第一章内容小节
1.1 AVFoundation的含义
1.2 AVFoundation的适用范围
1.3解析AVFoundation
1.4了解数字媒体
1.5数字媒体压缩
1.6容器格式
1.7初始AVFoundation
一. AV Foundation的含义
AV Foundation 是苹果OS X系统和iOS系统中用于处理基于时间的媒体数据的高级Objective-C框架,其设计过程高度依赖多线程机制。充分利用了多核硬件的优势并大量使用block 和GCD机制将复杂的计算机进程放在后台线程运行。会自动提供硬件加速操作,确保在大部分设备上应用程序能以最佳性能运行。AV Foundation的设计充分考虑了电量效率来满足移动设备对电量控制的高要求。此外,从一开始该框架就是针对64位处理器设计的,可以发挥64位处理器的所有优势。
二.AV Foundation的适用范围
1.Core Audio
Core Audio 是OS X和iOS 系统上处理所有音频事件的框架。Core Audio是由多个框架整合在一起的总称,为音频和MIDI内容的录制,播放和处理提供相应接口。Core Audio也提供高层级的接口,比如Audio Queue Services 框架所提供的那些接口,主要处理基本的音频播放和录音相关功能。同时提供相对低层级的接口,尤其是Audio Units 接口,它们提供了针对音频信号进行完全控制的功能,并通过Audio Units让你能够构建一些复杂的音频处理模式。
2.Core Video
Core Video 是OS X和iOS系统上针对数字视频所提供的管道模式。Core Video为其相对的Core Media 提供图片缓存和缓存池支持,提供了一个能够对数字视频逐帧访问的接口。该框架通过像素格式之间的转换并管理视频事项使得复杂的工作得到了有效简化。
3.Core Media
Core Media 是AV Foundation 所用到的低层级媒体管道的一部分。它提供针对音频样本和视频帧处理所需的低层级数据类型和接口。Core Media还提供了AV Foundation用到的基于CMTime数据类型的时基模型,CMTime及其相关数据类型一般在AV Foundation 处理基于时间的操作时使用。
4.Core Animation
Core Animation是OS X和iOS提供的合成及动画相关框架。主要功能就是提供苹果平台所具有的美观、流畅的动画效果。使用Core Animation时,对于视频内容的播放和视频捕获这两个动作,AV Foundation 提供了硬件加速机制来对整个流程进行优化。AV Foundation 还可以用Core Animation让开发者能够在视频编辑和播放过程中添加动画标题和图片效果。
处于高层级框架和低层级框架之间的就是AV Foundation。
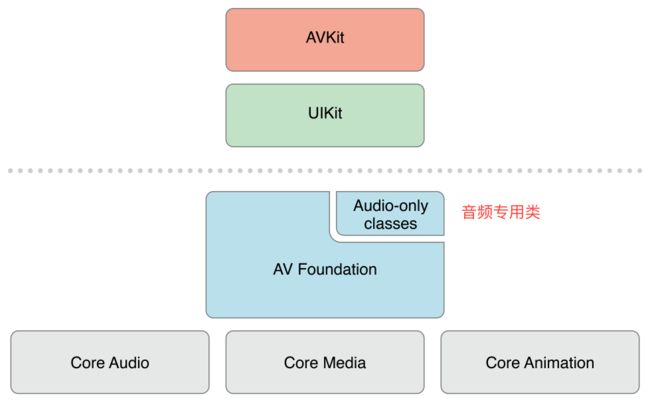
三.解析AVFoundation
音频播放和记录
媒体文件检查:提供检查正在使用的媒体功能,可以查看这些媒体资源来确定是否适合一些特定的任务。
视频播放:核心类是AVPlayer 和AVPlayerItem
媒体捕捉:核心类是AVCaptureSession
媒体编辑:可以将多个音频和视频资源进行组合的应用程序,允许修改和编辑独立的媒体片段,随时修改音频文件的参数以及添加动画标题和场景切换效果。
媒体处理:核心类是AVAssetReader和AVAssetWriter
四.了解数字媒体
1.数字媒体采样两种方式
时间采样:捕捉一个信号周期内的变化
