1.key的数据类型
1.1 key的数据结构
Redis key值是二进制安全的,这意味着可以用任何二进制序列作为key值,从形如”foo”的简单字符串到一个JPEG文件的内容都可以。空字符串也是有效key值。
关于key的几条规则:
太长的键值不是个好主意,例如1024字节的键值就不是个好主意,不仅因为消耗内存,而且在数据中查找这类键值的计算成本很高。
太短的键值通常也不是好主意,如果你要用”u:1000:pwd”来代替”user:1000:password”,这没有什么问题,但后者更易阅读,并且由此增加的空间消耗相对于key object和value object本身来说很小。当然,没人阻止您一定要用更短的键值节省一丁点儿空间。
最好坚持一种模式。例如:”object-type:id:field”就是个不错的注意,像这样”user:1000:password”。我喜欢对多单词的字段名中加上一个点,就像这样:”comment:1234:reply.to”。
1.2 key的相关命令
- exists key
指定的key是否存在。时间复杂度:O(1)。返回整数1则表示结果存在,返回0,则表示不存在。
127.0.0.1:6379> exists hello
(integer) 0
127.0.0.1:6379> set hello "hello"
OK
127.0.0.1:6379> exists hello
(integer) 1
127.0.0.1:6379>
- del key
删除指定的一个key或者多个key,返回删除key的个数。注意删除多个key的时候,中间用空格隔开即可。
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set name "www"
OK
127.0.0.1:6379> get name
"www"
127.0.0.1:6379> set age 13
OK
127.0.0.1:6379> get age
"13"
127.0.0.1:6379> set sex 1
OK
127.0.0.1:6379> get sex
"1"
127.0.0.1:6379> del sex
(integer) 1
127.0.0.1:6379> get sex
(nil)
127.0.0.1:6379> del age,name
(integer) 0
127.0.0.1:6379> get age
"13"
127.0.0.1:6379> get name
"www"
127.0.0.1:6379> del age name
(integer) 2
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- set key
设置key-value
127.0.0.1:6379> set name "www"
OK
127.0.0.1:6379> get name
"www"
- get key
获取键key对应的value值。如果key不存在,返回特殊值nil。如果key的value不是string,就返回错误,因为GET只处理string类型的values。
127.0.0.1:6379> set name "www"
OK
127.0.0.1:6379> get name
"www"
- type key
获取key的存储类型。 返回当前key的数据类型,如果key不存在时返回none。
127.0.0.1:6379> set mykey 12
OK
127.0.0.1:6379> get mykey
"12"
127.0.0.1:6379> type mykey
string
127.0.0.1:6379> type hell
none
127.0.0.1:6379> lpush key01 hello
(integer) 1
127.0.0.1:6379> type key01
list
127.0.0.1:6379> sadd key02 hello
(integer) 1
127.0.0.1:6379> type key02
set
127.0.0.1:6379>
- keys pattern
查找所有符合给定模式pattern(正则表达式)的 key 。时间复杂度为O(N)。
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set key01 "hello"
OK
127.0.0.1:6379> lpush key02 "hello"
(integer) 1
127.0.0.1:6379> set otherkey "world
OK
127.0.0.1:6379> keys *
1) "otherkey"
2) "key02"
3) "key01"
127.0.0.1:6379> keys key*
1) "key02"
2) "key01"
127.0.0.1:6379> keys name?
(empty list or set)
127.0.0.1:6379> keys key?
(empty list or set)
127.0.0.1:6379> keys key??
