同本文一起发布的另外一篇文章中,提到了 BlueDot 公司,这个公司致力于利用人工智能保护全球人民免受传染病的侵害,在本次疫情还没有引起强烈关注时,就提前一周发出预警,一周的时间,多么宝贵!
他们的 AI 预警系统,就用到了深度学习对文本的处理,这个系统抓取网络上大量的新闻、公开声明等获取到的数十万的信息,对自然语言进行处理,我们今天就聊聊深度学习如何对文本的简单处理。
文本,String 或 Text,就是字符的序列或单词的序列,最常见的是单词的处理(我们暂时不考虑中文,中文的理解和处理与英文相比要复杂得多)。计算机就是固化的数学,对文本的处理,在本质上来说就是固化的统计学,这样采用统计学处理后的模型就可以解决许多简单的问题了。下面我们开始吧。
处理文本数据
与之前一致,如果原始要训练的数据不是向量,我们要进行向量化,文本的向量化,有几种方式:
- 按照单词分割
- 按照字符分割
- 提取单词的 n-gram
我喜欢吃火……,你猜我接下来会说的是什么?1-gram 接下来说什么都可以,这个词与前文没关系;2-gram 接下来可能说“把,柴,焰”等,组成词语“火把、火柴、火焰”;3-gram 接下来可能说“锅”,组成“吃火锅”,这个概率更大一些。先简单这么理解,n-gram 就是与前 n-1 个词有关。
我们今天先来填之前挖下来的一个坑,当时说以后将介绍 one-hot,现在是时候了。
one-hot 编码
def one_hot():
samples = ['The cat sat on the mat', 'The dog ate my homework']
token_index = {}
# 分割成单词
for sample in samples:
for word in sample.split():
if word not in token_index:
token_index[word] = len(token_index) + 1
# {'The': 1, 'cat': 2, 'sat': 3, 'on': 4, 'the': 5, 'mat.': 6, 'dog': 7, 'ate': 8, 'my': 9, 'homework.': 10}
print(token_index)
max_length = 8
results = np.zeros(shape=(len(samples), max_length, max(token_index.values()) + 1))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
index = token_index.get(word)
results[i, j, index] = 1.
print(results)

我们看到,这个数据是不好的,mat 和 homework 后面都分别跟了一个英文的句话 '.',要炫技写那种高级的正则表达式去匹配这个莫名其妙的符号吗?当然不是了,没错,Keras 有内置的方法。
def keras_one_hot():
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(samples)
sequences = tokenizer.texts_to_sequences(samples)
print(sequences)
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
print(one_hot_results)
word_index = tokenizer.word_index
print(word_index)
print('Found %s unique tokens.' % len(word_index))

