前言
前面的一篇给大家写了一些MapReduce的一些程序,像去重、词频统计、统计分数、共现次数等。这一篇给大家介绍的是关于Combiner优化操作。
一、Combiner概述
1.1、为什么需要Combiner
我们map任务处理的结果是存放在运行map任务的节点上。
map处理的数据的结果在进入reduce的时候,reduce会通过远程的方式去获取数据。
在map处理完数据之后,数据量特别大的话。reduce再去处理数据它就要通过网络去获取很多的数据。
这样会导致一个问题是:大量的数据会对网络带宽造成一定的影响。
有没有一种方式能够类似reduce一样,在map端处理完数据之后,然后在reduce端进行一次简单的数据处理?
MapReudce正常处理是:
map处理完,中间结果存放在map节点上。reduce处理的数据通过网络形式拿到reduce所在的节点上。
如果我们能够在map端进行一次类似于reduce的操作,这样会使进入reduce的数据就会少很多。
我们把在map端所执行的类似于reduce的操作成为Combiner。
1.2、Combiner介绍
1) 前提
每一个map都可能会产生大量的本地输出
2)Combiner功能
对map端的输出先做一次合并
3)目的
减少在map和reduce节点之间的数据传输量, 以提高网络IO性能。
二、使用Combiner优化Mapduce执行
2.1、使用前提
不能对最原始的map的数据流向reduce造成影响。也就是说map端进入reduce的数据不收Combiner的影响。
数据输入的键值类型和数据输出的键值类型一样的reduce我们可以把它当做Combiner来使用
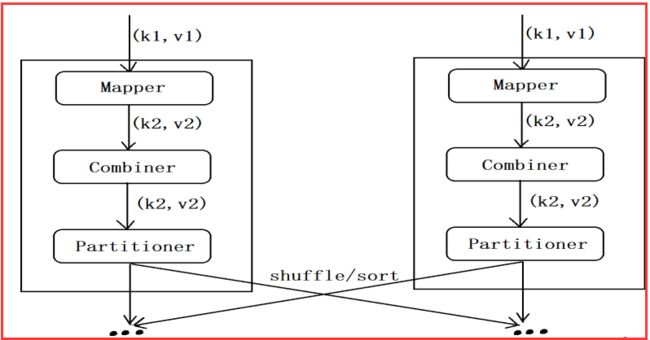
举例:
我们前面一篇博客中有一个处理的是求用户的好友列表的数据。
我们之后进入map端的数据类型为LongWritable,Text,而map端输出的数据类型为Text,Text(用户,好友),进入reduce之后reduce的输入类型为Text,Text,
最后reduce的输出也是Text,Text(用户,好友列表)。
这样总结:
reduce的输入类型等于reduce输出的数据类型,这样符合Combiner的情况。(这样我们就不需要去自定义数据类型了)
2.2、怎么使用
其实Combiner的本质就是一个reducer,那我们要写Combiner我们就要继承reducer。
下面写一个例子,首先你需要了解我前面写的一个专利引用的例子,才能了解专利文件数据格式。
需求:求这个专利以及这个专利它引用了哪些专利。
import com.briup.bd1702.hadoop.mapred.utils.PatentRecordParser;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PatentReferenceWithCombiner_0010 extends Configured implements Tool{
public static class PatentReferenceMapper extends Mapper{
private PatentRecordParser parser=new PatentRecordParser();
private Text key=new Text();
private Text value=new Text();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
parser.parse(value);
if(parser.isValid()){
this.key.set(parser.getPatentId());
this.value.set(parser.getRefPatentId());
context.write(this.key,this.value);
}
}
}
public static class PatentReferenceReducer extends Reducer{
private Text value=new Text();
@Override
protected void reduce(Text key,Iterable values,Context context) throws IOException, InterruptedException{
StringBuffer refPatentIds=null;
for(Text value:values){
refPatentIds.append(value.toString()+",");
}
this.value.set(refPatentIds.toString());
context.write(key,value);
}
}
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output"));
// 构建Job对象,并设置驱动类名和Job名,用于提交作业
Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
// 给Job设置Mapper类以及map方法输出的键值类型
job.setMapperClass(PatentReferenceMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 给Job设置Reducer类及reduce方法输出的键值类型
job.setReducerClass(PatentReferenceReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置文件的读取方式,文本文件;输出方式,文本文件
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 给Job是定输入文件的路径和输出结果的路径
TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output);
// 设置Combiner
job.setCombinerClass(PatentReferenceReducer.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00010_PatentReferenceWithCombiner_0010(),args));
}
}
注意:
1)我们在作业配置中设置Mapper和Reducer,所以我们的Combiner也需要设置的:

2)在这个例子中的Reducer直接就可以当作Combiner去使用。(Combiner的本质就是一个reducer)
2.3、利用Combiner计算每一年的平均气温
1)分析
如果我们不用Cobiner的时候,map输出是(年份,温度),进入reduce中的集合就是这一年中所有的温度值。我们在设置一个变量来叠加一下我们有多少个这样的温度。
然后把所有的温度加起来除以遍历的个数。这是正常情况下!
