BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型效果达到state-of-the-art,但结构十分精简,推理速度也不慢,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS,并且论文的优化方法很有学习的价值,值得一读
论文:BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation

- 论文地址:https://arxiv.org/abs/2001.00309
Introduction
密集实例分割模型早期主要有两种,top-down apporach和bottom-up apporach
top-down apporach
top-down模型先通过一些方法获取box区域,然后对区域内的像素进行mask提取,这种模型一般有以下几个问题:
- 特征和mask之间的局部一致性会丢失,论文讨论的是Deep-Mask,用fc来提出mask
- 冗余的特征提取,不同的bbox会重新提取一次mask
- 由于使用了缩小特征图的卷积,位置信息会损失
bottom-up apporach
bottom-up模型先对整图进行逐像素预测(per-pixel prediction),每个像素生成一个特征向量,然后通过一些方法来对像素进行分组。由于进行的是逐像素级预测且步长很小,局部一致性和位置信息可以很好的保存,但是依然存在以下几个问题:
- 严重依赖逐像素预测的质量,容易导致非最优的分割
- 由于mask在低维提取,对于复杂场景(类别多)的分割能力有限
- 需要复杂的后处理方法
hybridizing apporach
考虑到上面的问题,论文综合了top-down和bottom-up的策略,利用instance-level信息(bbox)对per-pixel prediction进行裁剪和加权输出。虽然FCIS和YOLACT已有类似的思想,但论文认为他们都没有很好的处理top-level和bottom-level的特征,高维特征包含整体的instance信息,而低维特征的则保留了更好的位置信息,论文的重点在于研究如何合并高低维特征,主要贡献有以下几点:
- 提出了proposal-based的instance mask合并方法,blender,在COCO上对比YOLACT和FCIS的合并方法分别提升了1.9和1.3mAP
- 基于FCOS提出简洁的算法网络BlendMask
- BlendMask的推理时间不会像二阶检测器一样随着预测数量的增加而增加
- BlendMask的准确率和速度比Mask R-CNN要好,且mask mAP比最好的全卷积实例分割网络Tensor-Mask要高1.1
- 由于bottom模块能同时分割多种物体,BlendMask可直接用于全景分割
- Mask R-CNN的mask输出固定为$28\times 28$,BlendMask的mask输出像素可以很大,且不受FPN的限制
- BlendMask通用且灵活,只要一些小修改,就可以用于其它instance-level识别任务中,例如关键点检测
Our methods
Overall pipeline

