| 项目 | 内容 |
|---|---|
| 班级:北航2020春软件工程 006班(罗杰、任健 周五) | 博客园班级博客 |
| 作业:设计程序求几何对象的交点集合,支持命令行和GUI | 结对项目作业 |
| 个人课程目标 | 系统学习软件工程,训练软件开发能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 实践结对编程等敏捷开发方法 |
| 项目地址 | GitHub: clone/https |
| 软件可执行文件下载(命令行程序和GUI程序) | GitHub: Release |
本作业涉及到的小组及其成员:
| 学号 | CnblogProfile | GitHubRepo |
|---|---|---|
| 17231145 * (本文作者) | @FuturexGO | *Repo |
| 17373331 * (结对伙伴) | @MisTariano | |
| 17231162 † (另一小组) | @PX_L | †Repo |
| 17373321 † (另一小组) | @youzn99 |
目录
标题中带有*号的章节均为和结对伙伴的共享博客内容。
- 目录
- 个人部分PSP与反思
- 设计思想
- Information Hiding
- Loose Coupling
- Code Contract
- 接口的设计与实现*
- C风格 私有接口:封装核心功能
- C风格 公有接口:实现数据隐藏、松耦合
- 核心模块内的设计——UML阐释
- 性能评估与改进*
- 计算交点部分的优化
- 维护去重HashSet部分的优化
- 代码质量分析*
- 单元测试*
- 异常处理*
- GUI模块的具体设计*
- GUI与核心模块的对接*
- 松耦合展示*
- 命令行程序接入两个版本的核心模块
- GUI程序接入两个版本的核心模块
- 结对过程*
- 反思结对编程
个人部分PSP与反思
在开始实现程序之前,在下述PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
在你实现完程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。
| PSP2.1 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning | 30 | 20 |
| · Estimate | 30 | 20 |
| Development | 970 | 1050 |
| · Analysis | 90 | 120 |
| · Design Spec | 60 | 30 |
| · Design Review | 30 | 20 |
| · Coding Standard | 10 | 50 (制定公有接口标准) |
| · Design | 120 | 60 |
| · Coding | 300 | 280 |
| · Code Review | 60 | 120 |
| · Test | 300 | 420 |
| Reporting | 50 | 90 |
| · Test Report | 20 | 50 |
| · Size Measurement | 10 | 10 |
| · Postmortem & Process Improvement Plan | 20 | 30 |
| In Total | 1050 | 1200 |
本次作业的个人部分完成时间仍然超出了自己的预期,其主要原因是:
-
本次计算模块继承自上次个人作业。然而在之前的设计中,我没有考虑到有理数类的分子在约分前可能高达
1e20而不是1e10。其本质是我对于数据范围和极端情况的考虑不充分,没有想到事实上的最极端情况,导致对中间数据范围估计不足。这样,之前实现的分子分母都为long long的有理数类在参数范围(-1e5,1e5)的情况下就是错误的。因此在结对项目中,我花了一个小时左右进行了重构和重新单元测试。 -
新功能的实现和测试较为复杂。对于支持射线/线段的新功能,我们的解决方案是:
-
判断合法性。其子问题为:
-
判断所在直线的非平行、平行与共线。非平行与平行(共线)的判定标准为交点分母是否为0,即交点是否为无穷数。平行与共线的区分可以通过计算“对角向量”的叉积,判断“对角向量”是否共线实现。如下图所示,两个绿色的向量即为“对角向量”。当两个对角向量的叉积为0时说明对角向量平行,两平行直线必共线。
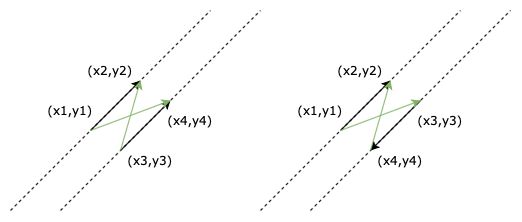
-
判断所在直线共线的几何对象的重合情况。显然如果两个对象之一为直线则必产生无穷多交点。其余情况有:射线-射线、射线-线段、线段-线段三种情况。我们首先讨论了射线-射线的情况,再将后面射线-线段、线段-线段的情况转化为若干个射线-射线的并:
if (a.type == LINE || b.type == LINE) { return false; } else if (a.type == HALF_LINE && b.type == HALF_LINE) { bool res = _checkHalfLineOverlap(x1, y1, x2, y2, x3, y3, x4, y4); return res; } else if (a.type == SEGMENT_LINE && b.type == SEGMENT_LINE) { bool res = _checkHalfLineOverlap(x1, y1, x2, y2, x3, y3, x4, y4) || _checkHalfLineOverlap(x2, y2, x1, y1, x3, y3, x4, y4) || _checkHalfLineOverlap(x1, y1, x2, y2, x4, y4, x3, y3) || _checkHalfLineOverlap(x2, y2, x1, y1, x4, y4, x3, y3); return res; } else if (a.type == SEGMENT_LINE && b.type == HALF_LINE) { bool res = _checkHalfLineOverlap(x1, y1, x2, y2, x3, y3, x4, y4) || _checkHalfLineOverlap(x2, y2, x1, y1, x3, y3, x4, y4); return res; } else if (a.type == HALF_LINE && b.type == SEGMENT_LINE) { bool res = _checkHalfLineOverlap(x1, y1, x2, y2, x3, y3, x4, y4) || _checkHalfLineOverlap(x1, y1, x2, y2, x4, y4, x3, y3); return res; }
-
-
求交点。先按直线进行计算,计算后检查交点是否在直线的有效范围内。判断是否在有效范围内主要通过构造向量进行点积,判断两个向量是否同向实现。
-
-
使用浮点数
double类型的精度问题难以解决。注意到double的有效数字只有15~16位(由于机器epsilonstd::numeric_limits约为::epsilon 2e-16),然而需要比较大小(小于、等于、大于)的数值可能高达1e10,因此在比较任意两个浮点数时不应采用相同的eps。另外,在计算中每步发生的误差(约为机器epsilon与数值的乘积)会进行积累和传播,导致最终数值的误差难以估计。这就导致难以找到一个合理的比较方法,只能 “不断调整比较函数-测试-确认bug-再调整比较函数算法 ” 来找到一个合理的eps取值组合。 -
为了进一步保证正确性,简单实现了一个对拍器。在和其他同学对拍测试中,由于精度问题等经常出现答案相差\(\pm 1\)的情况。对于随机生成的大规模数据,难以知道正确答案,只能写额外代码将两程序的交点坐标打印出来再排序,找出差异的那一个点对应的两个图形,再进行数学计算验证正确性。
因此吸取到的主要教训有:
- 如果用户对精度有严格要求(如本次的交点去重),应当实现精确的有理数、无理数、大数类等,或者不使用C++语言而使用Java等有较好数据结构支持的语言。
- 应当对计算中可能出现的问题(溢出、符号、精度丢失)等了然于胸,且对潜在的危险保持警惕,应当进行分析和计算确认其安全性,并在代码中做出标记。
- 在具体设计和编码前应当分析地更细致。设计应当有层次,重点当然不应该是“当前编程语言能不能做到”,而是“如何才能设计出合理的接口/简单地完成功能/具有可拓展性……”,但是涉及到语言实现的可行性和易操作性的内容也应当被在之后考虑。
设计思想
看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。
看 Design by Contract,Code Contract 的内容,描述这些做法的优缺点,说明你是如何把它们融入结对作业中的。
Information Hiding
Information Hiding是一个重要的程序设计思想,旨在将不同模块的程序内部数据尽可能向外界隐藏,只在定义良好的接口处向外界展示必要的数据和函数entry。这样做的目的是避免某一部分的程序由于有意的越权访问(如程序员主动访问)或无意的意外更改(如写出bug意外拿取了指针进行更改)导致外界引发内部错误。
在我们的接口设计中,我们一开始设计的接口(即下文所述的私有接口customInterface)就不具备这样的特性。我们可以通过直接返回给用户的gManager对象看出这一缺陷:
// interface.h
struct gManager {
vector *shapes; // storing CORE data !!!
unordered_set *points; // storing CORE data !!!
