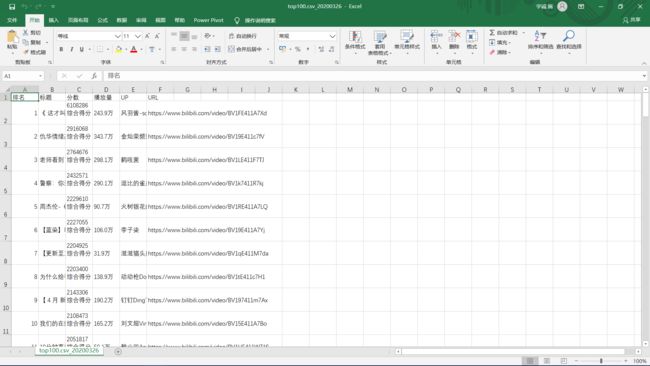
#哔哩哔哩每日热榜 #网页链接:https://www.bilibili.com/ranking? import requests from bs4 import BeautifulSoup #发出request请求,获取html网页 url = 'https://www.bilibili.com/ranking?' kv = {'user-agent': 'Mozilla/5.0'}#伪装爬虫 r = requests.get(url,timeout = 30,headers=kv) r.text#获取源代码 html=r.text #解析网页,提取内容 soup=BeautifulSoup(html,'lxml')#构造Soup的对象 res = soup.find_all('a',class_='title') num = 0 text = '' for i in res: num+=1 text+='{}{}\n'.format(num,i.string)#先把内容保存到变量里去 print(text) #保存 with open('rank.text','w',encoding='utf8')as fout: fout.write(text)
2020.3.26
import requests
from bs4 import BeautifulSoup
import csv
import datetime
url = 'https://www.bilibili.com/ranking?'
#发起网络请求
response = requests.get(url)
html_text = response.text
soup = BeautifulSoup(html_text,'html.parser')
def main():
#用来保存视频信息的对象
class Video:
def __init__(self,rank,title,point,visit,up,url):
self.rank = rank
self.title = title
self.point = point
self.visit = visit
self.up = up
self.url = url
def to_csv(self):
return [self.rank,self.title,self.point,self.visit,self.up,self.url]
@staticmethod
def csv_title():
return ['排名','标题','分数','播放量','UP','URL']
#提取列表
items = soup.find_all('li',{'class':'rank-item'})
videos = [] #保存提取出来的video
for itm in items:
title = itm.find('a',{'class':'title'}).text#标题
point = itm.find('div',{'class':'pts'}).text#综合得分
rank = itm.find('div',{'class':'num'}).text#排名
visit = itm.find('span',{'class':'data-box'}).text#播放量
up = itm.find_all('a',)[2].text#up
url = itm.find('a',{'class':'title'}).get('href')#获取链接
v = Video(rank,title,point,visit,up,url)
videos.append(v)
#保存
now_str = datetime.datetime.now().strftime('%Y%m%d')
file_name = f'top100.csv_{now_str}.csv'
with open(file_name,'w',newline='') as f:
writer = csv.writer(f)
writer.writerow(Video.csv_title())
for v in videos:
writer.writerow(v.to_csv())
1.打开网页
2.获取源代码
3.解析网页,提取需要的内容,先找第一名的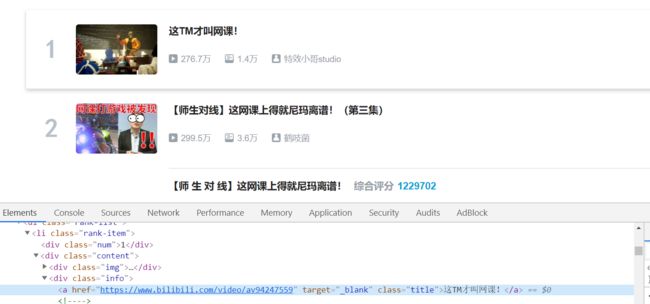
这里找到需要提取的标题a标签,分析特点,它的类是title,在代码中可以用find_all函数查找
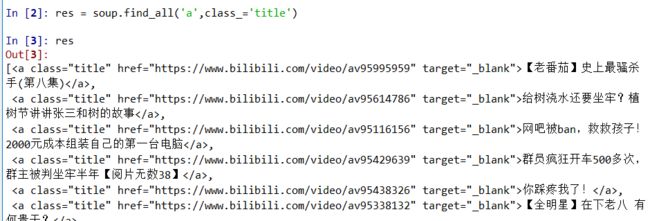
发现成功将排行榜爬取下来,想到可以用for循环把结果一个个打印出来

因为内容都是按顺序排下来的,所以可以自己弄数字形成排名

然后把内容保存到一个变量里去并检查有没有正常保存

最后直接保存到文件里面去,创建一个rank.txt,以写入的方式打开,把它赋值到fout这个变量里,fout写入获取到的文本内容

获取数据截图