1) "key02"
2) "key01"
127.0.0.1:6379> keys *key*
1) "otherkey"
2) "key02"
3) "key01"
127.0.0.1:6379>
- rename oldkey newkey
将key重命名为newkey,如果newkey已经存在,则值将被覆盖。
127.0.0.1:6379> set newkey01 "wawaw"
OK
127.0.0.1:6379> get newkey01
"wawaw"
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> rename key01 newkey01
OK
127.0.0.1:6379> get key01
(nil)
127.0.0.1:6379> get newkey01
"hello"
127.0.0.1:6379>
- renamenx oldkey newkey
当且仅当 newkey 不存在时,将 key 改名为 newkey 。修改成功是返回1,当newkey存在时,返回0
OK
127.0.0.1:6379> set key "www"
OK
127.0.0.1:6379> get key
"www"
127.0.0.1:6379> set key01 "hello"
OK
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> renamenx key key01
(integer) 0
127.0.0.1:6379> get key
"www"
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> renamenx key newkey
(integer) 1
127.0.0.1:6379> get key
(nil)
127.0.0.1:6379> get newkey
"www"
- expire key seconds
设置key的过期时间,单位是秒(S),超过时间后,会自动删除key-value对。但是在redis的术语中,超时后不一定会删除。
特点:
(1) 超过时间以后,所有会改变此key的值都会立即触发对key的删除操作,例如:del,set,getset命令.
(2) persist命令可以清除超时,让key变成一个永久的key。
(3) 使用rename命令,过期时间会传递到新命名的key上。
(4) expire设置的过期时间是与电脑设备的时钟相关的,比如你设置某key的过期时间为1000,但是在1000之内的时间范围内,你修改了电脑的时间为2000之后,那么此key会立即过期。所以redis的过期时间不是要持续多长时间,而是和电脑时钟相关联。
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> expire key01 3
(integer) 1
127.0.0.1:6379> get key01
(nil)
127.0.0.1:6379>
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> expire key01 60
(integer) 1
127.0.0.1:6379> rename key01 key03
OK
127.0.0.1:6379> get key01
(nil)
127.0.0.1:6379> get key03
"hello"
127.0.0.1:6379> get key03
"hello"
127.0.0.1:6379> get key03
(nil)
127.0.0.1:6379>
127.0.0.1:6379> set key01 hello
OK
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> expire key01 60
(integer) 1
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379> persist key01
(integer) 1
127.0.0.1:6379> get key01
"hello"
127.0.0.1:6379>
- ttl key
获取key的当前剩余的有效时间。如果key已失效,返回-2.
127.0.0.1:6379> expire key01 600
(integer) 1
127.0.0.1:6379> ttl key01
(integer) 594
127.0.0.1:6379> expire key01 10
(integer) 1
127.0.0.1:6379> ttl key01
(integer) 5
127.0.0.1:6379> ttl key01
(integer) 1
127.0.0.1:6379> ttl key01
(integer) -2
- flushdb
删除当前数据库里面的所有数据。这个命令永远不会失败。这个操作的时间复杂度是O(N),N是当前数据库的keys数量。 - flushall
删除所有数据库里面的所有数据,注意不是当前数据库,而是所有数据库。
这个命令永远不会出现失败。
这个操作的时间复杂度是O(N),N是数据库的数量。
2.value的数据类型
2.1 字符串类型(String)
2.1.1 结构
在redis内部,String类型用int和SDS(simple dynamic string)存放字符串。int存放整型,sds存放字节/字符串和浮点型数据。
sds的源码定义为:
typedef char *sds;
SDS 的表头sdshdr有五种类型:它们分别是:sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64,其中sdshdr5是不使用的。目的就是不同大小的字符串可以使用不同的表头,节省空间。每次再创建sds时根据sds实际大小选择合适的sdshdr存储value.