gPoint upperleft;
gPoint lowerright;
};
gManager *createManager();
用户使用时:
// User
gManager *mng = createManager();
调用createManager()创建一个新的图形交点管理器,就直接拿到了其指针gManager *mng。这样设计固然简单、直观,但用户可以直接通过mng->shapes直接更改管理器中存放已有图形的记忆!这违反了Information Hiding的原则。
于是在制定下一代接口(即下文所述的公有接口StdInterface)时,我们两个小组避免了对任何核心数据的直接/间接暴露:
// StdInterface.h
struct gFigure {
unsigned int managerId;
// they are SAFE to be exposed to user !!!
gShape *shapes; // gShape[], NOT core data vector
gPoint *points; // gPoint[], NOT core data set
gPoint upperleft;
gPoint lowerright;
};
gFigure *addFigure();
// StdInterface.cpp
vector managers; // index -> managerId
可以看到,直接向用户返回的gFigure中不包含指向gManager的指针,且其中的信息并不是真正计算模块用来存储核心数据的容器,而是拷贝给用户的数据。真正的核心数据(vector和unordered_set)仍然在gManager中。
而gFigure无法从用户处(模块外部)索引到gManager,只有在模块内部才能通过managers[managerId]索引到对象。因此这种设计做到了暴露给外部的信息可控,只有gFigure中的五个成员。
Loose Coupling
Loose Coupling是系统设计中的一个重要概念,它强调了组件的独立性。引用 维基百科 的话就是说:
松耦合系统中的组件能够被提供相同服务的替代实现所替换。
松耦合系统中的组件不太受相同的平台、语言、操作系统或构建环境的约束。
因此,我们希望在接口设计中,所有涉及到的符号、对象和函数仅限本层使用(见下节 具体设计与实现 中的图):用户在使用最外层的公有接口时不需要知道任何关于私有接口和基础计算层的信息;用户在使用私有接口时,不应知道任何基础计算层的信息。
因此,我们在接口设计中提供了从计算层的核心数据到外层接口数据的转换。以用户想获取所有交点的坐标为例,我们设计了这样的一系列调用链:
// StdInterface.cpp
void updatePoints(gFigure *fig) {
auto mng = gManagers[fig->figureId];
... // clean up fig->points[]
getIntersections(mng, fig->points); // fig->points[] = copy from customInterface
}
// interface.h
void getIntersections(gManager *inst, gPoint *buf); // buf[] = copy from CORE data
可以看出,其实私有接口的函数getIntersections向外输出的结果gPoint buf[]其实就已经做到了对内部类型Point和unordered_set的隐藏。如果不考虑上一节所示的gManager的定义问题,单看本函数可以说基本做到了松耦合。然而上一节提到了gManager的定义:
// interface.h
struct gManager {
std::vector *shapes;
std::unordered_set *points;
gPoint upperleft;
gPoint lowerright;
};
却直接把拷贝了半天的核心数据unordered_set直接暴露出来了!这也是我们为什么要设计公共接口的原因:
观察下节 具体设计与实现 中的图。事实上:
- 将第二层的customInterface和第三层C++ Base换掉,第一层不变,程序仍然能正常工作。
- 但无法将第三层换掉,因为第三层和第二层之间存在耦合(
Point、Geometry等)。
Code Contract
契约式设计是一种保障代码(尤其是调用和撰写接口)质量的手段,其思想是使用某种特殊的语言(如Java的JML,Java Modeling Language)对接口函数的行为和约束(前置条件、后置条件、不变式等)进行建模和描述,并在编码后对代码进行静态检查、运行时检查等。
契约式设计能够规定某函数运行前各参数所满足的条件、运行后输出参数和返回值应满足的条件、成员变量和全局变量发生变化的约束等检查,从而辅助程序员严格按照接口文档写出程序。
然而这样做有优点也有缺点。优点主要有:
- 拓展了assert、try-catch等程序员的手动异常处理,到强制约束和自动检查的范畴。
- 能够迫使程序员在写代码前撰写详细的规格文档,帮助程序员思考所有可能发生的情况。
- 理想中能够利用形式逻辑静态判断代码的覆盖率,能够在运行时也能提前抛出异常。
然而契约式设计还是没用被广泛应用,可能与我们认为的以下缺点有关:
- 相关工具的表现和理想情况的能力相差甚远。这一点我们在北航2019年的面向对象课程中深有体会。
- 需要额外撰写大量建模语言代码,且无法自动生成。撰写前置条件、后置条件、不变式的编程代码量和思维代码量都较大,甚至撰写一个简单的函数都需要数倍于代码本身长度的建模语言。
- 虽然检查可以很严苛,但对质量的保证效率较低,投入产出比不如单元测试。
而在本次作业中,由于上述的我们认为的缺点,我们并没有使用Code Contract的风格与模式。但在设计公有接口时,我们本应和另一组合作撰写一份自然语言的接口规格文档,用自然语言和伪代码的形式规定前置条件、后置条件和函数行为规范。但很遗憾本次作业中由于时间关系未能完成,希望在团队作业中可以用这样的形式规范接口与代码。
例如在我们的私有接口中有着如下的trick:
ERROR_INFO addShapesBatch(gManager *inst, FILE *inputFile, gPoint *buf, int *posBuf);
其中的FILE *inputFile是一个nullable的文件指针,当指针为nullptr时表明从标准输入批量添加图形,但指针不为nullptr时表明从文件输入批量添加图形。然而这样的行为约定难以被规范地写出来告诉程序员,如果使用契约式设计,加入类似JML语言的表达式,虽然不一定要使用其运行时检查功能,但也清晰地能告诉程序员接口的约定。
但从整体的代价来考虑,其实契约式设计投入产出比并不高,完全可以撰写以下的参数文档(由IDE自动生成,手动填写说明):
/**
*
* @param inst
* @param inputFile nullable. if null, read from stdin.
