HDU原题链接:传送门
最长回文
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 33823 Accepted Submission(s): 12368
Problem Description
给出一个只由小写英文字符a,b,c...y,z组成的字符串S,求S中最长回文串的长度.
回文就是正反读都是一样的字符串,如aba, abba等
Input
输入有多组case,不超过120组,每组输入为一行小写英文字符a,b,c...y,z组成的字符串S
两组case之间由空行隔开(该空行不用处理)
字符串长度len <= 110000
Output
每一行一个整数x,对应一组case,表示该组case的字符串中所包含的最长回文长度.
Sample Input
aaaa
abab
Sample Output
4
3
题目分析——马拉车算法
本题是Manacher(马拉车)算法的一题模板题,解决一个字符串的最长回文子串的问题,解题之前需要讲述一下马拉车算法的原理,我找了一篇讲解这个算法比较好的博客:传送门 参考前辈的文章后,在此也做出一些自己的总结,以免时间久了自己产生遗忘,当然马拉车算法代码量极少,但是其思想却需要仔细揣摩,做好准备我们就开始吧!
首先对于一个给出的字符串,例如aba,abba,abababadfsaa等,最直观的想到的去求它的最长回文子串的方法是从左到右遍历每一个字符,以这个字符作为回文串的中心,然后不断向两边扩充,直到不满足后遍历下一个字符,求出最长的回文子串的长度。但是这么做在字符串长度很长时效率很低,花费大量的时间。
在介绍马拉车算法之前,有必要先提及一个很巧妙且重要的方法,不知你是否发现,通过上述的方法求回文子串,我们总是以一个字符为出发点向两边匹配,那么每次所匹配出来的回文串都是奇数,而无法判断abba这样的偶数回文串,所以就产生了一种拼接字符串的神奇方法,将一个初始的字符串用一个不会出现的字符隔开,例如#a#b#a#,#a#b#b#a#,你惊奇的发现,无论是奇数还是偶数的字符串经过这么处理之后不但不会改变它原有的对称特性(只是长度好像变长了一倍?因为#也是一个字符,且它的存在不会打断原有的回文特性,只是增长了而已,放心下面会讲明它变长的长度是有着一个固定的数学关系的),而且所有的串都变成了奇数串(奇+偶=奇,偶+奇=奇),秒啊!
那么我们得到了一个类似#a#b#a#的串之后该怎么做呢,别急,我们需要将这个字符再做一点处理,在它最前面插入一个不会出现且不同于#的字符,就像$#a#b#a#这样,这么做有一个好处,就是我们将实际会用于算法求解的字符从下标0开始转化成了从下标1开始,后面我们遍历时也是从下标1开始的,这样第一个有效字符的位置就是s[1],第二个就是s[2],方便后面我们使用马拉车算法进行推导。
对于一个字符串如:$#a#a#b#a#a#,我们设P[i]为以第i个字符为回文串中心时最长的回文半径(包含S[i]本身),那么遍历P[i]就可以找出最长的回文子串的长度
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | $ | # | a | # | a | # | b | # | a | # | a | # |
| P | 1 | 1 | 2 | 3 | 2 | 1 | 6 | 1 | 2 | 3 | 2 | 1 |
| 下标 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| s | a | a | b | a | a |
