Sqoop介绍
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。其机制是将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
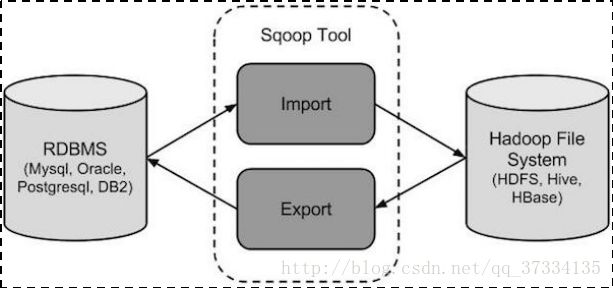
Sqoop的安装
1、将Sqoop包上传到hadoop集群,我这里用的是sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz。解压后改下名字sqoop
[root@mini1 ~]#tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
[root@mini1 ~]# mv sqoop-1.4.6xxxx(解压后的包名)sqoop
2、修改配置文件
进入conf目录修改sqoop-env-template.sh名字为sqoop-env.sh
并修改该文件内容,三个地方,一个hadoop命令所在位置,一个mapreduce所在位置,一个hive命令所在位置(怎么查看命令位置可以使用which,比如which hive,但是这里可以指定一个父目录)。
[root@mini1 ~]# cd sqoop
[root@mini1 sqoop]#cd conf/
[root@mini1 conf]# ll
总用量 28
-rw-rw-r--. 1 root root 3895 4月 27 2015 oraoop-site-template.xml
-rw-rw-r--. 1 root root 1404 4月 27 2015 sqoop-env-template.cmd
-rwxr-xr-x. 1 root root 1345 4月 27 2015 sqoop-env-template.sh
-rw-rw-r--. 1 root root 5531 4月 27 2015 sqoop-site-template.xml
-rw-rw-r--. 1 root root 5531 4月 27 2015 sqoop-site.xml
[root@mini1 conf]# mv sqoop-env-template.sh sqoop-env.sh
[root@mini1 conf]#vi sqoop-env.sh
...
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/root/apps/hadoop-2.6.4/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/root/apps/hadoop-2.6.4/
#Set the path to where bin/hive is available
export HIVE_HOME=/root/apps/hive/
...
3、加入mysql的驱动包
由于装hive的时候就将mysql驱动包传到了hive的lib目录下,这里直接拷贝过来即可
[root@mini1 conf]#cd ..
[root@mini1 sqoop]# cp /root/apps/hive/lib/mysql-connector-java-5.1.28.jar ./lib/
到这就安装完成了。
可能的问题
mysql-connector-java-5.1.28.jar
这个jar包的版本必须在28之上,否则可能会有问题。
数据导入
1、导入数据库表数据导入到hdfs
mysql创建表,插入数据,为了使用方便复制了如下
mysql> use test
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql>CREATE TABLE `emp` (
`id` int(32) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`deg` varchar(255) NOT NULL,
`salary` int(11) NOT NULL,
`dept` varchar(32) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| emp |
| t_user |
+----------------+
2 rows in set (0.01 sec)
mysql> desc emp;
+--------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+----------------+
| id | int(32) | NO | PRI | NULL | auto_increment |
| name | varchar(255) | NO | | NULL | |
| deg | varchar(255) | NO | | NULL | |
| salary | int(11) | NO | | NULL | |
| dept | varchar(32) | NO | | NULL | |
+--------+--------------+------+-----+---------+----------------+
5 rows in set (0.02 sec)
mysql> INSERT INTO `test`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) VALUES ('1', 'zhangsan', 'manager', '30000', 'AA');
Query OK, 1 row affected (0.02 sec)
mysql> INSERT INTO `test`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) VALUES ('2', 'lisi', 'programmer', '20000', 'AA');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO `test`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) VALUES ('2', 'wangwu', 'programmer', '15000', 'BB');
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
mysql> INSERT INTO `test`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) VALUES ('3', 'wangwu', 'programmer', '15000', 'BB');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO `test`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) VALUES ('4', 'hund', 'programmer', '5000', 'CC');
Query OK, 1 row affected (0.01 sec)
mysql> select * from emp;
+----+----------+------------+--------+------+
| id | name | deg | salary | dept |
+----+----------+------------+--------+------+
| 1 | zhangsan | manager | 30000 | AA |
| 2 | lisi | programmer | 20000 | AA |
| 3 | wangwu | programmer | 15000 | BB |
| 4 | hund | programmer | 5000 | CC |
+----+----------+------------+--------+------+
使用下面的命令将test数据库中的emp表导入到hdfs(有默认目录)
bin/sqoop import \
--connect jdbc:mysql://192.168.25.127:3306/test \
--username root \
--password 123456 \
--table emp \
--m 1
数据库ip,使用的数据库
mysql用户名
mysql密码
要导入的表
注:m 1 表示使用一个mapreduce
程序在执行的时候能看到是跑了mapreduce程序的。
执行完毕后页面进行查看(/user/root是默认默认目录,我用的是root用户)
查看文件内容(数据间逗号隔开的)
[root@mini1 sqoop]# hadoop fs -ls /user/root/emp
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-10-26 09:49 /user/root/emp/_SUCCESS
-rw-r--r-- 2 root supergroup 110 2017-10-26 09:49 /user/root/emp/part-m-00000
[root@mini1 sqoop]# hadoop fs -cat /user/root/emp/part-m-00000
1,zhangsan,manager,30000,AA
2,lisi,programmer,20000,AA
3,wangwu,programmer,15000,BB
4,hund,programmer,5000,CC
注:执行导入的时候很大可能出现下面的异常
java.sql.SQLException: Access denied for user 'root'@'mini1' (using password: YES)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1086)
...