* @param buf
* @param posBuf
* @return
*/
ERROR_INFO addShapesBatch(gManager *inst, FILE *inputFile, gPoint *buf, int *posBuf);
这样也可以起到一定的“契约”的作用。
接口的设计与实现*
计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
我们一开始按照自己的接口设计(私有接口,或customInterface)对核心模块进行了封装。
但之后为了验证松耦合,各个团队的自己的私有接口都已经实现且各不相同。由于大家都不愿意重构自己的私有接口和单元测试,我们需要与其他团队共同制定一个新标准(公有接口,StdInterface)。公有接口是对私有接口的进一步封装,两个团队的私有接口有着天壤之别但公有接口完全一致。
我们与另一组的同学@PX_L共同设计了公有接口的新标准。这样我们都以公有标准的接口导出DLL可以方便地验证GUI、命令行、测试模块与核心模块的松耦合,之前各自已经完成的私有接口也无需重构,只需在私有接口的基础上加壳即可。我们设计的公有接口StdInterface的主要特点为:
- 考虑到我们希望接口能具有较强的兼容性,我们使用C风格接口,不使用C++的面向对象、STL等特性。这样今后稍微改动就可以被C、C++、Python等各种语言调用。
- 动态内存管理由接口内部实现,外部调用者无需直接操作指针。
- 数据被良好封装,外部调用者无法更改和直接访问数据,也无法知道数据的地址。
- 支持多例,即支持一个GUI程序中开多画布,每个画布数据独立。
用图可以阐释如下(为了理解方便,可能与代码有出入,如变量名等):
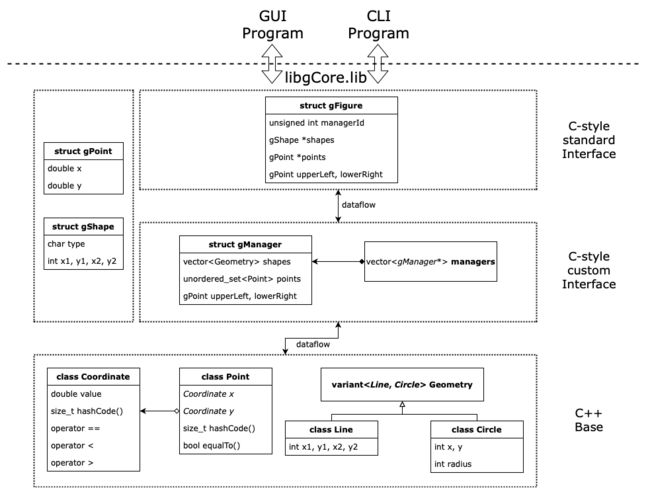
其中StdInterface的接口部分与另一小组完全相同。customInterface及其以下部分两小组完全不同。
C风格 私有接口:封装核心功能
我们首先将计算类的基本操作进行了简单封装。代码请见src/interface.h:
#ifndef GEOMETRY_INTERFACE_H
#define GEOMETRY_INTERFACE_H
#include
#include "Shapes.h"
#include "StdInterface.h"
// 数据管理实例类
struct gManager {
std::vector *shapes;
std::unordered_set *points;
gPoint upperleft;
gPoint lowerright;
};
// 初始一个数据管理实例
gManager *createManager();
// 关闭实例,释放其占用的内存资源
void closeManager(gManager *inst);
// 清空实例中当前缓存的所有形状和交点
void cleanManager(gManager *inst);
// 向实例中添加形状
ERROR_INFO addShape(gManager *inst, char objType, int x1, int y1, int x2, int y2,
gPoint *buf, int *posBuf);
// 根据文件输入向实例中批量添加形状
ERROR_INFO addShapesBatch(gManager *inst, FILE *inputFile, gPoint *buf, int *posBuf);
// 获得当前交点总数
int getIntersectionsCount(gManager *inst);
// 获得当前实例中交点综述
int getGeometricShapesCount(gManager *inst);
// 获得当前所有交点,写入buf为首地址的连续内存中
void getIntersections(gManager *inst, gPoint *buf);
// 获得当前所有图形,写入buf为首地址的连续内存中
void getGeometricShapes(gManager *inst, gShape *buf);
#endif //GEOMETRY_INTERFACE_H
注意到这套接口提供了一个数据管理器gManager,允许外部程序创建、持有计算中需要持久化的数据区并控制内存释放时机,这样所有的计算操作都不需要再维护全局缓存数据,这使所有接口都是无状态的,更易于解耦与使用。
这套封装已经已经足以覆盖对交点计算库的使用需求,但注意到两个问题:
- 由于追求泛用性使用C风格接口,以结构体的方式给出的
gManager中类型为Geometry的数据是可以被直接访问到的,而这个类型实际上是std::variant(在src/Shapes.h中定义),用户的程序可以以我们不希望的方式添加对这个类型数据的操作,产生对这个类的耦合。一旦其他实现中没有提供这个类型,就不可能在不修改用户代码并重新编译的前提下将用户程序迁移至新的计算库实现。因此,这里并没有满足信息隐藏的原则,且难以实现松耦合。 - 由于接口中用到了
Shapes.h定义的结构,Shapes.h被引入了用户项目,对用户不透明。因此用户不仅可以调用interface.h中声明的接口函数,还可以调用Shapes.h中声明的各种计算操作——这也是不满足信息隐藏原则的。实际上这还会导致Point.h的引用——用户程序在编译时必须同时包含这三个头文件,提供的动态库也必须完整实现这三个头文件中声明的函数,这使得程序借助松耦合取得的修改与扩展空间变得极小。
因此为了实现松耦合,我们在与另一组协商后设计了下述公有接口标准,对这些接口的引用关系与数据定义进行了集中整理。
C风格 公有接口:实现数据隐藏、松耦合
我们的公有接口标准保留了C风格接口和无状态两个设计点,在单个头文件中给出了用户程序需要关注与使用的全部数据结构定义与函数声明。请见src/StdInterface.h:
// 错误代码枚举
enum ERROR_CODE {
SUCCESS,
WRONG_FORMAT,
VALUE_OUT_OF_RANGE,
INVALID_LINE, INVALID_CIRCLE,
LINE_OVERLAP, CIRCLE_OVERLAP,
};
// 运行状态与错误信息封装
struct ERROR_INFO {
ERROR_CODE code = SUCCESS;
int lineNoStartedWithZero = -1;
char messages[50] = "";
};
// 形状结构
struct gShape {
char type;
int x1, y1, x2, y2;
};
// 交点结构
struct gPoint {
double x;
double y;
};
// 画布结构,类似私有接口中的gManager,为用户程序提供数据管理
struct gFigure {
unsigned int figureId;
gShape *shapes; // only available after updateShapes()
gPoint *points; // only available after updatePoints()
gPoint upperleft;
gPoint lowerright;
};
// 创建画布
gFigure *addFigure();
// 释放画布资源
void deleteFigure(gFigure *fig);
// 清空画布中的形状与交点
void cleanFigure(gFigure *fig);
// 将形状添加至画布
ERROR_INFO addShapeToFigure(gFigure *fig, gShape obj);
// 将字符串desc中描述的形状添加至画布
ERROR_INFO addShapeToFigureString(gFigure *fig, const char *desc);
// 读取文件名为filename的文件并将其描述的图形批量导入画布
ERROR_INFO addShapesToFigureFile(gFigure *fig, const char *filename);
// 从标准输入流中读取形状并加入画布
ERROR_INFO addShapesToFigureStdin(gFigure *fig);
// 根据给定的形状索引移除形状
void removeShapeByIndex(gFigure *fig, unsigned int index);
// 获取交点总数
int getPointsCount(const gFigure *fig);
// 获取形状总数
int getShapesCount(const gFigure *fig);
// 将修改形状数据后新的交点数据同步到给定画布数据区points字段中
void updatePoints(gFigure *fig);
// 将修改形状数据后新的形状数据同步到给定画布数据区shapes字段中
void updateShapes(gFigure *fig);
不难发现这份接口涵盖的功能是上文中私有接口的超集。同时注意到在私有接口中存在的数据隐藏等问题,在这份接口定义中已经不存在了。
因此用户程序在编译时只需要包含这份头文件,就可以加载任何实现了这套接口的动态库并正常运行。
我们的松耦合实验便基于此接口完成。具体流程是:在完成标准制定后,参与的两组先协作完成这份头文件的编写,再分别将自己的私有接口组合以实现公有接口函数,最终分别编译动态库并进行互换实验。
核心模块内的设计——UML阐释
画出 UML 图显示计算模块部分各个实体之间的关系。
在中间层的customInterface和最外层的StdInterface中,由于我们采用了C风格的接口,且不希望用户显式地创建、删除对象实体,因此均为面向过程的设计,没有具体的实体,这里不放出严格意义的UML图(不规范的UML图可以见上节图),具体设计可以参考代码 interface.h 和 StdInterface.h。
在最内部C++风格的基础计算层中,我们使用Coordinate类来维护浮点坐标、使用Point类来维护由两个坐标组成的交点。为了使用STL的unordered_set,我们创建了两个用于重载运算符的辅助struct。同时,我们使用Line和Circle类来存储各个图形。
由于继承自上次作业,且二元的基于多态的函数难以写成接口,于是我们仍然采用了std::variant的写法来实现基类的效果,但不设置基类。同时由于配套的std::visit的特殊要求,我们没有将三种直线/射线/线段单独设计成类并使用继承和重写。我们在Line类中记录了线的种类,并在实现的判断点是否在线上的方法中分情况处理。
一个粗略的UML图如下:

图中详细展示了坐标&点与几何对象两个系统内部的实体关系和两个系统之间的联系。
variant不是基类但在逻辑层面上可以看成是由Line和Circle继承的基类。- 求交点的
struct intersect对一个(Shape1 &lhs, Shape2 &rhs)进行求交点运算,并将结果构造后(为简洁性,UML中未画出)写进unordered_set中。 - 容器使用
struct equals_Point, hashCode_point进行哈希和判等,维护了Point集合。 Point由两个Coordinate组成。
性能评估与改进*
记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图,并展示你程序中消耗最大的函数。
性能评估与改进的工作主要由 @FuturexGO 完成,约用时3h。
由于我们继承了个人作业的思路,使用std::unordered_set<>进行去重,因此值得关注的问题是:
- 花在计算交点上的时间多,还是花在去重交点上的时间多?
- 如何分别优化两部分?