空间采样:一般用在图片数字化和其他可视化媒体内容数字化的过程中。空间采样包含对一幅图片在一定分辨率之下捕捉其亮度和色度,进而创建由该图片的像素点数据所构成的数字化结果。当对一段视频进行数字化时,这两种方式都可以使用,因为通常的视频信号既有空间属性又有时间属性
开发者不需要很深的了解,设备硬件完成模拟信号到数字信号的转换
2.音频采样介绍
声波是通过一定介质传播过来的振动,低音符产生低且慢速的频率,高音符产生高且快速的频率,振幅用来测量频率的相对强度。当我们记录一个声音时,一般使用麦克风设备。麦克风是将机械能量(声波)转换成电能量(电压信号的转换设备)。信号的两个方面:第一是振幅,另一个是频率。振幅代表了电压的强度或者相应信号的强度,频率表示在一定周期内振动完成循环的次数。人类可以听到的音频范围是20Hz~20KHz(20000Hz)。
音频数字化的过程包含一个编码方法,称为线性脉冲编码调制,常见说法Linear PCM 或LPCM。这个过程采样或测量一个固定的音频信号,过程的周期律被称为采样率。
尼奎斯特频率用于生成足够好的数字呈现效果,该频率为需要采样对象的最高频率的两倍。
数字音频采样的另一个重要方面是我们能够捕捉到什么精度的音频样本,振幅在线性坐标系中进行测量,所以会有Linear PCM这个术语。用于保存样本值的字节数定义了在线性维度上可行的离散度,同时这个信息也被称为音频的位元深度。
视频文件由一系列称为“帧”的图片组成,在视频文件的时间轴线上每一帧都表示一个场景。视频文件一秒钟内所能展现的帧数称为视频的帧率,并用FPS作为单位进行测量,常见帧率24FPS、25FPS和30FPS。目前视频资源最流行的宽高比是16:9,意思是每16个水平像素对应9个垂直像素,在这一宽高比下最常见的视频尺寸是1280 *720 和1920 *1080。
五.数字媒体压缩
1.色彩二次抽样
视频数据是使用称之为Y'CbCr′ 颜色模式的典型案例,Y'CbCr′ 也称为YUV。Y'CbCr′ 或YUV则使用色彩(颜色)通道UV替换了像素的亮度通道Y(亮度)。(理解为色彩通道为UV,亮度通道为Y)
与RGB 类似,YUV 也是一种颜色编码方法,主要用于电视系统和模拟视频领域。Y 表示亮度,也就是灰度值,UV 表示色度,用于指定像素的颜色。图片所有细节都保存在 Y 通道中,如果除去 Y 信息,剩下的就是一幅灰度图片;如果除去 UV 信息,则变成黑白影像。因为我们的眼睛对亮度的敏感度要高于颜色,所以我们可以大幅减少存储在每个像素中的颜色信息,不至于图片的质量严重受损,这个减少颜色数据的过程就称为色彩二次抽样。
图片的所有细节都保存在亮度通道中,除去亮度,可以大幅减少存储在每个像素中的颜色信息,而不至于图片的质量严重受损。这个减少颜色数据的过程就称为色彩二次抽样。
设备所用的色彩二次抽样的参数一般为4:4:4、4:2:2及4:2:0,将亮度比例表示为色度值,这个格式写为J:a:b,具体含义如下:
J:几个关联色块(一般是四个)中所包含的像素数。
a:用来保存位于第一行中的每个J像素的色度像素个数
b:用来保存位于第二行中的每个J像素的附加像素个数
在4:4:4的比例下全彩色信息也都被保存下来。在4:2:2的情况下,色彩信息为每两个水平像素的平均值,即亮度和色度比率为2:1.在4:2:0的情况下,色彩信息为水平和垂直两个方向的4个像素的平均值,结果就是亮度和色度的比率为2:1。
色彩二次抽样一般发生在取样时,专业相机以4::4:4的参数捕捉图像,大部分情况对于图片的拍摄是使用4:2:2的方式进行的。面向消费者的通常以4:2:0的方式进行拍摄.