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
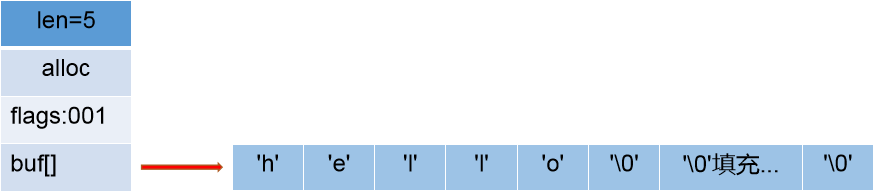
主要看看sdshdr8 。
- sdshdr8:8表示字符串最大长度2^8-1 (长度为255)
- len;表示当前sds的长度(单位是字节)
- alloc:表示以为sds分配的内存大小(单位是字节)
-
flags:用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所
以至少需要3位来表示000:sdshdr5,001:sdshdr8,010:sdshdr16,011:sdshdr32,100:sdshdr64。高5位
用不到所以都为0。
buf[]:sds实际存放的位置。
SDS使用sdshdr8 作为表头保存字符串"hello"的结构图为:
 图片.png
图片.png
2.1.2 特性
- 二进制安全的
- 高效的计算字符串长度(时间复杂度为O(1))
- 高效的追加字符串操作。
- 值可以是任何种类的字符串(包括二进制数据),例如你可以在一个键下保存一副jpeg图片。值的长度不能超过512 MB。
2.1.3 常见命令
- 最基本的命令
GET、SET 语法:GET key,SET key value value如果有空格需要双引号以示区分
127.0.0.1:6379> set name alibaba
OK
127.0.0.1:6379> get name
"alibaba"
127.0.0.1:6379>
- 整数递增:INCR
对存储在指定key的数值执行原子的加1操作,如果
(1) key不存在,则先将key的value设置为0,然后执行原子加1操作。
(2)key存在,如果key中存储的value不是字符串类型或者不能转为整型的字符串的,都会返回 value is not an integer or out of range。
(3)这个操作仅限于64位的有符号整型数据。
事实上,redis内部采用整数形式(Integer representation)来存储对应的整数值,所以对类似整数型的字符串采用的是整数保存形式,并不存在字符串到整数类型的转换,减少字符串存储带来的额外消耗。
127.0.0.1:6379> set name alibaba
OK
127.0.0.1:6379> get name
"alibaba"
127.0.0.1:6379> incr name
(error) ERR value is not an integer or out of range
127.0.0.1:6379> set age 12
OK
127.0.0.1:6379> incr age
(integer) 13
127.0.0.1:6379> incr year
(integer) 1
127.0.0.1:6379> get year
"1"
127.0.0.1:6379>
- 原子增加指定的整数:INCRBY
(1) key不存在,则先将key的value设置为0,然后执行原子加1操作。
(2)key存在,如果key中存储的value不是字符串类型或者不能转为整型的字符串的,都会返回 value is not an integer or out of range。
(3)这个操作仅限于64位的有符号整型数据。
127.0.0.1:6379> get year
"1"
127.0.0.1:6379> incrby year 10
(integer) 11
127.0.0.1:6379> get year
"11"
127.0.0.1:6379>
- 整数递减:DECR
(1) key不存在,则先将key的value设置为0,然后执行原子加1操作。
(2)key存在,如果key中存储的value不是字符串类型或者不能转为整型的字符串的,都会返回 value is not an integer or out of range。
(3)这个操作仅限于64位的有符号整型数据。
127.0.0.1:6379> get year
"11"
127.0.0.1:6379> decr year
(integer) 10
127.0.0.1:6379> get year
"10"
127.0.0.1:6379> get month
(nil)
127.0.0.1:6379> decr month
(integer) -1
- 原子减少指定的整数:DECRBY
语法:DECRBY key increment
127.0.0.1:6379> get month
(nil)
127.0.0.1:6379> decr month
(integer) -1
127.0.0.1:6379> decrby month 12
(integer) -13
127.0.0.1:6379> get month
"-13"
- 向尾部追加值:APPEND
如果key已经存在,并且值为字符串,那么这个命令会把value追加到原来值(value)的结尾。 如果key不存在,那么它将首先创建一个空字符串的key,再执行追加操作。
语法:APPEND key value redis客户端并不是输出追加后的字符串,而是输出字符串总长度
127.0.0.1:6379> append name ",hello world"
(integer) 19