这里的 num_words 和上面的 max_length 都是用来表示多少个最常用的单词,控制好这个,可以大大的减少运算量训练时间,甚至有点时候能更好的提高准确率,希望引起一定注意。我们还可以看到得到的编码的向量,很大一部分都是 0,不够紧凑,这会导致大量的内存占用,不好不好,有什么什么其他办法呢?答案是肯定的。
词嵌入
也叫词向量。词嵌入通常是密集的,维度低的(256、512、1024)。那到底什么叫词嵌入呢?
本文我们的主题是处理文本信息,文本信息就是有语义的,对于没有语义的文本我们什么也干不了,但是我们之前的处理方法,其实就是概率上的统计,,是一种单纯的计算,没有理解的含义(或者说很少),但是考虑到真实情况,“非常好” 和 “非常棒” 的含义是相近的,它们与 “非常差” 的含义是相反的,因此我们希望转换成向量的时候,前两个向量距离小,与后一个向量距离大。因此看下面一张图,是不是就很容易理解了呢:
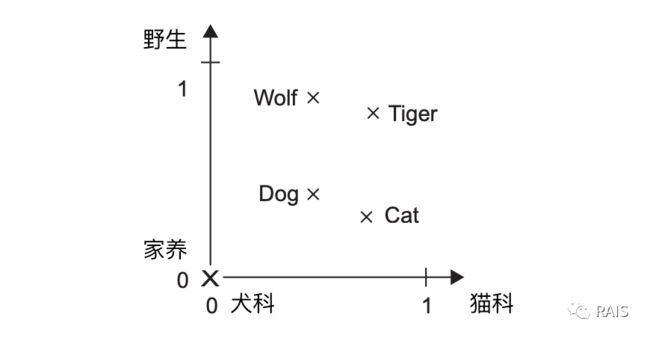
可能直接让你去实现这个功能有点难,幸好 Keras 简化了这个问题,Embedding 是内置的网络层,可以完成这个映射关系。现在理解这个概念后,我们再来看看 IMDB 问题(电影评论情感预测),代码就简单了,差不都可以达到 75%的准确率:
def imdb_run():
max_features = 10000
maxlen = 20
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
model = Sequential()
model.add(Embedding(10000, 8, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
我们的数据量有点少,怎么办呢?上一节我们在处理图像的时候,用到的方法是使用预训练的网络,这里我们采用类似的方法,采用预训练的词嵌入。最流行的两种词嵌入是 GloVe 和 Word2Vec,我们后面还是会在合适的时候分别介绍这两个词嵌入。今天我们采用 GloVe 的方法,具体做法我写在了代码的注释中。我们还是先看结果,代码还是放在最后:
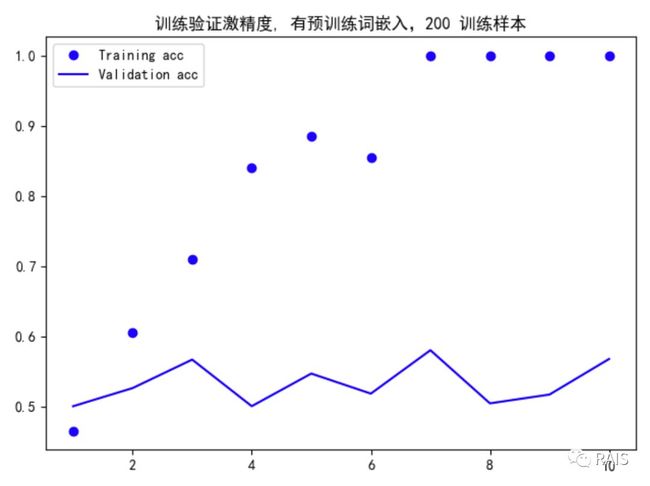
很快就过拟合了,你可能觉得这个验证精度接近 60%,考虑到训练样本只有 200 个,这个结果真的还挺不错的,当然,你可能不信,那么我再给出两组对比图,一组是没有词嵌入的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uem4R2hO-1583414769394)(https://upload-images.jianshu.io/upload_images/2023569-23b0d32d9d3db11d?imageMogr2/auto-orient/strip|imageView2/2/w/1240)]
验证精度明显偏低,再给出 2000 个训练集的数据:

这个精度就高了很多,追求这个高低不是我们的目的,我们的目的是说明词嵌入是有效的,我们达到了这个目的,好了,接下来我们看看代码吧:
#!/usr/bin/env python3
import os
import time
import matplotlib.pyplot as plt
import numpy as np
from keras.layers import Embedding, Flatten, Dense
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
def deal():
# http://mng.bz/0tIo
imdb_dir = '/Users/renyuzhuo/Documents/PycharmProjects/Data/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
# 读出所有数据
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
# 对所有数据进行分词
# 每个评论最多 100 个单词
maxlen = 100
# 训练样本数量
training_samples = 200
# 验证样本数量
validation_samples = 10000
# 只取最常见 10000 个单词
max_words = 10000
# 分词,前文已经介绍过了
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# 将整数列表转换成张量
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# 打乱数据
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
# 切割成训练集和验证集
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
# 下载词嵌入数据,下载地址:https: // nlp.stanford.edu / projects / glove
glove_dir = '/Users/renyuzhuo/Documents/PycharmProjects/Data/glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
# 构建单词与其x向量表示的索引
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
# 构建嵌入矩阵
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# 构建模型
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
# 将 GloVe 加载到 Embedding 层,且将其设置为不可训练
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
# 训练模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
# 画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
if __name__ == "__main__":
time_start = time.time()
deal()
time_end = time.time()
print('Time Used: ', time_end - time_start)
本文首发自公众号:RAIS