原文地址在我的博客, 转载请注明出处,谢谢!
概述
本文是《使用React技术栈的一些收获》系列文章的第一篇(第二篇在这里,介绍了React的一些原理)。这篇文章则介绍了大型React项目是如何架构的以及架构的原理和思想。项目背景是一个博客发布平台,类似于,项目地址时光笔记(还未完善...)
具体技术栈
项目技术栈使用的是React全家桶:React+redux+react router+es6+webpack+sass以及Data到View层我们使用了reselect。由于数据处理逻辑并不复杂,因此并没有使用immutable.js和Redux saga(后来我觉得连Redux都没必要用);样式方面考虑到可读性和开发人数较少(俩),我们并没有使用流行的CSS-module。
脚手架的选择
选择脚手架就选择了整体架构,我选择的是davezuko大神的react-redux-starter-kit,也是最受欢迎的脚手架之一。并在它的基础上安装了一些用到的包,删去了一些不用的包,让它更适合我们的项目。
项目架构
项目目录如下:
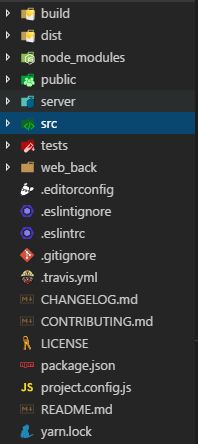
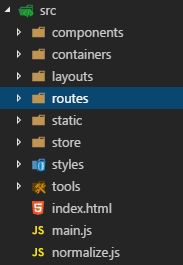

根据脚手架的架构,我们构建的是一个React单页应用。
总体来说
就是采用React router plain object+combineReducer+require.ensure的写法把不同的路由分割在routes目录下,对应不同的页面,做代码分割、按需加载。逻辑图如下:
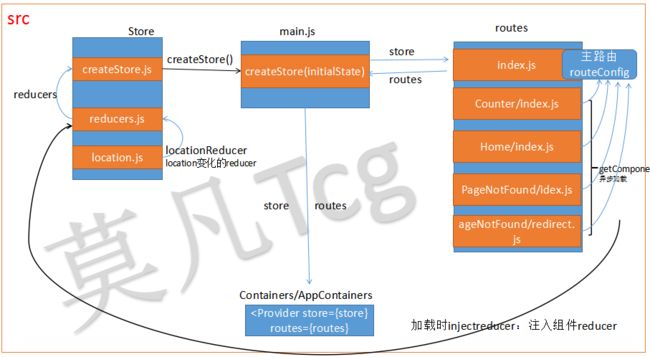
具体来说
首先src目录下有一个main.js,它用来创建store,并拿到路由(plain object形式),然后注入到顶层的Provider组件和其下的Router组件:
src下的main.js文件:
const initialState = window.___INITIAL_STATE__
const store = createStore(initialState)// 创建store
const MOUNT_NODE = document.getElementById('root')
let render = () => {
const routes = require('./routes/index').default(store)// 拿到路由
ReactDOM.render(
redux的store也随着页面分割而分割:
不同页面下的modules下的文件只负责本页面所需的所有action和reducer,并通过加载页面inject主reducer里,然后在src/store/reduce.js文件里combine,最后被引入到src/store/createStore里和同时引入的redux中间件一起创建store:
src/store目录下的reducer.js:
export const makeRootReducer = (asyncReducers) => {
return combineReducers({
auth: auth,
form: formReducer,
location: locationReducer,
...asyncReducers // 各页面下的reducer注入到这里
})
}
export const injectReducer = (store, { key, reducer }) => {
store.asyncReducers[key] = reducer
store.replaceReducer(makeRootReducer(store.asyncReducers))//注入时更新
}
以及src/store下的createStore文件:
const store = createStore(
makeRootReducer(),
initialState,
compose(
applyMiddleware(...middleware),
...enhancers
)
)
routes目录下有一个index.js文件,它使用plain object的写法集合各路由对应的页面;
routes下的index.js文件:(用来包含各页面)
src/routes/index.js:(采用React router plain object写法)
import CoreLayout from '../layouts/CoreLayout'
import Home from './Home'
import FollowRoute from './Follow'
import SignRoute from './Sign'
import HallRoute from './Hall'
import UserPageRoute from './UserPage'
import PageNotFound from './PageNotFound'
import Redirect from './PageNotFound/redirect'
export const createRoutes = (store) => ({
path: '/',
component: CoreLayout,
indexRoute: Home,
childRoutes: [ // 各页面
FollowRoute(store),
SignRoute(store),
HallRoute(store),
UserPageRoute(store),
PageNotFound(),
Redirect
]
})
每个页面目录下也有一个index.js文件并使用getComponent + webpack ensure按需加载页面的container和reducer:
每个页面下的index.js文件:(负责输出这个页面)
src/routes/sign/index.js(其他页面差不多,举个例子)
import { injectReducer } from '../../store/reducers'// 引入注入reducer函数
export default (store) => ({
path: 'sign', //页面路由
getComponent (nextState, cb) {
require.ensure([], (require) => { // webpack按需加载
const Sign = require('./containers/SignContainer').default //引入总container
const reducer = require('./modules/index').default//引入总reducer
injectReducer(store, { key: 'sign', reducer })// 加载时注入页面reducer到主reducer
cb(null, Sign)// 返回页面
})
}
})
在每个页面下,index.js是获得每个页面的入口,每个页面都有自己的components和containers以及actions和reducers,目录看起来像这样:

components和containers都是这个页面下的组件和容器,如果其他页面也会使用里面的组件和容器,就会把他们放在src/component和src/containers下共用。modules下的文件是这个页面所有的action和reducer。如果页面逻辑可以分离,会把各逻辑下的reducer抽离并单开一个index.js,并在其中combine:

=>

总结与反思
通过上述架构,项目代码逻辑变得很清晰,每一个文件都有其专属的功能,互不影响,开发过程变得工程化、流程化,思路很清晰,代码出错率大大降低,开发速度大大提高。React router plain object+redux combineReducer的组合很好的将代码按不同页面做了分割;而 getComponent + webpack ensure又做到了页面的按需加载,项目页面运行速度提升了不少。但是有一个问题,在react route4.0版本中getComponent被移除了,并提供了更加简洁的方式(实际上就是替你做了按需加载):Bundle组件+webpack 加载器undle-loader。使用这种方式的话,目录结构将会变得更简单、更容易理解,避免了多层嵌套,因此,项目还需要改善。