BlendMask包含检测网络和mask分支,mask分支包含3个部分,bottom module用于预测score maps,top layer用于预测实例的attentions,blender module用于整合分数以及attentions,整体的架构如图2所示
- Bottom module
bottom module预测的score maps在文中称为基底(base)$B$。$B$的大小为$N\times K\times \frac{H}{s}\times \frac{W}{s}$,其中N为batch size,K为基底的数量,$H\times W$是输入的大小,而$s$则是score maps的输出步长。
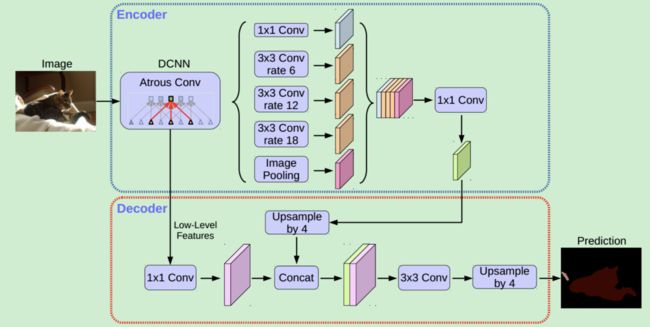
论文采用DeepLab V3+的decoder,该decoder包含两个输入,一个低层特征和一个高层特征,对高层特征进行upsample后与低层特征融合输出。这里使用别的结构也是可以的,而bottom module的输入可以是backbone的feature,也可以是类似YOLACT或Panoptic FPN的特征金字塔
- Top Layer
在每一个detection tower后接了一层卷积层用来预测top-level attentions$A$。 在YOLACT中,每一层金字塔($H_l\times W_l$)输出的$A$为$N\times K\times H_l\times W_l$,即对应基底每个channel的整体的权重值。而论文输出的$A$为$N\times (K\cdot M\cdot M)\times H_l\times W_l$,$M\times M$是attention的分辨率,即对应基底每个channel的像素点的权重值,粒度更细,是element-wise的操作(后面会讲到)。
由于attentions是3D结构($K\cdot M\cdot M$),因此可以学习到一些实例级别的信息,例如对象大致的形状和姿态。$M$的值是比较小的,只做粗略的预测,一般最大为14,使用output channel为($K\cdot M\cdot M$)的卷积来实现。在送到一下个模块之前,先使用FCOS post-process方法来选择top D个bbox $P={p_d \in \mathbb{R}_{\ge0}^4 |d=1...D}$和对应的attentions $A={a_d \in \mathbb{R}^{K\times M\times M} |d=1...D}$,具体的选择方法是选择分类置信度$\ge$阈值的top D个bbox,阈值一般为0.05
- Blender module
Blender module是BlendMask的关键部分,根据attentions对位置敏感的基底进行合并输出
Blender module
blender模块的输入为bottom-level的基底$B$以及选择的top-level attentions$A$和bbox$P$
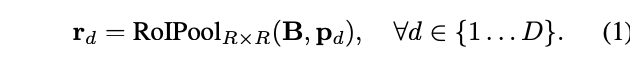
首先,使用Mask R-CNN的ROIPooler来截取每个bbox$p_d$对应的基底区域,并resize成固定$R\times R$大小的特征图$r_d$。具体地,使用sampleing ratio=1的RoIAlign,每个bin只采样1个点,Mask R-CNN每个bin采样4个点。在训练的时候,直接使用gt bbox作为proposals,而在推理时,则直接用FCOS的检测结果

attention大小$M$是比$R$小的,因此需要对$a_d$进行插值,从$M\times M$变为$R\times R$,$R={r_d|d=1...D}$
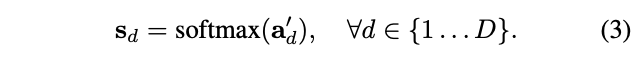
接着对$a_d^{'}$的K维attention分别进行softmax归一化,产生一组score map $s_d$

然后对每个region$R$的$r_d$和对应的score map$S$的$s_d$进行element-wise product,最后将K个结果进行相加得到$m_d$
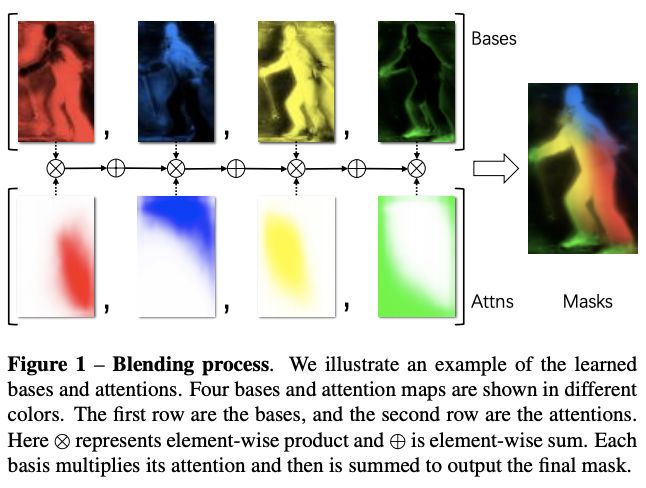
图1对blend module的操作进行了可视化,可以看到attenttions和基底的特征以及融合的过程,可以说十分生动形象了
Configurations and baselines
BlendMask的超参数如下:
- $R$,bottom-level RoI的分辨率
- $M$,top-level预测的分辨率
- $K$,基底的数量(channel)
- bottom模块的输入可以是骨干网络或FPN的feature
- 基底的采样方法可以是最近邻或双线性池化
- top-level attentions的插值方法可以是最近邻或双线性采样
论文用缩写$R_K_M$来表示模型,使用骨干特征C3和C5作为bottom模块的输入,top-level attention使用最近邻插值,bottom level使用双线性插值,与RoIAlign一致
Semantics encoded in learned bases and attentions