| p | 1 | 1 | 3 | 1 | 1 |
此时就会有人提出疑问,这个是我拼接之后的字符串呀,求出它的最长回文子串的长度与求拼接前的最长回文子串长度有什么关系吗?有关系,你发现上述拼接后的字符串最长回文子串是以i==6为中心的,就是以b这个字符为中心,那么你惊奇的发现原字符串最长回文子串一定也是以b为中心的,因为我们上面就提到了,拼接的#不会影响原字符串的回文特性,只是让它们在原先的基础上都变长了而已,而它们之间的关系很显然是2倍关系P[i]==2*p[i],由于题目所求的是原字符串的最长回文子串的长度,那么答案就是P[i]-1,因为我们自始自终用拼接后的字符串参与推导,所以只要关注P[i]数组即可。
那么所有问题的矛头都指向一处!p[i]怎么求(下面都用小写的p代表拼接后字符串的以i为回文中心的最长回文半径,频繁切换大写让我觉得有些异样w(゚Д゚)w),马拉车算法,启动!因为我们是从左到右遍历i的,在计算p[i]时我们要确保p[1]~p[i-1]已经求出,这样才能借助回文串的对称特性,也是就前面求出来的p[j]减少后面p[i]的匹配次数(此时你可能不明白这句话的含义,且仔细往下看),我们要用到两个辅助的变量id和mx,id为i之前的一个能向右伸展的最远的回文串的回文串中心,mx为以id为回文中心的这个回文串往右(往左)能伸展到的最远的距离
还是借助一下图来更加清晰的展示
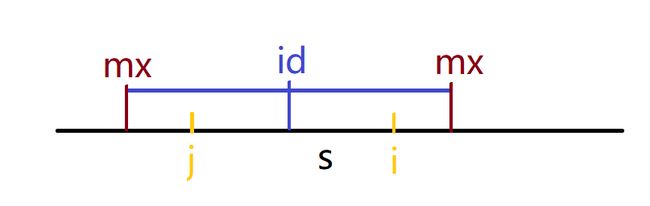
其中j是i关于id的对称点,j=2*id-i,这个自行推一下便可,那么此时上图展示的只是其中一种情况,当以i为回文中心的时i点在左侧一个向右伸展足够长至把i点包括其中的回文串内,即i 由于以i和j为中心的回文串是关于id对称的两个子串,所以p[i]自然而然和p[j]相等,即p[i]=p[2*id-i] 左边的绿色线代表超过id左边界的回文串,此时,由于对称关系,只能得知以i为中心的回文串在id右边界之内的部分和以j为中心的回文串在id左边界之内的部分是对称的,而以i为中心的超过右边界的部分则只能老老实实向两侧匹配,所以在这两种情况下,如果p[2 * id-i]>=mx-i+1,则说明超过左边界,则只取用边界内的对称部分p[i]=mx-i+1,如果p[2 * id-i] 不要忘记还有一种大情况,就是i点在mx的边界或者外面时 在这两种情况下,p[i]是否对称都要从超过id右边界(mx)的地方开始一个一个首尾比较,所以没有办法借助p[j]来减少预匹配的次数,直接调用上面的函数老老实实匹配吧 要注意的是随着每一次i的遍历之后,如果mx能更加向右延伸,即p[i]+i-1>p[id]+id-1,-1是因为重复加点了,仔细推理一下便可,例如id=5,p[id]=3,则mx=p[id]+id-1=7,那么要更新id的位置为i,更新mx为p[i]+i-1,确保id永远是右边界最接近下一个要遍历的i点那个对称中心

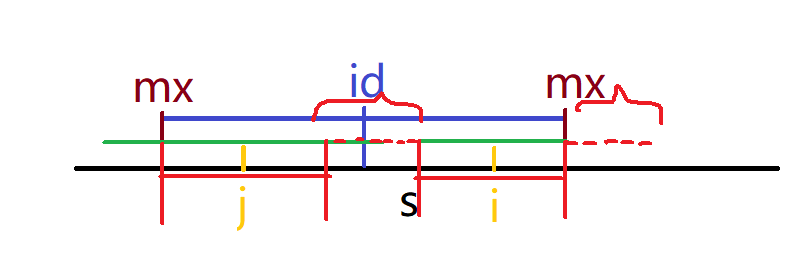
//在借助回文串i前已经计算出的数据减少匹配次数后,依旧要老老实实调用下面的函数去匹配
while(i-p[i]>=1&&i+p[i]<=len*2+1){ //下标向左不越界,下标向右不越界
if(s[i-p[i]]==s[i+p[i]]) p[i]++; //初始化p[i]都是1,至少回文半径是1
else break;
}
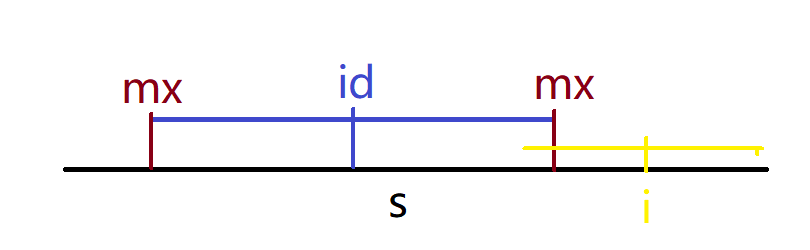
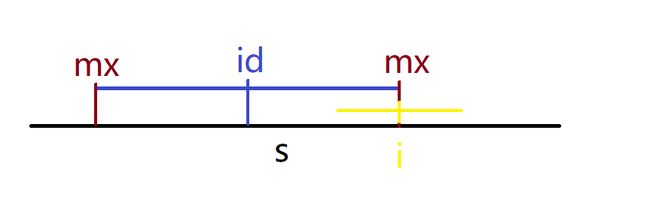
示例代码
#include