计算交点部分的优化
于是,在最初的版本,我们基于一个随机生成的样例对程序进行Profile,结果如下:

可以看出在该版本下,计算部分占用了30.6%的总时长,维护HashSet部分占用了13.2%+5.9%等时间,最后delete一个大数据结构占用了20.4%的时长。
对于我们的设计,一个通常的函数调用路径可以看成(为了介绍简便进行了再加工):
1. std::vector intersection(Shape1 &x, Shape2 &y);
<--> (std::visit 解析std::variant 和 Template Shape1&Shape2)
2. std::vector intersection(Line &x, Line &y);
<--> (进一步的逻辑)
3. bool checkPointLine(Line &l, Point &p);
bool checkPointHalfline(Line &l, Point &p);
bool checkPointSegment(Line &l, Point &p);
bool checkHalflineOverlap(Line &x, Line &y);
...
展开函数调用树(此处未展示)我们发现,计算最密集的第三层(使用点积、叉积等计算几何方法检查点是否在给定范围上、检查是否重叠导致无穷多交点等)花费的时间并不占第一层的子树下的绝对多数(\(<70\%\))。
于是我们想到,既然两个图形的交点至多为2个,其实并没有必要使用std::vector<>作为返回值。并且上述的一些被频繁调用的子逻辑函数可以内联。
进一步,我们的思路为:
-
避免拷贝。使用引用或指针将容器传进参数里,作为“输出参数”。但是
std::visit(visitor{}, arg1, arg2,...)所要求函数的参数必须都是std::variant类型,不支持其它类型,因此此处不适用。 -
合理内联。上述的几个bool函数可以内联,以减少反复更改调用栈的开销。
-
减少使用大规模的STL容器,用灵活的小STL替换。此处使用
std::vector<>实在没有必要。并且在之后的更新中我们加入了判断两个图形相交是否合法(是否产生无穷多交点异常)的逻辑,因此需要将返回值除了交点外添加一个bool值。于是,我们使用了灵活的std::tuple<>将其重构成:typedef std::tuple其中第一个位置bool表示相交的合法性,第二个位置int表示有几个交点,第三第四个位置表示交点。如果只有一个交点,则第四个位置的变量无意义;如果没有交点,则两个Point对象均无意义。
于是改进后,我们对同一组数据进行Profile,得到结果:

可以看出,保持closeManager()函数没变,其占用率从之前的20.4%上升到了24.6%,说明整个程序主体部分的运行时间减少了\(1-20.4\%/24.6\%=17\%\),是一个很大的提升(我们管这个叫“delete测速法” )。
同时可以看出,现在计算部分的时间占用只是主体部分的1/3了,其中std::ordered_set::insert维护哈希表占的时间是计算部分的两倍!
维护去重HashSet部分的优化
为了方便对比,让我们先去除closeManager()部分(delete了几个大容器):
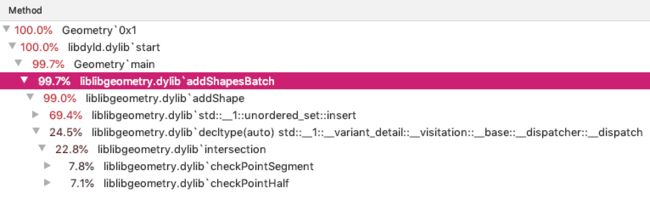
可以看出,在某些数据上,维护集合的开销占到了70%!于是,我们在重写的hash函数和equals函数中加入计数,统计两个函数分别被调用的次数,发现:
对于最终unique点为28,527,681个的数据,hashCode()被调用了28,527,710次左右,这意味着重复的点只有0.0001%!对于这样的数据,hashset花了接近30秒去重了30个数据?并不是,我们发现std::unordered_map::rehash()方法占用了一定的时间,同时重载的equals()被调用了超过60,000,000次!
我们通过查找资料和猜想,产生了如下思路:
- hashset/hashmap内部是由若干个buckets(桶)组成。每当数据占满了总bucket数的
max_load_factor比率,就会进行rehash()操作进行扩容。 - 在扩容中会重新排布数据点,可能发生迭代、冲突和判等。
- 因此,既然我们已知总图形数,我们可以根据图形数估算总交点数,并提前rehash,开出空间留出适当的buckets数,使hashset在运行过程中尽可能少扩容。
因此我们在批量输入模式(如命令行调用、标准输入、GUI打开文件导入)下,一旦输入了图形数objCount,就进行如下操作:
points_set->rehash(int(objCount * objCount / 2.0 / 0.75) + 1);
该语句的策略是,假设objCount个图形会产生约C(objCount, 2)数量级的交点数。同时,我们希望能有75%左右的桶子占用率(这是个magic number,也有人使用70%,可能是经验值)。
经过上述优化,再次进行Profile的结果为:
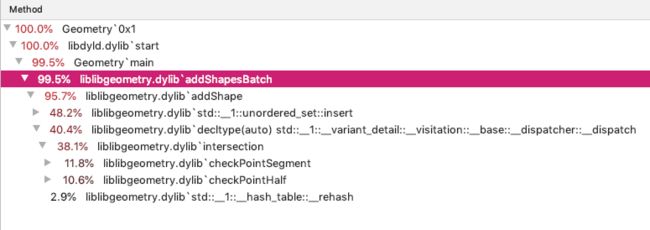
可以看出,在计算部分没有变化的条件下,insert部分占用率从69.4%下降到了48.2%。事实上的总运行时间也缩短了5~10s。因此优化是绝对有效的。然而整个程序的主要时间开销还是花在了unordered_set上:
它确实是\(O(1)\)的。最终的总复杂度为\(O(n^2)\cdot O(1)=O(n^2)\)的。
但经常它比先加到顺序容器里、再排序、再去重的\(O(n^2\log n^2) = O(n^2\log n)\)还慢,慢得多。
以下是具体的最终版本的性能实验数据(Apple Clang++,Release版本,文件读入标准输出,随机数据):
| N | 实际运行时间(s) |
|---|---|
| 2500 | 0.90 |
| 5000 | 3.73 |
| 10000 | 15.65 |
| 20000 | >60 |
代码质量分析*
第一次运行分析时警告信息较多,主要问题是使用了不安全的函数和宽窄类型间隐式转换存在溢出风险:
(这里由于终端编码集设定问题显示乱码,但由于定位到代码后弹出的气泡框动态提示没有乱码因此不影响理解)
针对这些问题做了如下修改:
- 使用带有失败标记及溢出检查的安全函数替换不安全的函数。这里需要说明的是,对于vs建议使用的
fopen_s等函数,由于其不是标准C++实现,考虑到兼容性我们最终没有采用,通过显式添加编译头#define _CRT_SECURE_NO_WARNINGS关闭这些警告。 - 为计算过程添加显式类型转换。如在计算中将整形先转换为64位长整型再进行乘法运算。
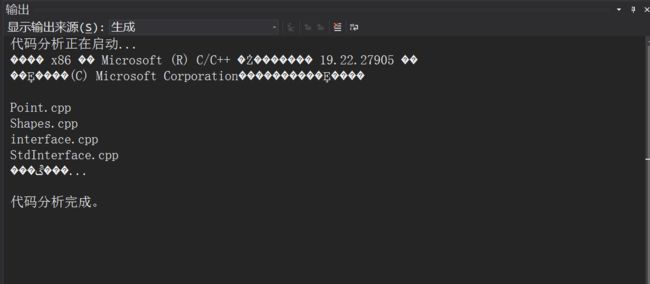
全部修改后再次运行代码质量分析,不再报错误和警告:
单元测试*
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。要求总体覆盖率到 90% 以上。
单元测试工作由 @FuturexGO 和 @MisTariano 共同贡献完成。
由于VS自有的单元测试并不通用,我们仍然选择了全平台支持、跨IDE支持的通用测试框架 GoogleTest,并将其集成到了各自prefer的IDE中。
由于本次作业中的基础数据结构有理数类被取消和重构,因此我们对Shapes.h和Point.h中涉及到的函数和数据结构分别重构了单元测试。之后,我们又对核心模块接口interface.h中的接口和异常分别构造了单元测试。四组单元测试取并集的总覆盖率如下图所示(interface.h未显示覆盖情况是因为其函数全部在对应的.cpp文件中,自己并没有单独的函数实现):

具体的测试代码可见 GitHubRepo/test。这里选取其中一个测试直线/射线/线段共线情况的 例子 进行解读:
待测试的函数为:
typedef std::tuple point_container_t;
point_container_t intersection(const Shape1 &a, const Shape2 &b);
返回的(待测试的)信息为:是否触发无穷交点异常、有几个交点、交点坐标。这里我们的侧重点是前两个返回信息的正确性,后面坐标的正确性由其他的测试来保证。