基底和attentions的可视化结果如图3所示,论文认为BlendMask能提取两种位置信息:
- 像素是否在对象上(semantic masks)
- 像素是否在对象的具体部位上(position-sensitive features),比如左上角,右下角
红蓝两个基底分别检测了目标的右上和左下部分点,黄色基底则检测了大概率在目标上的点(semantic mask),而绿色基底则激活了物体的边界,position-sensitive features有助于进行实例级别的分割,而semantic mask则可以对postion-sensitive进行补充,让最后的结果更加顺滑。由于学习到了更多准确的特征,BlendMask使用了比YOLACT和FCIS少很多的基底纬度(4 vs. 32 vs. 49)
Experiment
消融实验
- Merging methods: Blender vs. YOLACT vs. FCIS
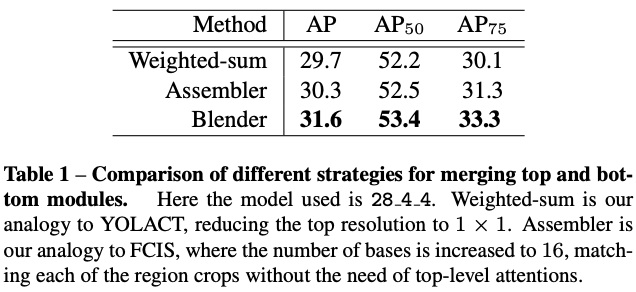
论文将blender改造成其它两个算法的merge模型进行实验,从Table1可以看出,Blender的merge方法要比其它两个算法效果好
- Top and bottom resolutions
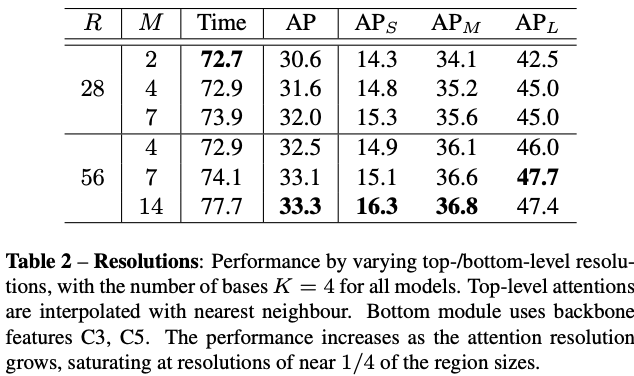
从Table2可以看出,随着resolution的增加,精度越来越高,为了保持性价比,R/M的比例保持大于4,总体而言,推理的时间是比较稳定的
- Number of bases
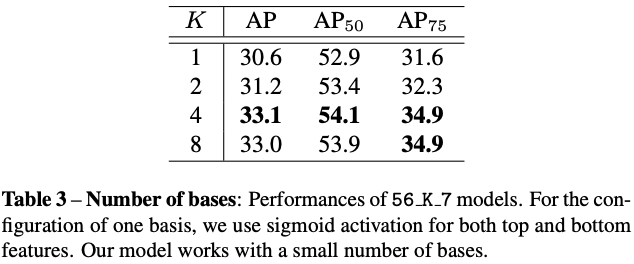
从Table3可以看出,K=4是最优
- Bottom feature locations: backbone vs. FPN
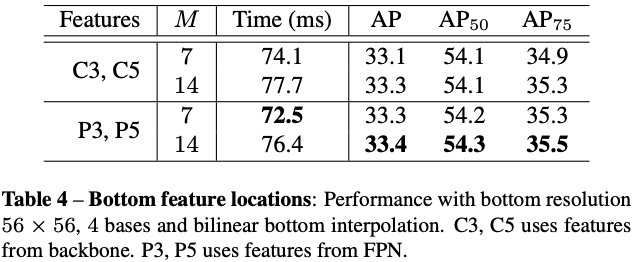
从图4可以看出,使用FPN特征作为bottom模块的输入,不仅效率提升了,推理时间也加快了
- Interpolation method: nearest vs. bilinear
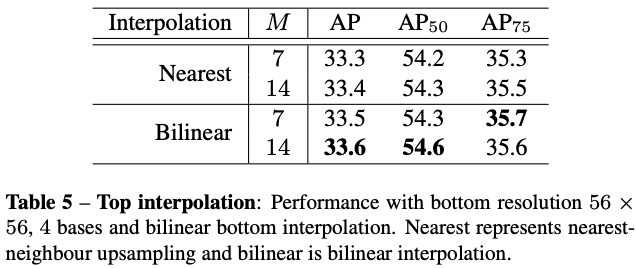
在对top-level attentions进行插值时,双线性比最近邻高0.2AP
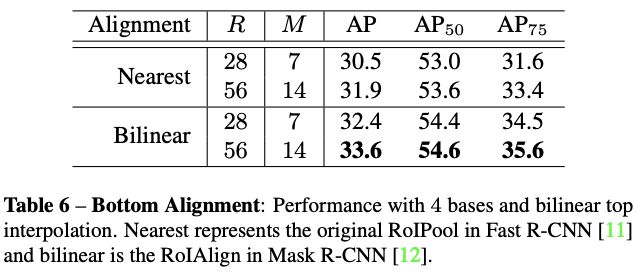
而对bottom-level score maps进行插值时双线性比最近邻高2AP
- Other improvements

