前言:
在MySQL中,比较常用的字符集是utf8和utf8mb4。这两个字符集是类似的,utf8是utf8mb3的别名,所以之后在MySQL中提到utf8就意味着使用1~3个字节来表示一个字符,如果大家有使用4字节编码一个字符的情况,比如存储一些emoji表情啥的,需要使用utf8mb4。其实每个字符集下对应着若干个比较规则(也可以翻译为排序规则或校对规则,英文是COLLATE),同一字符集下,使用不同的比较规则会影响字符字段的比较和排序。本文以utf8为例,介绍下常用的几个比较规则的不同。
1.utf8下比较规则概览
我们先查看下utf8字符集下支持的所有比较规则:
mysql> SHOW COLLATION LIKE 'utf8\_%';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 8 |
| utf8_icelandic_ci | utf8 | 193 | | Yes | 8 |
| utf8_latvian_ci | utf8 | 194 | | Yes | 8 |
| utf8_romanian_ci | utf8 | 195 | | Yes | 8 |
| utf8_slovenian_ci | utf8 | 196 | | Yes | 8 |
| utf8_polish_ci | utf8 | 197 | | Yes | 8 |
| utf8_estonian_ci | utf8 | 198 | | Yes | 8 |
| utf8_spanish_ci | utf8 | 199 | | Yes | 8 |
| utf8_swedish_ci | utf8 | 200 | | Yes | 8 |
| utf8_turkish_ci | utf8 | 201 | | Yes | 8 |
| utf8_czech_ci | utf8 | 202 | | Yes | 8 |
| utf8_danish_ci | utf8 | 203 | | Yes | 8 |
| utf8_lithuanian_ci | utf8 | 204 | | Yes | 8 |
| utf8_slovak_ci | utf8 | 205 | | Yes | 8 |
| utf8_spanish2_ci | utf8 | 206 | | Yes | 8 |
| utf8_roman_ci | utf8 | 207 | | Yes | 8 |
| utf8_persian_ci | utf8 | 208 | | Yes | 8 |
| utf8_esperanto_ci | utf8 | 209 | | Yes | 8 |
| utf8_hungarian_ci | utf8 | 210 | | Yes | 8 |
| utf8_sinhala_ci | utf8 | 211 | | Yes | 8 |
| utf8_german2_ci | utf8 | 212 | | Yes | 8 |
| utf8_croatian_ci | utf8 | 213 | | Yes | 8 |
| utf8_unicode_520_ci | utf8 | 214 | | Yes | 8 |
| utf8_vietnamese_ci | utf8 | 215 | | Yes | 8 |
| utf8_general_mysql500_ci | utf8 | 223 | | Yes | 1 |
+--------------------------+---------+-----+---------+----------+---------+
这些比较规则的命名还挺有规律的,具体规律如下:
- 比较规则名称以与其关联的字符集的名称开头。如上图的查询结果的比较规则名称都是以utf8开头的。
- 后边紧跟着该比较规则主要作用于哪种语言,比如
utf8_polish_ci表示以波兰语的规则比较,utf8_spanish_ci是以西班牙语的规则比较,utf8_general_ci是一种通用的比较规则。 - 名称后缀意味着该比较规则是否区分语言中的重音、大小写啥的,具体可以用的值如下:
| 后缀 | 英文释义 | 描述 |
|---|---|---|
_ai |
accent insensitive |
不区分重音 |
_as |
accent sensitive |
区分重音 |
_ci |
case insensitive |
不区分大小写 |
_cs |
case sensitive |
区分大小写 |
_bin |
binary |
以二进制方式比较 |
比如utf8_general_ci这个比较规则是以ci结尾的,说明不区分大小写
每种字符集都有一种默认的比较规则,SHOW COLLATION的返回结果中的Default列的值为YES的就是该字符集的默认比较规则,比方说utf8字符集默认的比较规则就是utf8_general_ci。
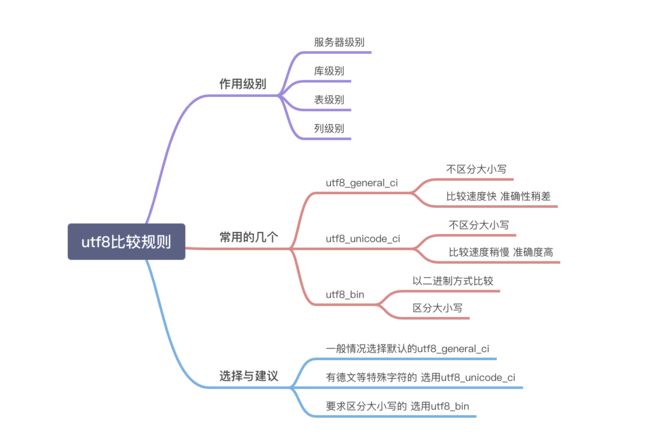
比较规则可以作用于四个级别,分别是:服务器级别、数据库级别、表级别、列级别。服务器级别的比较规则由collation_server参数控制,如果创建数据库、表、列时没有显式的指定比较规则,则会继承上一级的比较规则。下面给出创建及修改库、表、列的比较规则的示例语句:
# 创建数据库指定比较规则 修改数据库的比较规则
CREATE DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
ALTER DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
# 创建表时指定比较规则 修改表的比较规则
CREATE TABLE 表名 (列的信息)
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]]
ALTER TABLE 表名
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]