127.0.0.1:6379> get name
"alibaba,hello world"
- 获取字符串长度:STRLEN
语法:STRLEN key 如果键不存在返回0,注意如果有中文时,一个中文长度是3,redis是使用UTF-8编码中文的。
127.0.0.1:6379> get name
"alibaba,hello world"
127.0.0.1:6379> strlen name
(integer) 19
127.0.0.1:6379>
- 获取多个键值:MGET
语法:MGET key [key ...] 例如:MGET key1 key2
127.0.0.1:6379> mget name age
1) "alibaba,hello world"
2) "13"
127.0.0.1:6379>
设置多个键值:MSET
语法:MSET key value [key value ...] 例如:MSET key1 1 key2 "hello redis"获取和设置二进制指定位置值:GETBIT,SETBIT
统计字符串被设置为1的bit数:BITCOUNT
语法:BITCOUNT key [start end] ,start 、end为开始和结束字节。时间复杂度:O(N)
1) "alibaba,hello world"
2) "13"
127.0.0.1:6379> bitcount name 0 19
(integer) 71
2.2 列表(lists)
redis3.2之前,List类型的value对象内部以linkedlist或者ziplist来实现, 当list的元素个数和单个元素的长度比较小的时候,Redis会采用
ziplist(压缩列表)来实现来减少内存占用。否则就会采用linkedlist(双向链表)结构。
2.2.1 结构
redis3.2之后,采用的一种叫quicklist的数据结构来存储list,列表的底层都由quicklist实现,其实就是由是一个ziplist组成的双向链表。quicklist的数据结构如下:
typedef struct quicklistNode {
struct quicklistNode *prev; //上一个node节点
struct quicklistNode *next; //下一个node
unsigned char *zl; //数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head; //头结点
quicklistNode *tail; //尾节点
unsigned long count; /*列表中所有数据项的个数总和 */
unsigned int len; /* quicklist节点的个数,即ziplist的个数 */
int fill : 16; /* fill factor for individual nodes *///负数代表级别,正数代表个数
unsigned int compress : 16; /* depth of end nodes not to compress;0=off *///压缩级别
} quicklist;

2.2.2 特性
2.2.3 常见命令
- lpush:从队列的左侧入队一个元素或者多个元素
将所有指定的值插入到存于 key 的列表的头部。如果 key 不存在,那么在进行 push 操作前会创建一个空列表。 如果 key 对应的值不是一个 list 的话,那么会返回一个错误.
127.0.0.1:6379> lpush key 1 2 3
(integer) 3
127.0.0.1:6379> lrange key 0 3
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lpush key 4 5
(integer) 5
127.0.0.1:6379> lrange key 0,5
(error) ERR wrong number of arguments for 'lrange' command
127.0.0.1:6379> lrange key 0 5
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
- rpush:从队列的右侧入队一个元素或者多个元素
向存于 key 的列表的尾部插入所有指定的值。如果 key 不存在,那么会创建一个空的列表然后再进行 push 操作。 当 key 保存的不是一个列表,那么会返回一个错误。
127.0.0.1:6379> lrange key 0 5
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
127.0.0.1:6379> rpush key 7 8 9
(integer) 8
127.0.0.1:6379> lrange key 0 8
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
7) "8"
8) "9"
- llen:获取队列对应的长度
返回存储在 key 里的list的长度。 如果 key 不存在,那么就被看作是空list,并且返回长度为 0。 当存储在 key 里的值不是一个list的话,会返回error。
127.0.0.1:6379> lrange key 0 8