论文也尝试了其它提升网络效果的实验,虽然这些trick对网络有一定的提升,但是没有加入到最终的网络中
Main result
- Quantitative results

从结果来看,BlendMask在效果和速度上都优于目前的实例分割算法,但是有一点,在R-50不使用multi-scale的情况下,BlendMask的效果要比Mask R-CNN差
- Real-time setting
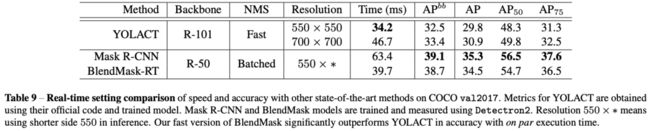
为了跟YOLACT对比,论文改造了一个紧凑版的BlendMask-RT: 1) 减少prediction head的卷积数 2) 合并classification tower和box tower 3) 使用Proto-FPN并去掉P7。从结果来看,BlendMask-RT比YOLACT快7ms且高3.3AP
- Qualitative results

图4展示了可视化的结果,可以看到BlendMask的效果比Mask R-CNN要好,因为BlendMask的mask分辨为56而Mask R-CNN的只有28,另外YOLACT是难以区分相邻实例的,而BlendMask则没有这个问题
Discussions
- Comparison with Mask R-CNN
BlendMask的结构与Mask R-CNN类似,通过去掉position-sensitive feature map以及重复的mask特征提取来进行加速,并通过attentions指导的blender来替换原来复杂的全局特征计算
BlendMask的另一个优点是产生了高质量的mask,而分辨率输出是不受top-level采样限制。对于Mask R-CNN增大分辨率,会增加head的计算时间,而且需要增加head的深度来提取准确的mask特征 。另外Mask R-CNN的推理时间会随着bbox的数量增加而增加,这对实时计算是不友好的
最后,blender模块是十分灵活的,因为top-level的实例attention预测只有一个卷积层,对于加到其它检测算法中几乎是无花费的
- Panoptic Segmentation

BlendMask可以通过使用Panoptic-FPN的语义分割分支来进行全景分割任务,从结果来看,BlendMask效果更好
总结
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型综合各种优秀算法的结构,例如YOLACT,FOCS,Mask R-CNN,比较tricky,但是很有参考的价值。BlendMask模型十分精简,效果达到state-of-the-art,推理速度也不慢,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS,并且论文实验做得很充足,值得一读
参考内容
- 论文阅读学习 - (DeeplabV3+)Encoder-Decoder with Atrous Separable Convolution
- 加州大学提出:实时实例分割算法YOLACT,可达33 FPS/30mAP!现已开源!
- FCOS-一个挺不错的anchor free目标检测方法
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注个人微信公众号【晓飞的算法工程笔记】