如果我们利用Combiner计算每一年的平均气温的时候,我们在map端先算一次平均温度,然后到reduce计算一个总的平均气温。
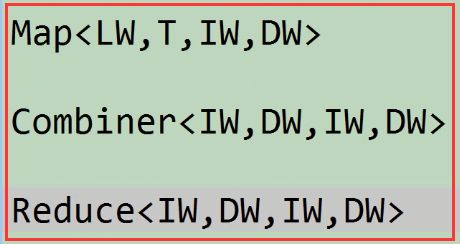
从上图来说,我们看出来虽然满足数据输入的键值类型和数据输出的键值类型一样的reduce,但是这是不符合我们的数学逻辑。

分析上图:我们不可能那把每个平均值拿出来除以个数吧,这样做是错误的。
2)解决

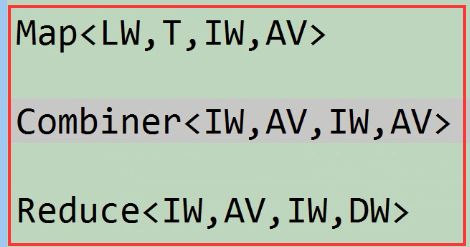
上图分析:我们可以把温度和个数组合起来,自定义一个数据类型(AV)。
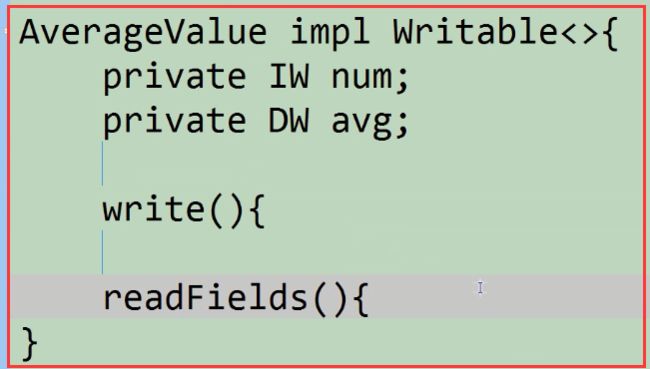
注意:我们Combiner和Reduce的数据输入和输出不一样,所以程序中的Reduce就不能作为Reduce了,
我们需要单独去编写一个Combiner,但是我们注意到Combiner和Reduce的实现(算法或应用程序内容)是一模一样的。
3)代码实现Combiner计算每一年的平均气温
第一:写一个AverageValue类
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.VIntWritable;
import org.apache.hadoop.io.Writable;
class AverageValue implements Writable{
private VIntWritable num;
private DoubleWritable avgValue;
AverageValue(){
num=new VIntWritable();
avgValue=new DoubleWritable();
}
AverageValue(AverageValue av){
num=new VIntWritable(av.num.get());
avgValue=new DoubleWritable(av.avgValue.get());
}
@Override
public void write(DataOutput out) throws IOException{
num.write(out);
avgValue.write(out);
}
@Override
public void readFields(DataInput in) throws IOException{
num.readFields(in);
avgValue.readFields(in);
}
public void set(int num,double avgValue){
this.num.set(num);
this.avgValue.set(avgValue);
}
public void set(VIntWritable num,DoubleWritable avgValue){
set(num.get(),avgValue.get());
}
public VIntWritable getNum(){
return num;
}
public void setNum(VIntWritable num){
this.num=num;
}
public DoubleWritable getAvgValue(){
return avgValue;
}
public void setAvgValue(DoubleWritable avgValue){
this.avgValue=avgValue;
}
@Override
public String toString(){
return "AverageValue{"+"num="+num+", avgValue="+avgValue+'}';
}
第二:实现
import com.briup.bd1702.hadoop.mapred.utils.WeatherRecordParser;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class AverageTemperatureWithCombiner_0010 extends Configured implements Tool{
static class AverageTemperatureWithCombinerMapper
extends Mapper{
private WeatherRecordParser parser=new WeatherRecordParser();
private IntWritable year=new IntWritable();
private AverageValue value=new AverageValue();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