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
7) "8"
8) "9"
127.0.0.1:6379> llen key
(integer) 8
- lrange:返回指定区间的元素
返回存储在 key 的列表里指定范围内的元素。 start 和 end 偏移量都是基于0的下标,即list的第一个元素下标是0(list的表头),第二个元素下标是1,以此类推。
偏移量也可以是负数,表示偏移量是从list尾部开始计数。 例如, -1 表示列表的最后一个元素,-2 是倒数第二个,以此类推。
127.0.0.1:6379> lrange key 0 8
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
7) "8"
8) "9"
127.0.0.1:6379> lrange key 0 -8
1) "5"
- ltrim:截取list
修剪(trim)一个已存在的 list,这样 list 就会只包含指定范围的指定元素。start 和 stop 都是由0开始计数的, 这里的 0 是列表里的第一个元素(表头),1 是第二个元素,以此类推。
例如: LTRIM foobar 0 2 将会对存储在 foobar 的列表进行修剪,只保留列表里的前3个元素。
start 和 end 也可以用负数来表示与表尾的偏移量,比如 -1 表示列表里的最后一个元素, -2 表示倒数第二个,等等。
超过范围的下标并不会产生错误:如果 start 超过列表尾部,或者 start > end,结果会是列表变成空表(即该 key 会被移除)。 如果 end 超过列表尾部,Redis 会将其当作列表的最后一个元素。
127.0.0.1:6379> ltrim key 0 5
OK
127.0.0.1:6379> lrange key 0 8
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
127.0.0.1:6379>
- lset:设置指定位置的值
设置 index 位置的list元素的值为 value
127.0.0.1:6379> lrange key 0 8
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
127.0.0.1:6379> lset key 0 "hello"
OK
127.0.0.1:6379> lrange key 0 8
1) "hello"
2) "4"
3) "3"
4) "2"
5) "1"
6) "7"
- lrem:从列表中删除出现前count次的value值相同的元素
从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
count > 0: 从头往尾移除值为 value 的元素。
count < 0: 从尾往头移除值为 value 的元素。
count = 0: 移除所有值为 value 的元素。
比如, LREM list -2 “hello” 会从存于 list 的列表里移除最后两个出现的 “hello”。
需要注意的是,如果list里没有存在key就会被当作空list处理,所以当 key 不存在的时候,这个命令会返回 0。
127.0.0.1:6379> lpush name wang wang cong zhang meng wang wu han shan wang
(integer) 10
127.0.0.1:6379> lrange name 0 9
1) "wang"
2) "shan"
3) "han"
4) "wu"
5) "wang"
6) "meng"
7) "zhang"
8) "cong"
9) "wang"
10) "wang"
127.0.0.1:6379> lrem name 2 wang
(integer) 2
127.0.0.1:6379> lrange name 0 9
1) "shan"
2) "han"
3) "wu"
4) "meng"
5) "zhang"
6) "cong"
7) "wang"
8) "wang"
- lpop:从列表左侧删除一个元素
移除并且返回 key 对应的 list 的第一个元素。
127.0.0.1:6379> lrange name 0 9
1) "shan"
2) "han"
3) "wu"
4) "meng"
5) "zhang"
6) "cong"
7) "wang"
8) "wang"
127.0.0.1:6379> lpop name
"shan"
127.0.0.1:6379>
2.3 哈希(hashs)
2.3.1 结构
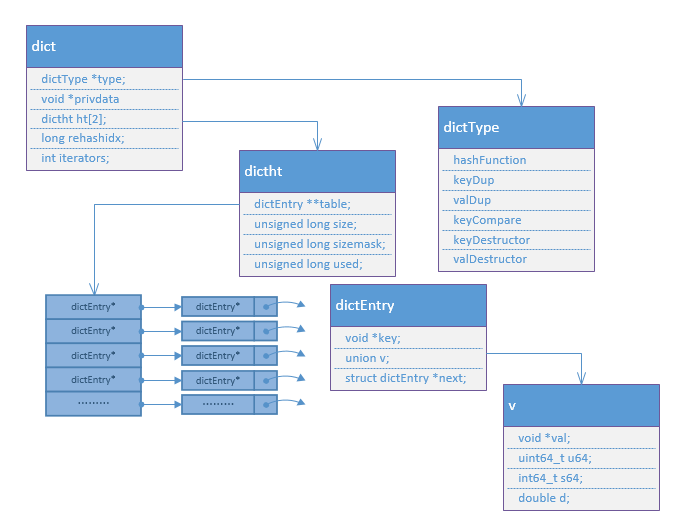
dict中ht[2]中有两个hash表, 我们第一次存储数据的数据时, ht[0]会创建一个最小为4的hash表, 一旦ht[0]中的size和used相等, 则dict中会在ht[1]创建一个size*2大小的hash表, 此时并不会直接将ht[0]中的数据copy进ht[0]中, 执行的是渐进式rehash, 即在以后的操作(find, set, get等)中慢慢的copy进去, 以后新添加的元素会添加进ht[0], 因此在ht[1]被占满的时候定能确保ht[0]中所有的数据全部copy到ht[1]中.