-
首先将直线/射线/线段都看作是线段。这样两条共线线段的重叠情况有(两条线段的位置可互换是显然的,这里不再赘述):
- “相离”。两条线段不共点。
- ”相切“。两条线段共用一个点。
- ”相交“。两条线段有无穷多个公共点。假设一条线长一条线段短,则还有这些情况:
- 部分重叠;
- 短“内含”于长,左对齐;
- 短“内含”于长,右对齐;
- 长短相同,二者完全重叠。
因此体现在我们的代码中,我们对这些线段-线段的位置重合关系组合进行了生成:
case_input_list_t getCases(const std::string &overlapType, const std::string &directionType) { // case 0: -------- ......... (divide) // case 1: --------........ (cat) // case 2: ------.-.-.-...... (overlap) case_input_list_t cases; if (overlapType == "divide") { pushCaseByDirection(cases, directionType, 1, 1, 2, 2, 3, 3, 4, 4); ... // 不同参数数量级的其他 meta-case,如参数小至-1e5,如参数大至1e5等 } else if (overlapType == "cat") { pushCaseByDirection(cases, directionType, 1, 1, 2, 2, 2, 2, 3, 3); ... // 每个case是上面meta-case的交换与变换 } else { //if (overlapType == "overlap") // normal case -----.-.-.-..... pushCaseByDirection(cases, directionType, 1, 1, 3, 3, 2, 2, 4, 4); ... // left aligned -.-.-.-.-.------ pushCaseByDirection(cases, directionType, 1, 1, 3, 3, 1, 1, 4, 4); ... // right aligned ------.-.-.-.-.- pushCaseByDirection(cases, directionType, 1, 1, 4, 4, 2, 2, 4, 4); ... // complete overlap -.-.-.-.-.-.-.-. pushCaseByDirection(cases, directionType, 1, 1, 4, 4, 1, 1, 4, 4); ... } return cases; }其中每个
pushCaseByDirection()又对下面的情况进行了组合考虑: -
接着把上面所说的线段看成向量。这样两个共线向量的方向组合情况有:
- 同向,向x增加
- 同向,向x减小
- 异向,相向
- 异向,向背
因此对于上述调用的每次
pushCaseByDirection(),我们都进行向量-向量方向关系级别的再组合:void pushCaseByDirection(case_input_list_t &container, const std::string &directionType, int x1, int y1, int x2, int y2, int x3, int y3, int x4, int y4) { // - sub case 00: -------> ........> (right) // - sub case 01: <------- <........ (left) // - sub case 02: -------> <........ (face) // - sub case 03: <------- ........> (back) if (directionType == "right") { container.push_back(case_input_t{x1, y1, x2, y2, x3, y3, x4, y4}); } else if (directionType == "left") { container.push_back(case_input_t{x2, y2, x1, y1, x4, y4, x3, y3}); } else if (directionType == "face") { container.push_back(case_input_t{x1, y1, x2, y2, x4, y4, x3, y3}); } else { // if (directionType == "back") container.push_back(case_input_t{x2, y2, x1, y1, x3, y3, x4, y4}); } } -
最后将上面所说的向量扩展成直线/射线/线段的具体对象。这样每个对象都有三种情况,因此可以两两组合。我们利用了宏和辅助函数对GoogleTest的单元测试函数进行了封装,便于我们快速构造样例:
// Macro functions #define TEST_LINE_OVERLAP_INTERSECTED(lineTypeA, lineTypeB, overlapType, directionType, expected, numIntersections) \ TEST(ExceptionTest, lineTypeA##_##lineTypeB##_##overlapType##_##directionType) { \ runCase((LineType::lineTypeA), (LineType::lineTypeB), #overlapType, #directionType, (expected), (numIntersections)); \ } #define TEST_LINE_OVERLAP(lineTypeA, lineTypeB, overlapType, directionType, expected) \ TEST_LINE_OVERLAP_INTERSECTED(lineTypeA, lineTypeB, overlapType, directionType, expected, 0) // case 0: -------- ......... (divide) TEST_LINE_OVERLAP(LINE, LINE, divide, left, false) TEST_LINE_OVERLAP(LINE, LINE, divide, right, false) TEST_LINE_OVERLAP(LINE, LINE, divide, face, false) TEST_LINE_OVERLAP(LINE, LINE, divide, back, false) ... // (LINE, HALF, SEG) x (LINE, HALF, SEG) --> 6 combinations TEST_LINE_OVERLAP(SEGMENT_LINE, SEGMENT_LINE, divide, left, true) TEST_LINE_OVERLAP(SEGMENT_LINE, SEGMENT_LINE, divide, right, true) TEST_LINE_OVERLAP(SEGMENT_LINE, SEGMENT_LINE, divide, face, true) TEST_LINE_OVERLAP(SEGMENT_LINE, SEGMENT_LINE, divide, back, true) // case 1: --------........ (cat) TEST_LINE_OVERLAP(LINE, LINE, cat, left, false) TEST_LINE_OVERLAP(LINE, LINE, cat, right, false) TEST_LINE_OVERLAP(LINE, LINE, cat, face, false) TEST_LINE_OVERLAP(LINE, LINE, cat, back, false) ... // (LINE, HALF, SEG) x (LINE, HALF, SEG) --> 6 combinations TEST_LINE_OVERLAP_INTERSECTED(SEGMENT_LINE, SEGMENT_LINE, cat, left, true, 1) TEST_LINE_OVERLAP_INTERSECTED(SEGMENT_LINE, SEGMENT_LINE, cat, right, true, 1) TEST_LINE_OVERLAP_INTERSECTED(SEGMENT_LINE, SEGMENT_LINE, cat, face, true, 1) TEST_LINE_OVERLAP_INTERSECTED(SEGMENT_LINE, SEGMENT_LINE, cat, back, true, 1) // case 2: ------.-.-.-...... (overlap) TEST_LINE_OVERLAP(LINE, LINE, overlap, left, false) TEST_LINE_OVERLAP(LINE, LINE, overlap, right, false) TEST_LINE_OVERLAP(LINE, LINE, overlap, face, false) TEST_LINE_OVERLAP(LINE, LINE, overlap, back, false) ...其中
TEST_LINE_OVERLAP的最后一位参数true/false表明该种情况是否合法。而TEST_LINE_OVERLAP_INTERSECTED的最后两个参数不但检查是否合法,还检查了是否相交、交点个数。
我们共生成并测试了149个单元测试例,涵盖了100%的代码行,并在每一次Git Commit前重新测试,以达到“回归测试”的效果。
异常处理*
在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
异常处理部分由 @MisTariano 贡献设计与大部分代码, @FuturexGO 调整与重构。
为了使核心模块具有高度的兼容性,我们决定不使用异常类、try-catch等写法,而是采用了类似操作系统中的写法,将异常错误码和错误信息打包进结构体,在每个函数返回错误码,数据结构如下:
enum ERROR_CODE {
SUCCESS,
WRONG_FORMAT,
VALUE_OUT_OF_RANGE,
INVALID_LINE, INVALID_CIRCLE,
LINE_OVERLAP, CIRCLE_OVERLAP,
};
struct ERROR_INFO {
ERROR_CODE code = SUCCESS;
int lineNoStartedWithZero = -1;
char messages[50] = "";
};
其中每一类的错误具体设计如下(由于错误检测和抛出是公有标准接口的一部分,因此与另一组的 @PX_L 共同设计完成):
-
WRONG_FORMAT:输入不符合文法的情况,如缺失行、缺失字段、形状标识符不在C、L、R、S中、字段不是整数等。实现时,我们使用scanf/fscanf/sscanf("%s", word)每次取一个字符串token,再利用strtol尝试将其转换为整数。单元测试样例为:TEST(ExceptionTest, InvalidInput1) { gManager *mng = createManager(); FILE *filein = fopen("../data/invalid_input1.txt", "r"); EXPECT_EQ(addShapesBatch(mng, filein, nullptr, nullptr).code, ERROR_CODE::WRONG_FORMAT); EXPECT_EQ(getIntersectionsCount(mng), 3); closeManager(mng); } // invalid_input1.txt: 5 L 0 1 1 1 L 1 0 1 1 C 0 0 1 LL 0 1 1 1 L 0 -1 1 -1首先尝试从文件批量添加图形,应该得到
WRONG_FORMAT的错误码。截止到发生错误的前一刻,成功添加的三个图形产生了三个交点。 -
VALUE_OUT_OF_RANGE:图形参数超过\((-100000, 100000)\)的限制(注意到圆半径非正不属于此异常)。测试例为:TEST(ExceptionTest, InvalidShape7) { gManager *mng = createManager(); FILE *filein = fopen("../data/invalid_shape7.txt", "r"); EXPECT_EQ(addShapesBatch(mng, filein, nullptr, nullptr).code, ERROR_CODE::VALUE_OUT_OF_RANGE); EXPECT_EQ(getIntersectionsCount(mng), 0); closeManager(mng); } // invalid_shape7.txt: 5 L 0 1 1 1 L 1 0 10000000 1 C 0 0 1 L 0 1 1 1 L 0 -1 1 -1首先尝试从文件批量添加图形,应该得到
VALUE_OUT_OF_RANGE的错误码。截止到发生错误的前一刻,成功添加的三个图形产生了零个交点。 -
INVALID_LINE, INVALID_CIRCLE:不是一个线/圆图形,如直线两点重合、圆半径非正数。测试例为:TEST(ExceptionTest, InvalidShape3) { gManager *mng = createManager(); FILE *filein = fopen("../data/invalid_shape3.txt", "r"); EXPECT_EQ(addShapesBatch(mng, filein, nullptr, nullptr).code, ERROR_CODE::INVALID_CIRCLE); EXPECT_EQ(getIntersectionsCount(mng), 1); closeManager(mng); } // invalid_shape3.txt: 5 L 0 1 1 1 L 1 0 0 1 C 0 0 0 L 0 1 1 1 L 0 -1 1 -1 TEST(ExceptionTest, InvalidShape4) { gManager *mng = createManager(); FILE *filein = fopen("../data/invalid_shape4.txt", "r"); EXPECT_EQ(addShapesBatch(mng, filein, nullptr, nullptr).code, ERROR_CODE::INVALID_LINE); EXPECT_EQ(getIntersectionsCount(mng), 0); closeManager(mng); } // invalid_shape4.txt: 5 L 0 1 1 1 L 1 0 1 0 C 0 0 1 L 0 1 1 1 L 0 -1 1 -1在第一例中,虽然第四个图形与第一个图形重合,但在此之前第三个图形圆已经非法,应该得到
INVALID_CIRCLE。截止那时,成功添加的两个图形产生了一个交点。在第二例中,虽然第四个图形与第一个图形重合,但在此之前第二个图形直线已经非法,应该得到
INVALID_LINe。截止那时,成功添加的一个图形产生了零个交点。 -
LINE_OVERLAP, CIRCLE_OVERLAP:线-线产生无穷多交点、圆-圆产生无穷多交点。测试例为:TEST(ExceptionTest, OverlapFromFile) { gManager *mng = createManager(); FILE *filein = fopen("../data/overlap_batch.txt", "r"); EXPECT_EQ(addShapesBatch(mng, filein, nullptr, nullptr).code, ERROR_CODE::LINE_OVERLAP); EXPECT_EQ(getIntersectionsCount(mng), 1); closeManager(mng); } // overlap_batch.txt: 3 L 0 0 1 1 L 0 0 -1 1 L 1 1 0 0在上例中,第三个图形与第一个图形重合,应该得到
