点所使用的 IP 地址和 TCP 端口号。
- 节点的标志(flags)。
- 节点负责处理的哈希槽。
- 节点最近一次使用集群连接发送 PING 数据包(packet)的时间。
- 节点最近一次在回复中接收到 PONG 数据包的时间。
- 集群将该节点标记为下线的时间。
- 该节点的从节点数量。
- 如果该节点是从节点的话,那么它会记录主节点的节点 ID 。 如果这是一个主节点的话,那么主节点 ID 这一栏的值为 0000000 。
以上信息的其中一部分可以通过向集群中的任意节点(主节点或者从节点都可以)发送 CLUSTER NODES 命令来获得。
集群数据一致性
Redis集群是无法保证数据的强一致性的
- 原因之一是因为Redis集群是异步复制的,当客户端向服务端的某个主节点写数据时,主服务器会先响应客户端,之后再把写操作请求发送给从节点,在这过程之中,如果主节点发生了宕机,而从节点还没有收到写操作的请求,那么这条数据将会永久丢失,当然可以通过强制数据库在回复客户端以前刷新数据到磁盘,但这样会导致性能降低。
- 还有一种情况是网络分区(network partition)带来的,当Redis集群出现网络分区时,客户端仍对处于小分区的主节点进行写操作,当达到集群的node timeout的时间限制后,处于大分区的那个从节点将会取代处于小分区的主节点称为新的主节点,而在node timeout这段时间里客户端向主节点写入的数据将会丢失
节点失效检测
- 当一个节点向另一个节点发送 PING 命令时, 目标节点未能在node timeout内返回 PING 命令的回复时, 那么发送命令的节点会将目标节点标记为 PFAIL (可能已失效)。
- 每次当节点对其他节点发送 PING 命令的时候, 它都会随机地广播三个它所知道的节点的信息, 这些信息里面的其中一项就是说明节点是否已经被标记为 PFAIL 或者 FAIL 。
- 如果节点已经将某个节点标记为 PFAIL , 并且集群中的大部分其他主节点也认为那个节点进入了失效状态, 那么节点会将那个失效节点的状态标记为 FAIL 。
- 一旦某个节点被标记为 FAIL , 关于这个节点已失效的信息就会被广播到整个集群, 所有接收到这条信息的节点都会将失效节点标记为 FAIL 。
集群搭建
编辑配置文件启动集群节点
每个集群实例都要开启,之后重启redis实例
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000连接集群节点并分配槽
./redis-cli --cluster create 192.168.179.131:6379 192.168.179.131:6380 192.168.179.134:6379 192.168.179.134:6380 192.168.179.132:6379 192.168.179.132:6380 --cluster-replicas 1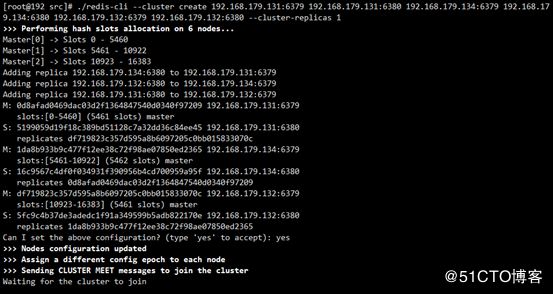
可以查看集群的节点信息,输入集群内任意节点地址即可
./redis-cli --cluster check 192.168.179.132:6379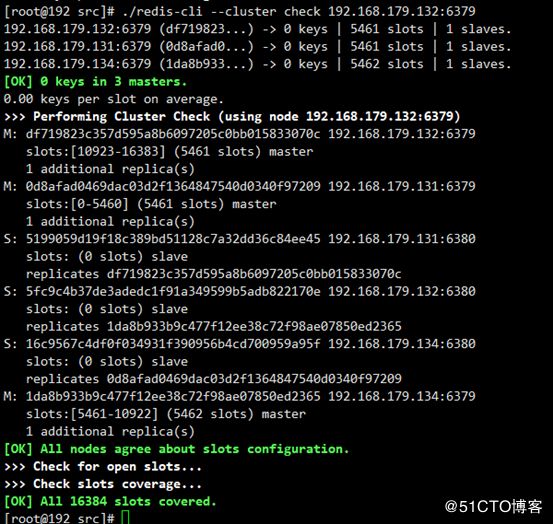
集群验证
当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,当get数据的时候,也是通过这种方法去对应的节点上获取数据
./redis-cli -c -h 192.168.179.132 -p 6380
192.168.179.132:6380> set key 1
-> Redirected to slot [12539] located at 192.168.179.132:6379
OK
./redis-cli -c -h 192.168.179.134 -p 6379
192.168.179.134:6379> get key
-> Redirected to slot [12539] located at 192.168.179.132:6379
"1"欢迎关注个人公号“运维开发故事”