/*Hash表一个节点包含Key,Value数据对 */
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* 指向下一个节点, 链接表的方式解决Hash冲突 */
} dictEntry;
/* 存储不同数据类型对应不同操作的回调函数 */
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
typedef struct dictht {
dictEntry **table; /* dictEntry*数组,Hash表 */
unsigned long size; /* Hash表总大小 */
unsigned long sizemask; /* 计算在table中索引的掩码, 值是size-1 */
unsigned long used; /* Hash表已使用的大小 */
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; /* 两个hash表,ht[0]平时用,ht[1]rehash时使用*/
long rehashidx; /* rehash的索引, -1表示没有进行rehash */
int iterators; /* */
} dict;
2.3.2 特性
2.3.3 常见命令
- hset
hset key field value 设置hash field为指定值,如果key不存在,则先创建
hget key field 获取指定的hash field
hmget key filed1....fieldN 获取全部指定的hash filed
hmset key filed1 value1 ... filedN valueN 同时设置hash的多个field
hincrby key field integer
2.4 集合(sets)
2.4.1 结构
集合类型set中,元素是不重复且无序的。集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在。由于集合类型在redis内部是使用的值为空的散列表(hash
table),所以这些操作的时间复杂度都是O(1).
2.4.2 特性
2.4.3 常见命令
集合常见操作是添加元素,删除元素,判断元素是否存在等。
- 添加元素:sadd
添加一个或多个指定的member元素到集合的 key中.指定的一个或者多个元素member 如果已经在集合key中存在则忽略.如果集合key 不存在,则新建集合key,并添加member元素到集合key中.返回添加元素的个数。
127.0.0.1:6379> sadd loans loans1 loans2 loans3 loans4
(integer) 4
127.0.0.1:6379>
- 移除元素:srem
在key集合中移除指定的元素. 如果指定的元素不是key集合中的元素则忽略 如果key集合不存在则被视为一个空的集合,该命令返回0.
127.0.0.1:6379> sadd loans loans1 loans2 loans3 loans4
(integer) 4
127.0.0.1:6379> srem loans loans3
(integer) 1
127.0.0.1:6379> srem jj kk
(integer) 0
127.0.0.1:6379> strem loans loan1 loan3
(error) ERR unknown command 'strem'
127.0.0.1:6379> srem loans loans1 loans3
(integer) 1
127.0.0.1:6379>
- 删除并获取集合中的元素:spop
从存储在key的集合中移除并返回一个或多个随机元素。
127.0.0.1:6379> spop loans 3
1) "loans2"
2) "loans4"
127.0.0.1:6379> spop key 5
(empty list or set)
127.0.0.1:6379>
- 从集合里面随机获取一个数:srandmember
127.0.0.1:6379> sadd loans loans1 loans2 loans3 loans4