parser.parse(value);
if(parser.isValid()){
this.year.set(parser.getYear());
this.value.set(1,
parser.getTemperature());
context.write(this.year,this.value);
}
}
}
static class AverageTemperatureWithCombinerCombiner
extends Reducer{
private AverageValue value=new AverageValue();
@Override
protected void reduce(IntWritable key,
Iterable values,Context context) throws IOException, InterruptedException{
int sum=0;
double value=0;
for(AverageValue av:values){
sum+=av.getNum().get();
value+=av.getAvgValue().get()
*av.getNum().get();
}
this.value.set(sum,value/sum);
context.write(key,this.value);
}
}
static class AverageTemperatureWithCombinerReducer
extends Reducer{
private DoubleWritable value=new DoubleWritable();
@Override
protected void reduce(IntWritable key,Iterable values,Context context) throws IOException, InterruptedException{
int sum=0;
double value=0;
for(AverageValue av:values){
sum+=av.getNum().get();
value+=av.getAvgValue().get()*
av.getNum().get();
}
this.value.set(value/sum);
context.write(key,this.value);
}
}
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output"));
Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.setMapperClass(AverageTemperatureWithCombinerMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(AverageValue.class);
job.setReducerClass(AverageTemperatureWithCombinerReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(DoubleWritable.class);
job.setCombinerClass(AverageTemperatureWithCombinerCombiner.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00030_AverageTemperatureWithCombiner_0010(),args));
}
}
2.4、计算每一年每个气象站的平均温度
1)分析
我们的key可以有两种方式:
使用一个Text和气象站拼接起来作为key,来计算平均温度。
我们可以创建一个数据类型,使用年份和气象站形成一个联合的key(联合腱),我们就写一个YeayStation,对于YearStation既要序列化又要可比较大小要实现WritableComparable
Hadoop的hash值用来干什么的?
我们需要使用hash值是因为在数据分区的时候,也就是确定哪个数据进入哪个reduce的时候。需要通过hashCode和reduce个数取余的结果确定进入哪个reduce。(IntWritable的默认hash值是它代表int类型数字的本身)
所以说数据分区主要是用的HashCode(key的值得hashCode)。
需要比较大小是因为进入同一个reduce的多组数据谁先进入,要比较它key值得大小。谁小谁先进入。
那我们这个复合键需不要重写hashCode和equals方法?