4:4:4
每一个 Y 对应一组 UV 分量
表示 UV 没有减少采样,即 Y、U、V 各占一个字节,加上 alpha 通道一个字节,共 4 字节,这个格式其实就是 24bpp 的 RGB 格式了。
4:2:2
每两个 Y 共用一组 UV 分量
表示 U、V 分量采样减半,比如第一个像素采样 YU,第二个像素采样 YV,以此类推。
4:2:0
每四个 Y 共用一组 UV 分量
这里的 0 意思是 U、V 分量隔行采样一次,比如第一行采样 4:2:0,第二行采样 4:0:2。
2.编解码器压缩
大部分音频和视频都是使用编解码器(codec)来压缩的,编解码器这个术语是由编码器/解码器结合简写得来的(encoder/decoder)。编解码器使用高级压缩算法对需要保存或发送的音频或视频数据进行压缩和编码,同时它还可以将压缩文件解码成适合播放和编辑的媒体资源文件。
编解码器既可以进行无损压缩也可以进行有损压缩,无损压缩编解码器以一种可以完美重构解码的方式对媒体文件进行压缩,使其成为无论编辑还是发布都比较理想的文件,有时也会作为归档文件用。如zip和gzip。
有损压缩就是在压缩过程中会有部分数据损失掉。但有损压缩的目的是使用psycho-acoustic或psycho-visual模式作为一种方法来减少媒体内容中的冗余数据,这样会使原文件的损耗达到最小。
3.视频编解码器
AV Foundation提供有限的编码器集合,主要可以归结为H.264和AppleProRes。
(1.)H.264与其他形式的MPEG压缩一样,通过以下两个维度缩小了视频文件的尺寸:
空间:压缩独立视频帧,被称为帧内压缩
时间:通过以组为单位的视频压缩冗余数据,这一过程称为帧间压缩。
帧内压缩通过消除包含在每个独立视频帧内的色彩及结构中的冗余信息来进行压缩,因此可在不降低图片质量的情况下尽可能缩小尺寸,这类压缩同JEPG压缩的原理类似。帧内压缩也可以作为有损压缩算法,但通常用于对原始图片的一部分进行处理以生成极高质量的照片,这一过程称为I-frames。
帧间压缩中,很多帧被组合在一起作为一组图片(简称GOP),对于GOP所存在的时间维度的冗余可以被消除。存储在GOP中的三个不同类型的帧。
I-frames:这些帧都是一些单独的帧或关键帧,包含创建完整图片需要的所有数据。每个GOP都正好有一个I-frames。由于它是一个独立帧,其尺寸是最大的,但也是解压最快的。
P-frames: P-frames又称为预测帧,是从基于最近I-frames或P-frames可预测的图片进行编码得到的。P-frames可以引用最近的预测P-frames或一组I-frames。
B-frames:又称为双向帧,是基于使用之前和之后的帧信息进行编码后得到的帧。几乎不需要存储空间,但其解压过程会耗费较长时间,因为它依赖于周围其他的帧
H.264还支持编码视图,用于确定在整个编码过程中所使用的算法。定义了三个高级标准
Baseline:通常用于对移动设备的媒体内容进行处理,提供了最低效的压缩,这个标准压缩后文件仍比较大,同时这种方法也是最少计算强度的,因为它不支持B-frames。适用于年代久远的iOS设别,如iPhone 3GS。
Main:这个标准的计算高度比Baseline高,因为它使用的算法多,可以达到更高的压缩率。
High:高标准的方法会得到最高质量的压缩效果。但它也是3种方法计算复杂度最高的。
(2). AppleProRes
AppleProRes被认为是一个中间件或中间层编解码器,因为它的目的是为专业编辑和生产工作流服务。AppleProRes编解码器是独立于帧的,以为着只有I-frames才可以使用,更适合用在内容编辑上。此外,AppleProRes还使用可变比特率编码的方式来对复杂场景中的每一帧进行编码。
ProPes是有损编解码器,但是它具有最高的编解码质量。AppleProRes422使用4:2:2的色彩二次抽样和10位的采样深度。AppleProRes4444使用4:4:4色彩二次抽样,具有最终4个用于表示支持无损alpha通道和高达12位的采样深度。
ProPes编解码器只在OS X上可用,对于iOS只能使用H.264。当我们捕捉图像的目的是对其进行编辑时,可以将目标变成通用的H.264格式,称为iFrame。对于编辑环境而言这是一个I-frame-only变量生成H.264视频更合适的一种方法。
4.音频编解码器
只要是Core Audio框架支持的音频编解码,AV Foundation 都可以支持,这意味着AV Foundation能够支持大量不同格式的资源。但是不用线性PCM音频的情况下,只能使用AAC。
AAC
高级音频编码(AAC)是H.264标准相应的音频处理方式,目前是音频流和下载的音频资源中最主流的编码方式。优点:这种格式比MP3有显著的提升,可以在低比特率的前提下提供高质量的音频,是在web上发布和传播的音频格式中最为理想的。此外,AAC没有来自证书和许可方面的限制。
注意:AV Foundation和Core Audio提供对MP3数据解码的支持,但是不支持对其进行编码。
六.容器格式
如.mov、.m4v、.mpg、.m4a。我们通常将这些类型都认为是文件格式,但其正确定义应该是这些类型都是文件的容器格式。容器格式被认为是元文件格式,可将容器格式视为包含一种或更多种媒体文件类型(以及描述其内容的元数据)的目录。