LINE_OVERLAP。截止那时,成功添加的两个图形产生了一个交点。圆-圆重合的例子较为显然,此处略。
GUI模块的具体设计*
在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。
由于追求跨平台能力,我们以Qt5为基础搭建GUI,借助QCustomPlot类库来绘制基本图形。支持的功能包括:
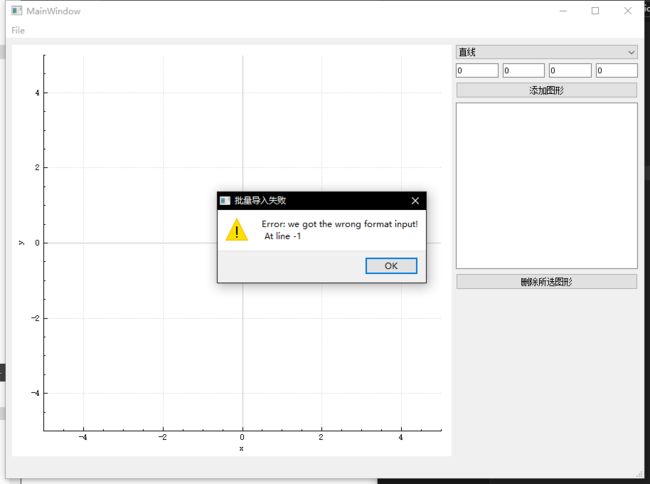
- 批量导入图形:浏览并读取txt格式的文本文件,从文件中批量导入图形描述,并绘制图形与交点。支持基本的文件格式错误处理,弹出对话框告知用户错误类型、错误信息、错误行号。
- 添加单个图形:在窗口右侧工作区输入参数并选择类型后,点击添加按钮可以将单个图形加入画布。
- 从画布选择并删除图形:在画布上单击图形使其被选中(颜色变蓝),再按下
Delete键,即可将其从画布删去。若按住左Ctrl则可以复选多个图形,并批量删除。当图形被删除后,依赖于该图形的交点若无其他图形相交于此,则该交点也会被删除。 - 从列表选择并删除图形:在窗口右侧工作区的图形列表中选择一个或多个图形后,按下删除按钮,可以将选中的列表项对应的图形删去。当图形被删除后,依赖于该图形的交点若无其他图形相交于此,则该交点也会被删除。
- 交点求解:借助核心计算库实现的交点求解。所有画布上的图形间一旦产生交点会立即被以黑色实心点标出。
- 鼠标滚轮缩放画布。用户使用鼠标滚轮缩放以调整视野大小。
以删除图形功能为例,我们重载了keyPressEvent以响应键盘事件delete键:
void MainWindow::keyPressEvent(QKeyEvent * event) {
if(event->key() == Qt::Key_Delete){ // detected "delete" key
auto items = ui->plot->selectedItems(); // get selected QCustomPlotItem(s)
for(auto& item: items){
auto name = item->objectName();
ui->plot->removeItem(item); // remove shape from GUI figure
auto shape = shapes.find(name);
if(shape != shapes.end()) { // remove shape from GUI list
shapeListModel.removeRow(shape->index.row());
}
shapes.remove(name);
}
cleanFigure(gfig); // STDINTERFACE: recalculate points
for(const auto &shapeItem: shapes.values()) {
auto &shape = shapeItem.gshape;
addShapeToFigure(gfig, {shape.type, shape.x1, shape.y1, shape.x2, shape.y2});
}
if(getShapesCount(gfig) == 0) {
nextGraphId = 0;
}
replotPoints(); // replot points fetched from STDINTERFACE
ui->plot->replot();
}
}
检测到删除操作后,我们从QCP(QCustomPlot)框架中拿到待删除QCPItem,从GUI程序中维护的数据结构中查询到其属性,并在GUI的画布和列表中将其删除。之后,我们调用核心模块的接口以重新计算剩余形状的交点,最后在replotPoints()中取出这些交点拷贝到GUI的存储中,再进行重绘。
GUI与核心模块的对接*
详细地描述 UI 模块的设计与两个模块的对接,并在博客中截图实现的功能。
在Qt中负责实现响应事件功能的是信号-槽机制。每个继承自QObject的对象sender都可以发射一个信号signal以表明其状态被改变。槽是普通的C++成员函数,作为函数指针member被关联,每个对象receiver都可以关联它的成员函数作为槽。
当一个信号被发射时,与其相关联的槽将被立刻执行,就象一个正常的函数调用一样。信号-槽机制完全独立于任何 GUI 事件循环。——IBM-QT 的信号与槽机制介绍
将信号-槽关联的函数原型为:
bool QObject::connect(const QObject *sender, const char *signal,
const QObject *receiver, const char *member);
因此为实现功能,我们定义了如下这些槽函数作为对基本信号(如点击按钮、点击鼠标、按下删除键)的响应:
private slots:
void on_actionOpen_triggered();
void on_shapeTypeComboBox_currentIndexChanged(int);
void on_addShapeButton_clicked();
void on_plot_mouseWheel(QWheelEvent*);
void on_plot_mouseMove(QMouseEvent*);
void on_plot_mousePress(QMouseEvent*);
void on_deleteButton_clicked();
这些对信号的响应可以按UI的设计逻辑组合,再调用具体的行为函数,如画图、画点、重绘等:
QCPAbstractItem *drawCircle(const QString &id, int x, int y, int r);
QCPAbstractItem *drawHalfLine(const QString &id, int x1, int y1, int x2, int y2);
QCPAbstractItem *drawSegmentLine(const QString &id, int x1, int y1, int x2, int y2);
QCPAbstractItem *drawLine(const QString &id, int x1, int y1, int x2, int y2);
QString plotShape(char type, int x1, int y1, int x2, int y2);
void drawPoint(double x, double y);
void replotPoints();
在这些函数中,我们StdInterface.h中的接口函数被调用。
因此总结来看,接口函数被调用的路径是:
- 槽函数响应事件;
- 事件组合出的逻辑(类似状态机)调用执行特定功能的函数;
- 执行特定功能的函数可能调用接口函数以向核心模块或从核心模块同步数据更新。
同时,为了将QCP的对象QCPItem与核心模块内的几何图形建立联系,我们使用自定义数据结构和map将它们联系起来,实现索引的功能:
struct shape_item_t {
gShape gshape; // STDINTERFACE
QCPAbstractItem *item;
QPersistentModelIndex index;
};
QMap shapes;
以导入文件为例,on_actionOpen_triggered()被按钮触发,决定导入文件。从QFileDialog得到文件名后,我们调用接口addShapesToFigureFile对核心模块内的数据进行更新,同时也维护GUI内部的数据和图形界面,保持核心模块内外同步:
void MainWindow::on_actionOpen_triggered() {
...
ERROR_INFO err = addShapesToFigureFile(gfig, fname.toStdString().c_str());
