本文作者 Jinkey(微信公众号 jinkey-love,官网 https://jinkey.ai)
原文链接 https://jinkey.ai/post/tech/ling-ji-chu-xiao-bai-zai-mac-shang-pei-zhi-hadoop-dan-dian-wei-fen-bu-ji-qun-tian-keng-guo-cheng
文章允许非篡改署名转载,删除或修改本段版权信息转载的,视为侵犯知识产权,我们保留追求您法律责任的权利,特此声明!

什么是单点伪分布集群
在本地或远程一台电脑上虚拟出几个电脑模拟生产环境下3台以上的服务器集群运行 hadoop,主要用于本地调试数据挖掘的脚本或学习 hadoop 之用。
安装 Java 环境
打开链接:
http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html

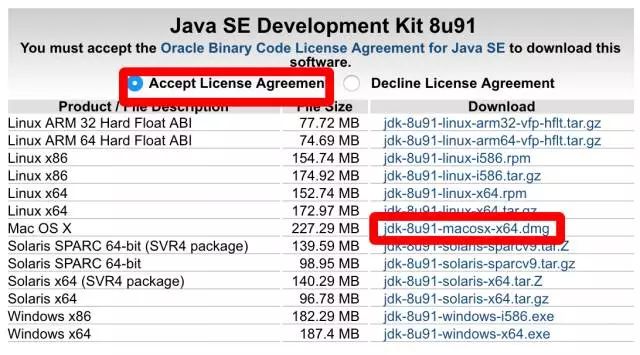
下载好之后双击 dmg 打开然后双击安装...
安装 HomeBrew
下面所有的命令都是在 mac 的 终端 程序运行(在 spotlight 搜索一下就有)
如果之前安装过就不用了
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
安装 Hadoop
执行命令
sudo chmod 777 /usr/local/sbin
不执行权限修改的话会报错
Error: The
brew linkstep did not complete successfully
The formula built, but is not symlinked into /usr/local
Could not symlink sbin/distribute-exclude.sh
/usr/local/sbin is not writable.
接着执行命令:
brew install hadoop
配置 Hadoop
进入 hadoop 目录,2.7.2是你安装的版本号(不知道的可以用sudo hadoop version命令查看)
/usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/
网上有说配置免密钥登录的,可能就不用加sudo 运行本文的指令,你们可以试试;但是对于小白来说很容易踩坑;为了安全性我就不配置免密钥登录了
修改hadoop-env.sh
vim hadoop-env.sh
找到
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
按下键盘上的 i 进入编辑模式(下面的编辑同理,看到左下角有 INSERT 文字代表进入成功)
将上面找到的那一行export 的东西删掉,把下面这一句粘贴上
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。
修改core-site.xml
vim core-site.xml
找到
还是点击 i 进入编辑模式,在中间加入配置,最终效果如下:
hadoop.tmp.dir
/usr/local/Cellar/hadoop/hdfs/tmp
A base for other temporary directories.
fs.default.name
hdfs://localhost:9000
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。
修改mapred-site.xml
目录里面没mapred-site.xml文件,只有一个mapred-site.xml.template ; 所以要先重命名文件。执行命令:
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
找到
还是点击 i 进入编辑模式,在中间加入配置,最终效果如下:
mapreduce.framework.name
yarn
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。
修改hdfs-site.xml
vim hdfs-site.xml
找到
还是点击 i 进入编辑模式,在中间加入配置,最终效果如下:
dfs.replication
1
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。
修改yarn-site.xml
vim yarn-site.xml
找到
还是点击 i 进入编辑模式,在中间加入配置,最终效果如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。
建立 hadoop 启动停止指令的别名方便操作
vim ~/.profile
点击 i 进入编辑模式,加入以下两行
第一行:
alias hstart="/usr/local/Cellar/hadoop/2.6.0/sbin/start-dfs.sh;/usr/local/Cellar/hadoop/2.6.0/sbin/start-yarn.sh"
第二行:
alias hstop="/usr/local/Cellar/hadoop/2.6.0/sbin/stop-yarn.sh;/usr/local/Cellar/hadoop/2.6.0/sbin/stop-dfs.sh"
修改完成后点键盘左上角的 esc 键,然后输入 :wq ,按下键盘 rerurn 即可(这个操作的意思是保存操作并退出)。使该配置生效还需要运行命令:
vim ~/.profile
格式化分布式文件存储系统 HDFS
sudo hdfs namenode -format
因为权限不足,所以不加 sudo 会出现:
Error: Could not find or load main class
org.apache.hadoop.hdfs.server.namenode.NameNode
对应中文系统的提示是:
错误: 找不到或无法加载主类 org.apache.hadoop.hdfs.server.namenode.NameNode
SSH 登录本地服务器
在 Mac 系统默认是禁止远程登录的,所以要在系统的 System Preferences > Sharing > Remote Login选项打上勾,对应的中文路径是系统左上角的 系统偏好设置 > 共享 > 远程登录选项打上勾。
ssh 登录本地计算机
ssh localhost
如果不做之前的系统配置会提示错误
ssh: connect to host localhost port 22: Connection refused
启动 hadoop 伪分布式集群
hstart
然后就是根据提示输入好多次密码,启动成功。