如果我们不去重写的话,我们使用的是Object的hashCode()方法。当我们一个YearStation对象重复去使用的时候,所有的hashCode都一样。
所以我们还是尽可能的去重写hashCode和equals方法。我们需要year和stationId同时参与分区,那我们重写的hashcode同时和这两个参数有关系。
2)代码实现
第一:编写YearStation类(联合腱)
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
public class YearStation
implements WritableComparable{
private IntWritable year;
private Text stationId;
public YearStation(){
year=new IntWritable();
stationId=new Text();
}
/*
复制构造器
*/
public YearStation(YearStation ys){
year=new IntWritable(ys.year.get());
stationId=new Text(ys.stationId.toString());
}
public void set(YearStation ys){
year=new IntWritable(ys.year.get());
stationId=new Text(ys.stationId.toString());
}
public void set(IntWritable year,Text stationId){
this.year=new IntWritable(year.get());
this.stationId=new Text(stationId.toString());
}
public void set(int year,String stationId){
this.year=new IntWritable(year);
this.stationId=new Text(stationId);
}
@Override
public int compareTo(YearStation o){
int yearComp=year.compareTo(o.year);
int stationIdComp=stationId.compareTo(o.stationId);
return yearComp!=0?yearComp:stationIdComp;
}
@Override
public void write(DataOutput out) throws IOException{
year.write(out);
stationId.write(out);
}
@Override
public void readFields(DataInput in) throws IOException{
year.readFields(in);
stationId.readFields(in);
}
@Override
public boolean equals(Object o){
if(this==o) return true;
if(!(o instanceof YearStation)) return false;
YearStation that=(YearStation)o;
if(!year.equals(that.year)) return false;
return stationId.equals(that.stationId);
}
@Override
public int hashCode(){
int result=year.hashCode();
result=127*result+stationId.hashCode();
return Math.abs(result);
}
@Override
public String toString(){
return year+"\t"+stationId;
}
}
注意:在这个需求中,我们需要重写toString()方法,因为我们这个键最后要输出到HDFS中的结果文件中去的。如果不重写可能是一个YearStation的地址。
我们知道reduce做输出最后产生的就是结果文件,那么reduce输出的key和value以什么分割的?其实就是制表符("\t")。所以toString()方法中我们也用这个
第二:实现计算每一年每个气象站的平均温度
import com.briup.bd1702.hadoop.mapred.utils.WeatherRecordParser;
import com.briup.bd1702.hadoop.mapred.utils.YearStation;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class AverageTemperatureByYearStationWithCombiner_0010 extends Configured implements Tool{
static class AvgTempByYSWithCombMapper extends Mapper{
private YearStation ys=new YearStation();
private AverageValue av=new AverageValue();
private WeatherRecordParser parser=new WeatherRecordParser();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
parser.parse(value);
if(parser.isValid()){
ys.set(parser.getYear(),parser.getStationId());
av.set(1,parser.getTemperature());
context.write(ys,av);
}
}
}
static class AvgTempByYSWithCombCombiner extends Reducer{
private AverageValue av=new AverageValue();
@Override
protected void reduce(YearStation key,Iterable values,Context context) throws IOException, InterruptedException{
int sum=0;
double count=0.0;
for(AverageValue av:values){
sum+=av.getNum().get();
count+=av.getAvgValue().get()*av.getNum().get();
}
av.set(sum,count/sum);
context.write(key,av);
}
}
static class AvgTempByYSWithCombReducer extends Reducer{
private DoubleWritable result=new DoubleWritable();
@Override
protected void reduce(YearStation key,Iterable values,Context context) throws IOException, InterruptedException{
int sum=0;
double count=0;
for(AverageValue av:values){
sum+=av.getNum().get();
count+=av.getAvgValue().get()*av.getNum().get();
}
result.set(count/sum);
context.write(key,result);
}
}
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output"));
Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.setMapperClass(AvgTempByYSWithCombMapper.class);
job.setMapOutputKeyClass(YearStation.class);
job.setMapOutputValueClass(AverageValue.class);
job.setCombinerClass(AvgTempByYSWithCombCombiner.class);
job.setReducerClass(AvgTempByYSWithCombReducer.class);
job.setOutputKeyClass(YearStation.class);
job.setOutputValueClass(DoubleWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00050_AverageTemperatureByYearStationWithCombiner_0010(),args));
}
}
-END-