if(err.code == ERROR_CODE::SUCCESS){ // 成功计算交点, 无异常
updateShapes(gfig);
int nShape = getShapesCount(gfig);
for(int i = 0; ishapes[i]; // 取出gShape, 一个个绘制图形
QString id = plotShape(shape.type, shape.x1, shape.y1, shape.x2, shape.y2);
}
replotPoints(); // 取出gPoint, 批量绘制交点
} else {
cleanFigure(gfig); // 发生异常, 取出异常提示信息串、异常行号等信息
QMessageBox::warning(this, "批量导入失败", err.messages+QString("\n At line ")+QString::number(err.lineNoStartedWithZero));
}
...
}
效果如下图所示:
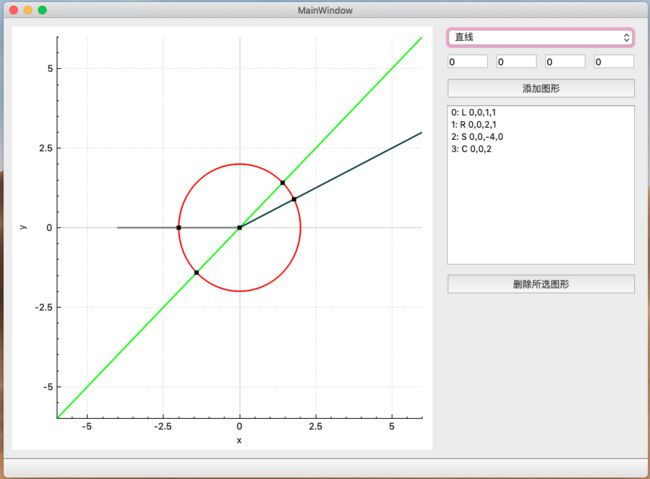
松耦合展示*
我们与 @PX_L 小组进行了松耦合实验。我们使用CMakeFile维护跨平台的工程结构与编译链接选项。因此我们的松耦合实验可以在多平台上进行:
- 我们在MacOS上进行了命令行程序调用核心模块的实验,涉及到互换的动态链接库为
libgCore.dylib。 - 我们在MS Windows上进行了GUI程序调用核心模块的实验,涉及到互换的动态链接库为
libgCore.dll。
命令行程序接入两个版本的核心模块
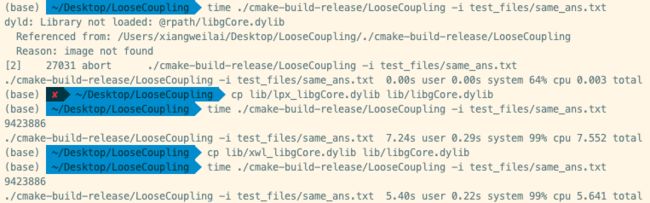
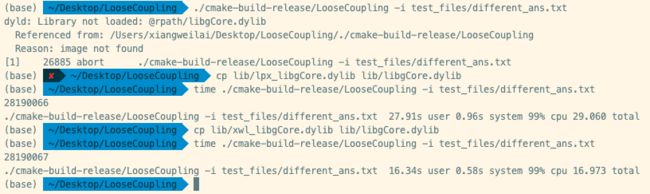
我们构造了三组样例进行测试,分别为:
same_ans.txt。两组的程序在它上的输出相同。different_ans.txt。两组的程序在它上的输出由于精度问题处理不同,答案不相同,相差1。exception.txt。两组的程序在它上都能检测异常,但异常提示信息不同。
测试的过程如下:
- 两组各自编译出自己的动态链接库,分别命名为
xwl_libgCore.*(*为dll、dylib等)和lpx_libgCore.*。 - 撰写
main.cpp,并引用接口声明文件 StdInterface.h。由于我们各自的私有接口不同,GUI和命令行程序的需求也不同,因此我们通过一次会议统一了标准接口,规则是兼容两组的功能需求,选取一个“最小公倍数”对现有代码进行增加,无需舍弃各自小组之前的设计。 - 使用链接命令,将名称为
libgCore.*的库文件链接进main.cpp的目标可执行文件中。 - 分别在
libgCore.*缺失、拷贝自xwl_libgCore.*、拷贝自lpx_libgCore.*的情况下运行可执行文件。过程中不重新编译,不修改代码。
下面是测试结果:
期望相同输出:
期望不同输出:
期望检测相同异常,但抛出各自的自定义异常信息:
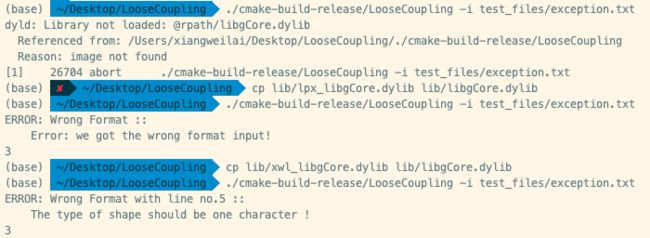
可以看出:
- 可执行程序在缺失动态链接库的条件下无法运行。
- 可执行程序在给定两个动态链接库中的任意一个都能正常运行。
- 直接更换动态库能实现接入两组实现的不同后端的需求,并获得不同的输出和性能表现。
因此证明我们成功实现了计算模块gCore的松耦合。
在实验中,起初我们各自编码时认同的 StdInterface.h 有微小的差异,其中几个函数的签名不同:
// xwl, et al. 认同的接口
ERROR_INFO addShapeToFigureString(gFigure *fig, const char *desc);
// lpx, et al. 认同的接口
ERROR_INFO addShapeToFigureString(gFigure *fig, char *desc);
这样,编译生成动态链接库的过程是独立的,不会出现错误。然而在撰写main.cpp时应当#include "StdInterface.h",这样的头文件是唯一的,必须将标准统一才能成功运行,否则将会发现找不到所需的接口函数,因为上述两个函数的函数签名不同,本质上它们被编译器认为是两个不同的函数。
因此我们将头文件统一,修改了各自的接口的代码,之后便成功完成实验。
GUI程序接入两个版本的核心模块
类似上文中CLI环境下的测试,我们在GUI中也测试了使用不同dll的运行效果。需要注意的是,对于正样例而言,即使更换了实现GUI的行为差异也很难看出(交点之间过于密集时会难以分辨两种实现的差别),因此在这里我们主要测试了负例,即程序在添加图形遇到异常时观察GUI输出的错误信息。
- case 1:尝试添加与现有形状存在重合的形状。此时我们已经添加了直线\(y=x\)并尝试再次添加
当可执行文件同级目录下提供我们实现的libgCore.dll时:
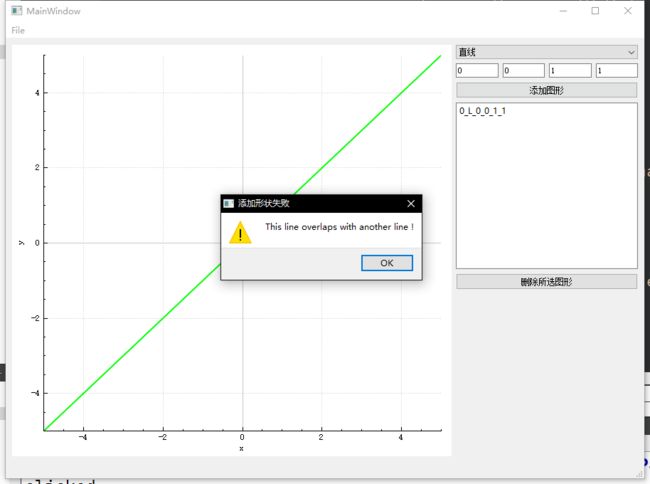
当可执行文件同级目录下提供lpx & yzn小组实现的libgCore.dll时:
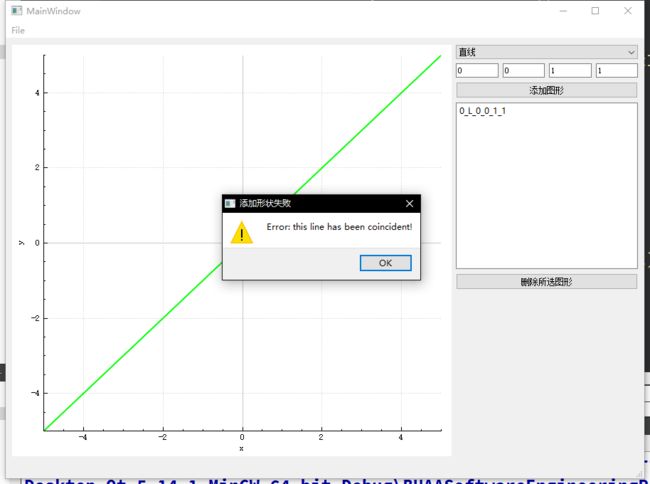
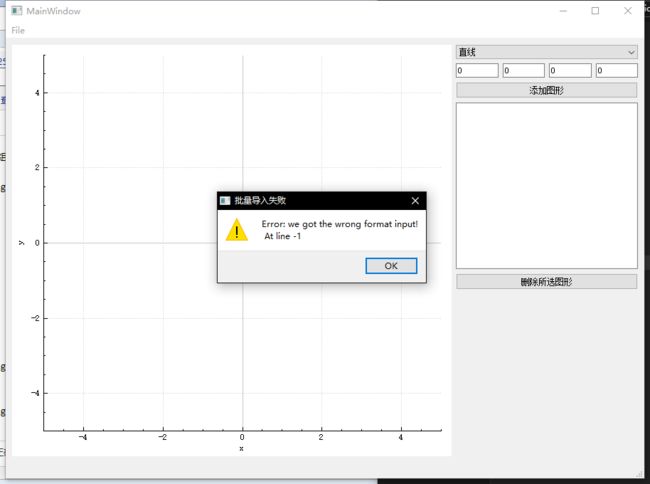
- case 2:当尝试打开存在非法形状类型描述的文件时
我们尝试打开这份测试文件:
5
L 0 1 1 1
L 1 0 1 1
C 0 0 1
? 0 1 1 1
L 0 -1 1 -1
注意到第五行(从0下标开始算的第4行)的形状类型是?,这是错误的,因此期望报错。
当可执行文件同级目录下提供我们实现的libgCore.dll时:

当可执行文件同级目录下提供lpx & yzn小组实现的libgCore.dll时:
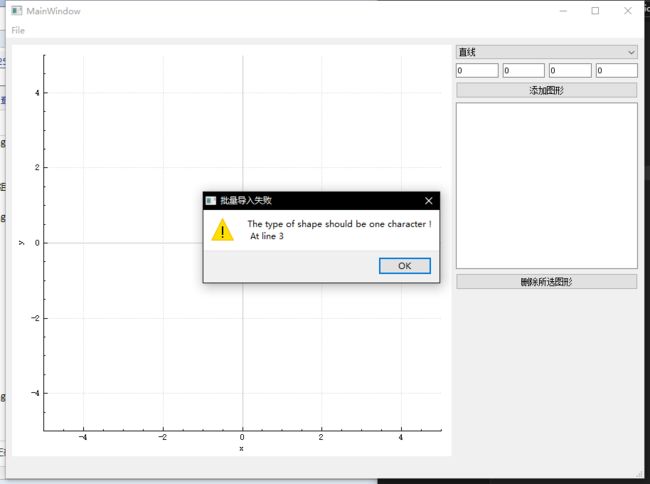
- case 3:当尝试打开不完整的文件时
我们尝试打开这份测试文件:
5
L 0 1 1 0
L 1 0 1 1
当可执行文件同级目录下提供我们实现的libgCore.dll时:
当可执行文件同级目录下提供lpx & yzn小组实现的libgCore.dll时:
- 小结
可以看到对相同的异常情况,在加载不同dll运行时GUI程序给出了不同的报错信息——前后没有经过重新编译,而只是替换了dll文件而已。可见替换dll文件动态地更改了程序运行时的行为,起到了松耦合的效果。
结对过程*
提供两人在讨论的结对图像资料。
我们主要使用腾讯会议实现结对编程的实时互动。腾讯会议的主要特点是可以实时共享屏幕同时通话,但单凭腾讯会议无法做到代码的管理。
因此我们使用GitHub进行源代码的管理。我们使用到的主要特色包括:
-
分支 Branch。我们将工程分为若干个阶段,每开始构建一个阶段就新开出一个分支,完全debug、重构、测试后,才并入master分支。

-
Pull Request。我们在将完成的分支合并到master时使用Pull Request进行逐行级别的代码复审和新增功能&潜在BUG记录。作者A主导完成某Branch后,作者A就发起一个Pull Request,并指定另一作者B为Reviewer对代码进行审查。
-
Releases&Tags。我们使用tags对commit进行分支无关的标记,进度统计更加明确,无需考虑分支的分离和合并;也让代码分享(如与其他人交流设计公有接口)更加简单。
反思结对编程
看教科书和其它参考书,网站中关于结对编程的章节,例如:http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html ,说明结对编程的优点和缺点。同时描述结对的每一个人的优点和缺点在哪里(要列出至少三个优点和一个缺点)
| 优点 | 缺点 | |
|---|---|---|
| 结对编程 | 工作更有动力,能集思广益,减少犯错几率。 | 两人工作有顺序、先后等约束, 容易从双线程并行退化成单线程。 |
| 我 | 思维敏捷,对目标和任务时刻有明确认识,代码错误少。 | 在具体语言上的设计经验不足。 |
| 结对伙伴 | 编码速度快,工作态度积极,熟悉GitHub等工具和PR等工作流。 | 在两人一起写代码时经常走神,自己一个人写的时候效率和质量可能更高。 |