(integer) 4
127.0.0.1:6379> srandmember loans 1
1) "loans2"
127.0.0.1:6379> srandmember loans 2
1) "loans2"
2) "loans4"
127.0.0.1:6379>
- **获取集合中元素数量:scard **
127.0.0.1:6379> sadd loans loans1 loans2 loans3 loans4
(integer) 4
127.0.0.1:6379> srandmember loans 1
1) "loans2"
127.0.0.1:6379> srandmember loans 2
1) "loans2"
2) "loans4"
127.0.0.1:6379> scard loans
(integer) 4
- **确定一个给定的元素值是集合中的元素:sismember **
如果member元素是集合key的成员,则返回1
如果member元素不是key的成员,或者集合key不存在,则返回0
127.0.0.1:6379> sismember loans loans1
(integer) 1
127.0.0.1:6379> sismember loans loans6
(integer) 0
2.5 有序集合(sorted-sets)
2.5.1 结构
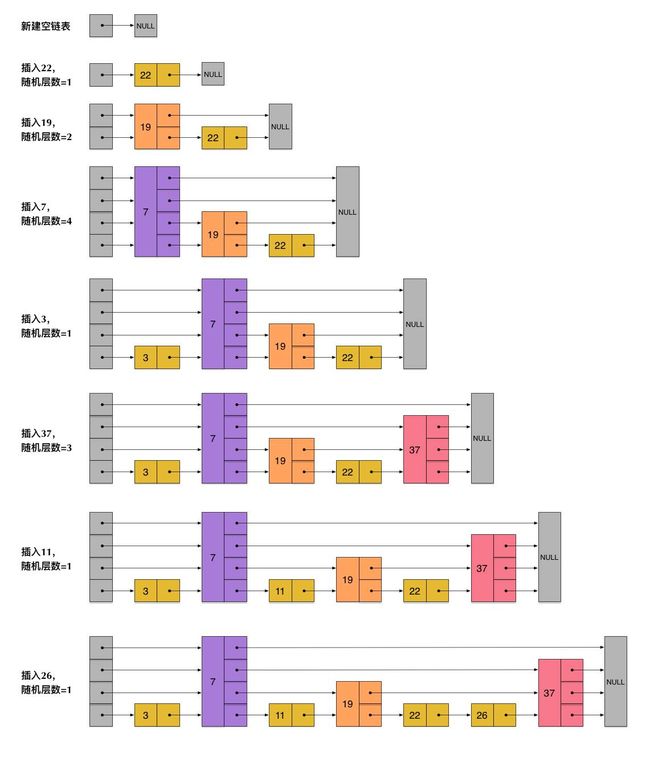
redis中的有序集合使用了跳跃表skiplist实现的数据结构。可以实现平均复杂度为O(longN)的插入、删除和查找操作。
/* 跳跃表节点定义 */
typedef struct zskiplistNode {
// 存放的元素值
robj *obj;
// 节点分值,排序的依据
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨越的节点数量
unsigned int span;
} level[];
/* 跳跃表定义 */
typedef struct zskiplist {
// 跳跃表的头结点和尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前跳跃表的最大层数
int level;
} zskiplist;
2.5.2 特性
2.5.3 常见命令
- zadd
key score member 添加元素到集合,元素在集合中存在则更新对应score.
127.0.0.1:6379> zadd newset 1 "one"
(integer) 1
127.0.0.1:6379> zadd newset 4 "four"
(integer) 1
127.0.0.1:6379> zrange newset 0 -1 withscores
1) "one"
2) "1"
3) "four"
4) "4"
- zrem
key member 删除指定元素,1表示成功,如果元素不存在返回0 - zincrby
key incr member 增加对应member的score值,然后移动元素并保持skip list有序。返回更新后的score值 - zrank
key member 返回指定元素在集合中的排名(下标,非score),集合中元素是按score从小到大排序的 - zrevrank
key member 同上,但是集合中元素是按score从大到小排序 - zrange
key start end 类似lrange操作从集合中取指定区间的元素。返回的是有序结果 - zrevrange
key start end 同上,返回结果是按score逆序的 - zrangebyscore
key min max 返回集合中score在给定区间的元素 - zcount
key min max 返回集合中score在给定区间的数量 - zcard
key 返回集合中元素个数 - zscore
key element 返回给定元素对应的score - zremrangebyrank
key min max 删除集合中排名在给定区间的元素 - zremrangebyscore
key min max 删除集合中score在给定区间的元素