原文链接:https://blog.uwa4d.com/archives/1810.html
这是侑虎科技第249篇文章,感谢作者李旻辰供稿,欢迎转发分享,未经作者授权请勿转载。当然,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
本文原载于知乎专栏Graphicon(WonderList论文心愿单 - SIGGRAPH 2017 | CG中的深度学习)。同时,作者也是U Sparkle活动参与者哦,UWA欢迎更多开发朋友加入 U Sparkle开发者计划,这个舞台有你更精彩!
近年来,深度学习(deep learning)火了。作为一个强大的映射(mapping)构建工具,它席卷了计算机视觉(computer vision)、自然语言处理(natural language processing)等主要研究逆向问题(inverse problem)的计算机科研领域。其实,绝大多数计算机科研问题都着眼于找到一个适用于特定场景的从输入到输出的映射,比如:输入三维世界描述,输出渲染图;输入图片,输出文字描述;输入一句话,输出对这句话的应答;输入这几天股价的浮动,输出未来股价的走势等。但是,人类目前对以上列举的这些映射的认识是有所不同的。
“输入三维世界描述,输出渲染图”是一个典型的正向问题,即存在一套明确的建立这个映射所需遵循的规律,这些规律往往来自于人类千百年来在物理等基础科学中的研究成果。除此之外,剩下的几个问题都属于逆向问题,即并不存在一套明确的映射构建方式或规则,或者说这种规则很难形式化描述,人们只能够依据经验来枚举出所有的对应关系。这时,机器学习(machine learning)/统计学习(statistical learning)就彰显出了它巨大的价值。它是一些基于统计学的模型,在某些场景中可以通过人们枚举的有限的对应关系,自动“学习”出相应的映射。深度学习,则是其加强版,能将映射学习得更加准确,但计算量也大幅增加。
深度学习目前尚未席卷计算机图形学(computer graphics)科研领域,并不是因为我们的逆向问题不够多,而是还没有一个专为3D图形数据而设计的深度学习模型(就像专为图片设计的深度卷积神经网络CNN)。但就今年CG顶会SIGGRAPH刚刚公布的这些论文来看,这个格局似乎马上要被打破了。
Convolutional Neural Networks on Surfaces via Seamless Toric Covers[1] 在3D模型的表面定义了一种卷积运算(convolution),它可以理解成是把表示3D模型表面数据的mesh在2D平面上展开(parameterize)成图片,作为CNN的输入。值得一提的是,封闭的3D模型表面必须经过切割才能在2D平面上无重叠地展开,为了让原本在3D模型上相邻但由于切割而在展开的2D图片上分离的数据也能够一块经历同尺度的卷积运算,他们通过保角映射生成了原始模型的4块方形展开图(称为covers),并将切割处拼接起来形成最终的图片(实际上是一个torus的展开)。该方法能够应用到人体3D模型语义分割(human shape segmentation)以及解剖形体的对应问题(anatomic shape correspondence)上,并且准确度较前人方法有所提升。前几天恰逢Adobe CTL研究院的Vova[2] 大神(该论文作者之一)来UBC访问并讲座,笔者还和他探讨了为什么不把展开前后的deformation gradient也包含在展开的数据中的想法,同时也从他那里得知,目前很多团队都在尝试研究适用于深度学习框架的3D图形数据表示方法(representation),并被告诫入坑慎重。
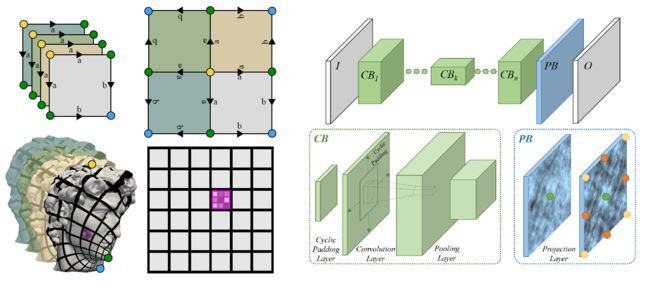
O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis[3] 就是又一个研究适用于深度学习框架的3D图形数据表示方法的工作。他们用空间八叉树(Octree)表示3D模型,并以叶节点处采样到的模型表面法向(normal)作为输入进行3D CNN操作。由于3D CNN操作只在模型表面所位于的叶节点处进行,O-CNN对即使是很精细的3D模型也同样适用。相较于前人的方法,其在3D模型分类(classification),检索(retrieval),以及语义分割(semantic segmentation)上都有所的进步。

