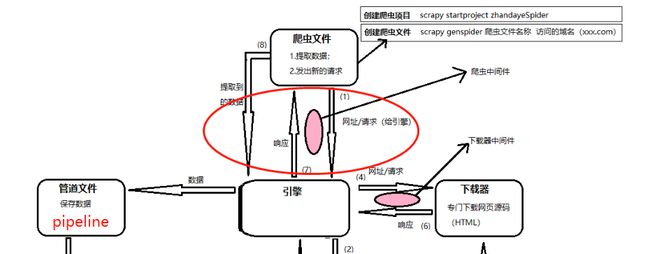

开始这一张之前需要先梳理一下这张图, 需要明白下载器中间件和爬虫中间件所在的位置
- 下载器中间件是在引擎(ENGINE)将请求推送给下载器(DOWNLOADER)时会执行到的
- 当下载器(DOWNLOADER)完成下载后, 将下载的Response对象传回给引擎(ENGLIE)时也会经过下载器中间件
- 当爬虫(SPIDER)把任务给引擎(ENGINE)的时候, 会经过爬虫中间件
- 当引擎(ENGINE)把数据传回给爬虫(SPIDER)的时候, 会经过爬虫中间件
所以, 下载器中间件是引擎和下载器之间处理数据所使用的, 爬虫中间件是爬虫和引擎之间处理数据时使用的
一、编写自己的爬虫中间件
编写一个简单的爬虫, 实现两个需求
- 将所有返回的Response(响应)的响应码改为500
- 统计解析出来的item的数量
# spider.py # -*- coding: utf-8 -*- import scrapy from ccidcom.items import CcidcomItem class CcidcomspiderSpider(scrapy.Spider): name = 'ccidcomSpider' def start_requests(self): self.logger.info('-----------spider.start_requests----------') yield scrapy.Request('http://www.ccidcom.com/yaowen/index.html') def parse(self, response): self.logger.info('--------spider.parse--------') article_list = response.css('div.article-item') for article in article_list: item = CcidcomItem() item['title'] = article.css('a font::text').get() item['url'] = response.url yield item def parse_baidu(self, response): pass # items.py import scrapy class CcidcomItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field()
编写爬虫中间件
# middlewares.py from scrapy import signals from ccidcom.items import CcidcomItem class CcidcomSpiderMiddleware(object): item_number = 0 ... def process_spider_input(self, response, spider): spider.logger.info('--------spider_input-----------') # 将响应码强制改为500 response.status = 500 return None def process_spider_output(self, response, result, spider): spider.logger.info('--------spider_output-start-----------') for i in result: if type(i) == CcidcomItem: self.item_number += 1 yield i spider.logger.info('--------spider_output-end-----------') spider.logger.info('item抓取到的数量:{}'.format(self.item_number)) def process_spider_exception(self, response, exception, spider): pass def process_start_requests(self, start_requests, spider): spider.logger.info('--------start_requests-----------') for r in start_requests: yield r ...
启用爬虫中间件
# settings.py SPIDER_MIDDLEWARES = { 'ccidcom.middlewares.CcidcomSpiderMiddleware': 543, }
执行的顺序
- 1.爬虫中间件的
process_start_requests方法 - 2.爬虫的
start_requests方法 - 3.爬虫中间件的
process_spider_input方法 - 4.爬虫中间件的
process_spider_output方法 - 5.爬虫的
parse方法 - 6.爬虫中间件的
process_spider_output方法
好像有点乱, 为啥process_spider_output会被运行了两次呢?而且还是第一次只输出了spider_output-start, 最后才输出了spider_output-end?
其实咱们跟着代码走一遍,就很好理解了
- 代码执行到了爬虫中间件的
process_start_requests方法, 输出了start_requests, 但是参数start_requests其实是spider的start_requests方法的生成器, 所以只有执行到for r in start_requests, 才真正开始执行spider的start_requests方法 - 交给下载器完成下载
- 下载后引擎将Response传给爬虫中间件的
process_spider_input方法 process_spider_input方法会调用process_spider_output方法, 并且将发起请求时Request的callback指定的方法, 变为process_spider_output的result参数, 这时也输出了spider_output-start- 当
process_spider_output方法运行到for i in result:时, 则真正开始执行Request对象指定的callback方法, 并且变为了生成器, yield回引擎 - 当
process_spider_output执行完result后, 就输出了spider_output-end.
以上就是整个爬虫中间件的运行流程。
# middlewares.py
from scrapy import signals
from ccidcom.items import CcidcomItem
class CcidcomSpiderMiddleware(object):
item_number = 0
...
def process_spider_input(self, response, spider):
spider.logger.info('--------spider_input-----------')
# 将响应码强制改为500
response.status = 500
return None
def process_spider_output(self, response, result, spider):
spider.logger.info('--------spider_output-start-----------')
for i in result:
if type(i) == CcidcomItem:
self.item_number += 1
yield i
spider.logger.info('--------spider_output-end-----------')
spider.logger.info('item抓取到的数量:{}'.format(self.item_number))
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
spider.logger.info('--------start_requests-----------')
for r in start_requests:
yield r
...