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227)
at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
17/10/26 00:01:46 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: No columns to generate for ClassWriter
这基本就是没授权导致的,给mini1授权即可如下
mysql> grant all privileges on *.* to root@mini1 identified by "123456";
Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql> show grants for root@mini1;
+------------------------------------------------------------------------------------------------------------------------------------+
| Grants for root@mini1 |
+------------------------------------------------------------------------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'mini1' IDENTIFIED BY PASSWORD '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'mini1' WITH GRANT OPTION |
+------------------------------------------------------------------------------------------------------------------------------------+
2、emp表数据导入到hive表中
其实是先导入到hdfs,再由hdfs导入到hive(属于剪切粘贴)
先将前面生成的目录删了
[root@mini2 ~]# hadoop fs -rm -r /user/root
执行以下命令导入emp表数据到hive表(表名也是emp)
[root@mini1 sqoop]# bin/sqoop import \
> --connect jdbc:mysql://192.168.25.127:3306/test \
> --username root \
> --password 123456 \
> --table emp \
> --hive-import \
> --m 1
...
17/10/26 10:04:13 INFO mapreduce.Job: Job job_1508930025306_0022 running in uber mode : false
17/10/26 10:04:13 INFO mapreduce.Job: map 0% reduce 0%
17/10/26 10:04:17 INFO mapreduce.Job: map 100% reduce 0%
17/10/26 10:04:18 INFO mapreduce.Job: Job job_1508930025306_0022 completed successfully
17/10/26 10:04:19 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=124217
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=110
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=2926
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=2926
Total vcore-milliseconds taken by all map tasks=2926
Total megabyte-milliseconds taken by all map tasks=2996224
...
17/10/26 10:04:21 INFO hive.HiveImport: It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
17/10/26 10:04:27 INFO hive.HiveImport: OK
17/10/26 10:04:27 INFO hive.HiveImport: Time taken: 1.649 seconds
17/10/26 10:04:27 INFO hive.HiveImport: Loading data to table default.emp
17/10/26 10:04:28 INFO hive.HiveImport: Table default.emp stats: [numFiles=1, totalSize=110]
17/10/26 10:04:28 INFO hive.HiveImport: OK
17/10/26 10:04:28 INFO hive.HiveImport: Time taken: 0.503 seconds
17/10/26 10:04:28 INFO hive.HiveImport: Hive import complete.
17/10/26 10:04:28 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.
将重要的输出信息都粘贴了下来,可见是先导入到hdfs的文件中,再移动到hive中的。
去hive中查看是否创建了该表导入了数据
hive> select * from emp;
OK
1 zhangsan manager 30000 AA
2 lisi programmer 20000 AA
3 wangwu programmer 15000 BB
4 hund programmer 5000 CC
Time taken: 0.641 seconds, Fetched: 4 row(s)
3、导入数据到hdfs指定目录
跟导入数据到hdfs查了句指定目录
[root@mini1 sqoop]# bin/sqoop import \
> --connect jdbc:mysql://192.168.25.127:3306/test \
> --username root \
> --password 123456 \
> --table emp \
> --target-dir /queryresult \
> --m 1
执行后查看
[root@mini3 ~]# hadoop fs -ls /queryresult
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-10-26 10:14 /queryresult/_SUCCESS
-rw-r--r-- 2 root supergroup 110 2017-10-26 10:14 /queryresult/part-m-00000
[root@mini3 ~]# hadoop fs -cat /queryresult/part-m-00000
1,zhangsan,manager,30000,AA
2,lisi,programmer,20000,AA
3,wangwu,programmer,15000,BB
4,hund,programmer,5000,CC
4、导入表数据子集
有时候不是整张表都要导入,那么可以按照需要来进行导入。
比如只导入id,name,salary三个字段,且要求deg=programmer
如下
bin/sqoop import \
--connect jdbc:mysql://192.168.25.127:3306/test \
--username root \
--password 123456 \
--target-dir /wherequery2 \
--query 'select id,name,deg from emp WHERE deg = "programmer" and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\t' \
--m 1
split-by id表示按照id切片,fields-terminated-by ‘\t’表示导入到文件系统中的数据分隔符为”\t”,默认是”,”
[root@mini3 ~]# hadoop fs -ls /wherequery2
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-10-26 10:21 /wherequery2/_SUCCESS
-rw-r--r-- 2 root supergroup 56 2017-10-26 10:21 /wherequery2/part-m-00000
[root@mini3 ~]# hadoop fs -cat /wherequery2/part-m-00000
2 lisi programmer
3 wangwu programmer
4 hund programmer
--split-by原理
1)--split-by的原理
设置并行--num-mappers=4,加--split-by的情况会根据主键先查最大值和最小值,即:select min(key_id),max(key_id) from tb_oracle_stock_info_key。
如tb_oracle_stock_info_key(股票信息表)中 key_id(主键)最小值为300,最大值为400,那么4个并行度的切片情况如下:
并行度实现的sql如下:
select * from tb_oracle_stock_info_key where key_id between 300 and 325;
select * from tb_oracle_stock_info_key where key_id between 325 and 350;
select * from tb_oracle_stock_info_key where key_id between 351 and 375;
select * from tb_oracle_stock_info_key where key_id between 376 and 400;
综上所述,加--split-by参数后,使用大于1个并行时,效果理论上优于没有加--split-by参数作业。
2)数据倾斜
假设oracle的表tb_oracle_stock_info_key(股票信息表)主键为key_id,sqoop根据max(key_id)来平均分配4份。假设min(key_id)=1,max(key_id)=400,那么导数的时候会按400切割生4份,即 :
select * from tb_oracle_stock_info_key where key_id between 1 and 100;
select * from tb_oracle_stock_info_key where key_id between 101 and 200;
select * from tb_oracle_stock_info_key where key_id between 201 and 300;
select * from tb_oracle_stock_info_key where key_id between 301 and 400;
但是由于数据特殊的原因,key_id=[1,100]分区内自由1条数据,key_id=[101,300]内完全没有数据,99%数据都是key_id=[301,400],这样就会产生数据倾斜,也就是4个并行中,有3个不耗费时间,有1个花了大部分时间,这样的并行效果相当的不好:
因此,在使用并行度的时候需要了解主键的分布情况是是否有必要的。
5、增量导入
增量导入这里是仅导入新增加的表中的行,比如emp表有4条记录,但是我们新表中只需要导入id为3和4的记录进去
使用以下命令
bin/sqoop import \
--connect jdbc:mysql://192.168.25.127:3306/test \
--username root \
--password 123456 \
--table emp --m 1 \
--incremental append \
--check-column id \
--last-value 2
[root@mini1 sqoop]# bin/sqoop import \
> --connect jdbc:mysql://192.168.25.127:3306/test \
> --username root \
> --password 123456 \
> --table emp --m 1 \
> --incremental append \
> --check-column id \
> --last-value 2
[root@mini1 sqoop]# hadoop fs -ls /user/root/emp
Found 1 items
-rw-r--r-- 2 root supergroup 55 2017-10-26 10:28 /user/root/emp/part-m-00000
[root@mini1 sqoop]# hadoop fs -cat /user/root/emp/part-m-00000
3,wangwu,programmer,15000,BB
4,hund,programmer,5000,CC
数据导出
将hdfs上数据导入到mysql数据库表中
注:需要将mysql上数据库和表创建出来才能导出
继续使用上面的emp表,但是将数据清空
mysql> select * from emp;
+----+----------+------------+--------+------+
| id | name | deg | salary | dept |
+----+----------+------------+--------+------+
| 1 | zhangsan | manager | 30000 | AA |
| 2 | lisi | programmer | 20000 | AA |
| 3 | wangwu | programmer | 15000 | BB |
| 4 | hund | programmer | 5000 | CC |
+----+----------+------------+--------+------+
4 rows in set (0.00 sec)
mysql> truncate emp;
Query OK, 0 rows affected (0.05 sec)
mysql> select * from emp;
Empty set (0.00 sec)
使用以下命令,将数据从hdfs上指定目录数据导出到mysql指定的数据库和表上
bin/sqoop export \
--connect jdbc:mysql://192.168.25.127:3306/test \
--username root \
--password 123456 \
--table emp \
--export-dir /user/root/emp/
执行完之后查看表emp数据
mysql> select * from emp;
+----+--------+------------+--------+------+
| id | name | deg | salary | dept |
+----+--------+------------+--------+------+
| 3 | wangwu | programmer | 15000 | BB |
| 4 | hund | programmer | 5000 | CC |
+----+--------+------------+--------+------+
2 rows in set (0.00 sec)
导出完成