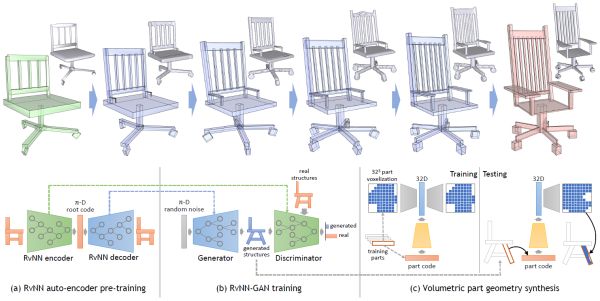
GRASS: Generative Recursive Autoencoders for Shape Structures[4] 将人造形体(man-made shapes,比如家具、建筑、交通工具等)的整体结构(global structure)与局部形状(local/part geometry)分开,利用基于递归神经网络(RvNN)的自动编码器(autoencoder)将整体结构编码成一个低维的特征向量(feature vector),并利用生成式对抗网络(GAN)的思想训练一个相应的解码器(decoder)从而组成了一个整体结构与特征向量间的双向转换器。加之一个根据整体结构生成局部形状的模块,一同拼接成了3D人造形体的一整套generative pipeline,在形体分类、局部匹配、形状生成(shape synthesis)、形状插值(shape interpolation)等问题上都有不俗的表现。
Data-Driven Synthesis of Smoke Flows with CNN-based Feature Descriptors[5] 利用CNN学习了一个描述粗糙尺度烟雾模拟局部和精细尺度烟雾模拟局部对应关系的映射,并且提前进行精细模拟和粗糙模拟生成了很多烟雾特效数据。这使得在新场景中生成精细的烟雾特效时,只需进行快速的粗糙模拟,并根据CNN构建的映射找出与各局部相对应的精细模拟局部,然后将其细节形体信息转移过来即可。这可不仅仅是节约了特效师制作特效的时间那么简单,如果粗糙模拟只是比精细模拟少了很多细节信息,那艺术家大可以利用粗糙模拟预览来设计整套特效,然后用选好的设定开始进行精细模拟,这并不会耽误工作时间。然而问题就在于,粗糙模拟和精细模拟所生成烟雾的整体结构会有所不同,之前设想的烟雾形状以及位置在精细模拟中可能会变,故这个方法根本就不可行。所以人们通常会发明一些算法来在保持粗糙烟雾整体结构的条件下增添局部细节,但其真实性一直是个问题。对此,这项工作利用深度学习给出了另一种思路。

以上的前三项工作都是在尝试为3D图形数据寻找适用于深度学习的表达方式,从而使它们能够被输入到深度学习框架中去学习出更为简练的特征向量,并应用于3D模型的识别、感知与生成等难以直接建模求解的问题。第四项生成烟雾细节的工作略有不同,它并不是说求解物理方程无法生成足够精细的烟雾特效,而是那样计算功耗太大,深度学习在这里充当了催化剂的角色,这也是另一种应用深度学习的思路。
除了针对3D形体数据的深度学习之外,本届SIGGRAPH已发布的论文中还有用深度强化学习(deep reinforcement learning)来控制角色在复杂3D地形中行走的DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning[6] 、用深度学习将用户画的人脸简笔草图(sketch)映射到对应3D人脸模型的DeepSketch2Face: A Deep Learning Based Sketching System for 3D Face and Caricature Modeling[7] 、用CNN将多张LDR图片合成HDR图片的Deep High Dynamic Range Imaging of Dynamic Scenes[8] 、用CNN将低速光场相机(light field camera)和高速普通相机结合成高速光场相机的Light Field Video Capture Using a Learning-Based Hybrid Imaging System[9]、用CNN基于纹理块(patch)生成有结构的纹理图(texture)的Deep Correlations for Texture synthesis[10]、以及用CNN基于少量用户输入来将灰度图转化为彩图的Real-Time User-Guided Image Colorization with Learned Deep Priors[11]、用CNN训练一个能在移动设备上运行的低功耗修图工具的Deep Bilateral Learning for Real-Time Image Enhancement[12]等,这里就不一一展开了。

加上笔者之前总结过的一些机器学习在计算机图形学研究中的应用[13]以及@Raymond的一些总结[14],可见(深度)机器学习这套框架在CG领域也逐渐蔓延开来了。
最后我也想说,入坑慎重。因为目前深度学习领域的研究及应用还是很靠经验和灵性,毕竟大家都还不太清楚它的性能为什么这么好,也没有一套完整的理论能够对其进行描述与分析。其实笔者也不打算深入研究这个领域,就是跟随深度学习先驱们了解他们最新的进展,想着哪天时机成熟了,可以直接用现成的。对,想得很美。
文末,再次感谢李旻辰的分享,原文所属知乎专栏:https://zhuanlan.zhihu.com/graphicon
如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)。
也欢迎大家来积极参与U Sparkle开发者计划,简称"US",代表你和我,代表UWA和开发者在一起!