# 创建时指定列的比较规则 修改列的比较规则
CREATE TABLE 表名(
列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称],
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
2.几种比较规则对比
utf8字符集下默认的比较规则是utf8_general_ci,日常中会用到的有utf8_general_ci,utf8_unicode_ci,utf8_bin三种比较规则,其他比较规则基本很少会用,下面简单了解下这三种比较规则的异同。
首先utf8_bin的比较方法其实就是直接将所有字符看作二进制串,然后从最高位往最低位比对。所以很显然它是区分大小写的。而utf8_general_ci和utf8_unicode_ci是不区分大小写的。
utf8_general_ci和utf8_unicode_ci对中、英文来说没有实质的差别。utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß'等于‘ss'。utf8_general_ci是一个遗留的比较规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci比较规则进行的比较速度很快,但是与utf8_unicode_ci相比,比较正确性较差。
下面我们来实践下三种比较规则的异同:
# 创建表 指定列为不同的比较规则
mysql> create table utf8_test (
-> col_general varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci,
-> col_unicode varchar(20) CHARACTER SET utf8 COLLATE utf8_unicode_ci,
-> col_bin varchar(20) CHARACTER SET utf8 COLLATE utf8_bin
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 插入数据 每行数据各个字段值一样
mysql> select * from utf8_test;
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| MySQL | MySQL | MySQL |
| mysql | mysql | mysql |
| A | A | A |
| a | a | a |
| aA | aA | aA |
+-------------+-------------+---------+
# 查询 验证utf8_bin比较规则区分大小写
mysql> select * from utf8_test where col_general='mysql';
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| MySQL | MySQL | MySQL |
| mysql | mysql | mysql |
+-------------+-------------+---------+
mysql> select * from utf8_test where col_unicode='MySQL';
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| MySQL | MySQL | MySQL |
| mysql | mysql | mysql |
+-------------+-------------+---------+
mysql> select * from utf8_test where col_bin='mysql';
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| mysql | mysql | mysql |
+-------------+-------------+---------+
# 排序 发现不同排序规则对顺序有影响
mysql> select * from utf8_test order by col_general;
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| A | A | A |
| a | a | a |
| aA | aA | aA |
| MySQL | MySQL | MySQL |
| mysql | mysql | mysql |
+-------------+-------------+---------+
mysql> select * from utf8_test order by col_bin;
+-------------+-------------+---------+
| col_general | col_unicode | col_bin |
+-------------+-------------+---------+
| A | A | A |
| MySQL | MySQL | MySQL |
| a | a | a |
| aA | aA | aA |
| mysql | mysql | mysql |
+-------------+-------------+---------+
3.关于比较规则的选择与建议
对于MySQL 5.7版本,一般情况下建议将字符集改为utf8,比较规则选择默认的utf8_general_ci。utf8_general_ci相对于utf8_unicode_ci来说校对速度快,但是如果你的应用有德语、法语或者俄语,建议使用utf8_unicode_ci。如果某个表或列字段要求区分大小写,可以单独指定该表或字段使用utf8_bin比较规则
最后以思维导图的方式总结下本文的主要内容: